






CNN-RNN: A Unified Framework for Multi-label Image Classification
Updated on 2018-08-07 22:30:41
本文提出了一种 model 多标签之间关系的一种模型,即:CNN-LSTM 模型。
我认为该模型的想法来自于 Image Caption的常规套路。
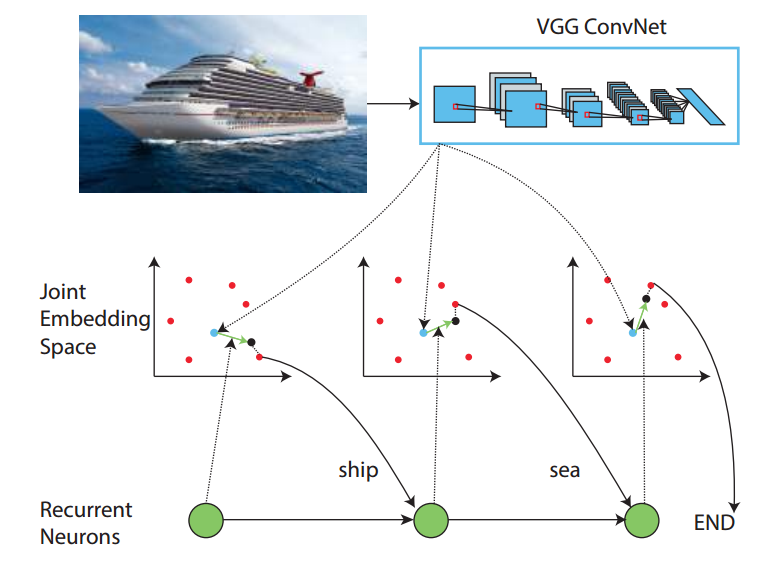
上图就是本文的流程图,可以看到,类似 Image Caption的思路,本文首先利用 CNN 对输入的图像进行编码,得到其特征;
然后将其进行 embedding,投影到和单词一致的空间中,在该空间中,利用 LSTM 进行单词的搜索训练。然后测试的时候,利用 beam search 进行搜索,得到的单词,就是对应该图像的标签。
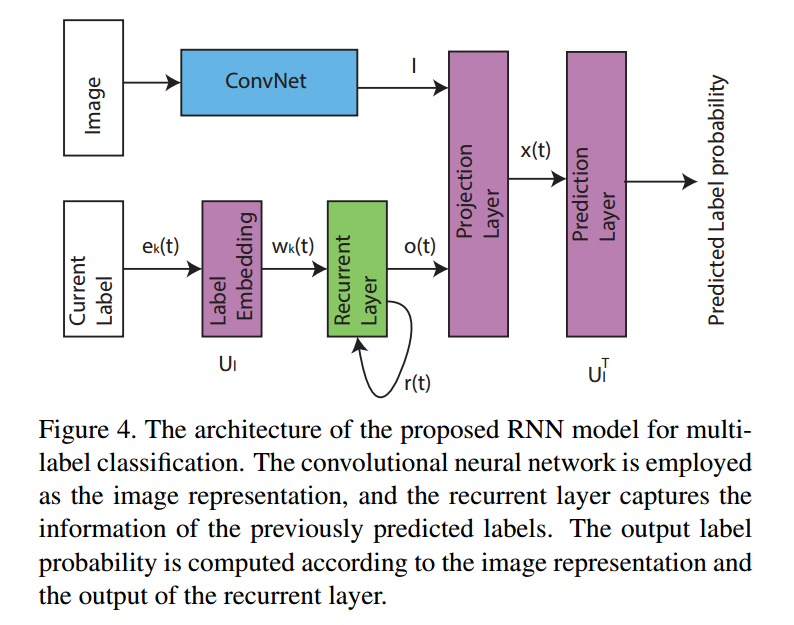
实验部分的一些现象:
1. 本文算法在大目标 和 具有依赖性的物体上,识别效果比较好,如:行人,斑马;“sports bar” 和 “baseball glove”;
而在小目标 和 不具有依赖性的物体上,则表现较差,如:“toaster” 和 “hair drier”。















 8762
8762











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









