






动态规划的概念
动态规划算法把原问题视作若干个重叠子问题的逐层递进,每个子问题的求解过程都构成了一个“阶段”。在完成前一个阶段的计算后,动态规划才会执行下一个阶段的计算。
为了保证这些计算能够按顺序,不重复的进行,动态规划要求子问题不受后续阶段的影响,即:后续阶段的变化不会引起当前阶段求解的变动,换句话说是:过程的历史只能通过当前的状态去影响它的未来的发展,这个性质称为无后效性。
注意注意....拜托运筹学玩家别来OI纠错...真的,别说什么以前的状态也不能影响当前的....OI里的始点都是确定的怎么影响啊!
换言之,动态规划对状态空间的遍历构成了一张有向无环图,遍历顺序就是该有向无环图的一个拓扑序。有向无环图图中的节点对应动态规划的每一个状态,图中的边则对应状态之间的转移,转移的选取就是动态规划的“决策”。
在很多情况下,动态规划用于求解最优化问题。此时,下一阶段的最优解应该能够由前面各阶段子问题的最优解导出。这个条件被称为“最优子结构性质”。但这只是一种片面说法。它其实告诉我们,动态规划在阶段计算完成时,只会在每个状态上保留与最终解集相关的部分代表信息,这些代表信息应该有可重复的求解过程,并能够导出后续阶段的代表信息。这样一来,动态规划对状态的抽象和子问题的重叠递进才能够起到优化作用
“状态”“阶段”和“决策”时构成动态规划算法的三要素,而“子问题重叠性”“无后效性”和“最优子结构性质”是问题能使用动态规划求解的三个基本条件
动态规划算法把相同的计算过程作用于各阶段的同类子问题,就好像把一个固定的公式在格式相同的若干输出数据上进行。因此,我们一般只需要定义dp的计算过程,就可以进行编程实现。这个过程被称为“状态转移方程”。
线性DP
例题*1:
Mobile Service
一个公司有三个移动服务员,最初分别在位置1, 2, 3处
如果某个位置(用一个整数表示)有一个请求,那么公司必须指派某名员工赶到那个地方去。某个时刻只有一个员工能移动,且不允许在同样的位置出现两个员工。从p到q移动一个员工,需要花费c(p, q)。这个函数不一定对称,但保证c(p, p) = 0
给出n个请求,请求发生的位置分别为p1~pn。公司必须按顺序依次满足所有请求,目标是最小化公司花费,请帮助计算这个最小花费。N <= 1000, 位置是1~ 200的整数
划分阶段:假设要完成第i个任务,我们只需要考虑的是当前职员所在的位置
通过指派一名服务员,我们可以把状态从 完成i - 1个请求转移到完成i个请求
所以阶段就是“完成任务的数量”
为了计算服务员的花费,我们已知每个服务员的起始位置,最直接的想法是:将三个服务员放在“状态中”
f[i, x, y, z]
完成了前i个请求,服务员分别位于x, y, z是,公司的最小花费
考虑状态转移,显然有三种,就是派三个服务员中的一个去第i + 1个位置
f[i+1, pi+1, y, z] = min(f[i+1, pi+1, y, z], f[i, x, y, z] + c(x,pi+1));
f[i+1, x, pi+1, z] = min(f[i+1, x, pi+1, z], f[i, x, y, z] + c(y,pi+1));
f[i+1, x, y, pi+1] = min(f[i+1, x, y, pi+1], f[i, x, y, z] + c(z,pi+1));
分析算法规模,状态数为1000 * 200^3,不能承受。
仔细观察可发现,在完成第i个请求时,一定有某个员工位于位置pi,只需要阶段i个另外两个员工的位置x,y(注意并不是员工x和y)即可描述状态,处于pi的员工对DP来说是冗余信息
因此,我们就可以用f[i, x, y]来表示完成前i个请求时,其中一个员工位于pi,另外两个员工分别位于x,y时,公司的最小花费
f[i+1,x,y] = min(f[i+1,x,y],f[i,x,y] + c(pi,pi+1));
f[i+1,pi,y] = min(f[i+1,pi,y],f[i,x,y] + c(x,pi+1));
f[i+1,x,pi] = min(f[i+1,x,pi],f[i,x,y] + c(y,pi+1));
设p3 = 0,于是初值可设为p[0,1,2] = 0,目标为p[n,?,?]
启发:
1.求解线性dp问题,一般想确定“阶段”。若“阶段”不足以表示一个状态,则可以把所需的附加信息也作为状态的维度
在转移时,若总是从一个阶段转移到下一个阶段(本题i到i+1),则没有必要关心附加信息维度的大小变化情况(本题x,y,z在转移前后大小不定),因为无后效性已经有“阶段”保证
2.在确定DP状态时,要选择最小的能够覆盖空间的“维度集合”。
若DP状态有多个维度构成,则应检查这些维度之间能否相互导出,用尽量少的维度覆盖整个状态空间,排除冗余维度。
例题*2:
noip2008 传纸条

简单说就是
一个m行n列的矩阵,每行有一个整数,找到两条从左上角(1,1)到右下角(m,n)的路径,每次只能向下或是向右走,每次走到的格子上的数会被取走,求取得的数的和最大是多少 n, m <= 50
阶段划分:从左上角到右下角,以走的步数为阶段,每向下一个阶段,两条路径同时向后扩展1,思考如何进行阶段的转移
似乎这样并不能得到什么,我们还需要知道路径在当前阶段的终点(x1,y1)和(x2,y2)
试图用f[i,x,y]来覆盖整个状态空间,检查是否能相互推导出,
我们发现x1+y1 = x2+y2 = i+2
可以相互推导出,故可以作为一个状态
但是再思考后发现,f[i,x,y]中,若为x,y,那么x,y只能描述一条路径的结束点的位置
由上述推导,我们似乎可以得到这样的关系,y1=i+2-x1,y2=i+2-y2
我们把状态由一条路径走了i步到达的位置改为两条路径走了i步到达的位置,即:
用f[i,x1,x2]来覆盖整个状态空间
方程参照Mobile Service似乎很容易导出?
当x1 = x2,并且y1+1=y2+1时,
<1>f[i+1,x1,x2] = max{f[i+1,x1,x2], f[i,x1,x2] + a[x1,y1+1]};
当y1 = y2,并且x1+1=x2+1时
<2>f[i+1,x1+1,x2+1] = max{f[i+1,x1+1,x2+1],f[i,x1,x2] + a[x1+1,y1]};
以上两种情况,第一种情况向右扩展时,两条路径将进入同一个格子
第二种情况向下扩展时,两条路径将进入同一个格子
否则两条路径进入不同格子,分别进行计算,将两个格子里的数都进行累加
1.f[i+1,x1,x2] = max{f[i+1,x1,x2],f[i,x1,x2]+a[x1,y1+1]+a[x2,y2+1]};
2.f[i+1,x1,x2] = max{f[i+1,x1,x2],f[i,x1,x2]+a[x1+1,y1]+a[x2+1,y2]};
3.f[i+1,x1,x2] = max{f[i+1,x1,x2],f[i,x1,x2]+a[x1+1,y1]+a[x2,y2+1]};
4.f[i+1,x1,x2] = max{f[i+1,x1,x2],f[i,x1,x2]+a[x1,y1+1]+a[x2+1,y2]};
分别扩展4种情况,当两条路径都向右时,都向下时,一条向右一条向下时
注:当<1><2>满足时,则1,2不进行计算
但这只是完整了一个思路,最好是我们由前一个状态更新当前状态,而不是用当前状态一个状态更新后一个状态
当然是因为这样好写,关键是我写挂了一次......
#include<bits/stdc++.h>
#define l 60
using namespace std;
int n, m, add;
int a[l][l], f[l * 2][l][l];
//bool f1 = 0, f2 = 0;
inline int read() {
int x = 0, y = 1;
char ch = getchar();
while(!isdigit(ch)) {
if(ch == '-') y = -1;
ch = getchar();
}
while(isdigit(ch)) {
x = (x << 1) + (x << 3) + ch - '0';
ch = getchar();
}
return x * y;
}
int main() {
int k, i, j;
m = read(), n = read();
for(int i = 1; i <= m; ++i)
for(int j = 1; j <= n; ++j)
a[i][j] = read();
int len = n + m;
f[2][1][1] = 0;
for(k = 3; k <= len; ++k)
for(i = 1; i <= min(m, k - 1); ++i)
for(j = 1; j <= min(m, k - 1); ++j) {
/*int x1 = i, x2 = j, y1 = k - x1, y2 = k - x2, s= f[k][i][j];
if(x1 == x2 && y1 + 1== y2 + 1) {
f[k + 1][x1][x2] = max(f[k + 1][x1][x2], s + a[x1][y1 + 1]);
f1 = 1;
}
if(y1 == y1 && x1 + 1 == x2 + 1) {
f[k + 1][x1 + 1][x2 + 1] = max(f[k + 1][x1 + 1][x2 + 1], s + a[x1 + 1][y1]);
f2 = 1;
}
if(!f1) f[k + 1][x1][x2] = max(f[k + 1][x1][x2], f[k][x1][x2] + a[x1][y1 + 1] + a[x2][y2 + 1]);
if(!f2) f[k + 1][x1 + 1][x2 + 1] = max(f[k + 1][x1 + 1][x2 + 1], f[k][x1][x2] + a[x1 + 1][y1] + a[x2 + 1][y2]);
f[k + 1][x1 + 1][x2] = max(f[k + 1][x1 + 1][x2], f[k][x1][x2] + a[x1 + 1][y1] + a[x2][y2 + 1]);
f[k + 1][x1][x2 + 1] = max(f[k + 1][x1][x2 + 1], f[k][x1][x2] + a[x1][y1 + 1] + a[x2 + 1][y2]);
f1 = 0, f2 = 0;*/
if (i == j) add = a[i][k - i];//x1 == x2时是同一个位置, 只计算一次
else add = a[i][k - i] + a[j][k - j];
f[k][i][j] = max(f[k - 1][i][j], f[k][i][j]);
f[k][i][j] = max(f[k - 1][i - 1][j - 1], f[k][i][j]);
f[k][i][j] = max(f[k - 1][i][j - 1], f[k][i][j]);
f[k][i][j] = max(f[k - 1][i - 1][j], f[k][i][j]);
f[k][i][j] += add;
}
cout << f[len][m][m] <<'\n';
return 0;
}
zbw关于DP的一波讲解
(zbw是dalao,ywj是我这个小鶸鷄....)
Zbw:给dp下一个定义,随便说,这个问题没有什么标准答案
Ywj:把问题划分为一个一个的阶段,然后完成前一个阶段,再求解下一个阶段??
Zbw:对,现在换一个角度来观察一下,这个阶段是怎么分出来的
Zbw:比如说,数字三角形问题,定义f(i, j)表示从第i行第j列出发,到达底层的最大收益如果是搜索,你怎么做的
Zbw:我要知道f(i, j),我考虑我是走到i,j还是i, j + 1.于是dfs(x, y) RET min(dfs(x, y), dfs(x, y + 1)) + v[x][y]
Zbw:这样写会跑的非常慢,分析一下他效率低的原因?
Ywj:重复计算?
Zbw:巨量的重复计算QWQ
Zbw:所以我们应该怎么优化这个搜索?
Ywj:记忆化搜索。
Zbw:所以DP其实就是对一个多阶段决策进程,进行一部分决策之后得到的不同情况中
Zbw:你可以把这些情况分成若干个部分,可以证明,或是显然这些情况继续决策下去的答案是相同的
Zbw:那么你就没有必要把这每种情况考虑一遍
Zbw:数字三角形这个问题比较直接,它的情况相同直接就是重复计算,虽然你走到某一点的走法不同,但是既然走到同一点,之后的最大收益肯定是相同的
Zbw:你要把所有的决策用几个信息划分成几类,每一类的答案都必然相同,你就可以把你划分的每一个等价类称为是一个状态
Zbw:而在很多问题中,一个状态可以用你用的几个信息来描述。然后就变成了dp[][][]…的形式
Zbw:
Zbw:看一下这个问题
,假设我是在搜索,当前是某一种搜索到的情况,目前搜了前i个点
Zbw:设前i个数是B1,B2,B3….Bi,继续搜索下去,后面的决策的唯一限制是Bi+1>=Bi,也就是说后面的决策与B1…Bi-1无关
Zbw:所以你只需关心Bi,状态就可以表示为:搜了前i个,最后一个数是什么,(最后一个数就是j)
Zbw:在i和j相投的情况下,你搜到的不同决策,最后答案都会是一样的,虽然他们是不同的决策,但是没有重复计算的意义于是你就可以dp[i][j]表示前j个数,最后一个Bi是j
Zbw:然后把这个dp数组当成vis数组,记忆化搜索,到这里懂吧
Ywj:嗯
Zbw:问题:为什么DP往往是几个循环然后在里面递推的形式?
Zbw:dp一个非常重要的问题就是顺序,(dp有两种方式push和pull
Zbw:push就是我们可以在走到状态A的时候枚举后一个后继状态,然后更新后继状态。
Zbw:比如说:dp[i+1][j]=max(dp[i+1][j],dp[i][j]+w[i][j]) 这样
Zbw:pull就是你要计算一个状态的时候,去找所有能够转移到他的状态
Zbw:dp[i][j]=max(dp[i-1][j],dp[i-1][j-1])+w[i][j]
Zbw:能理解吧
Ywj:嗯
Zbw:(很多是push比较简单粗暴好想。
Zbw:我们考虑pull。其实push是一样的,如果状态A能够转移到状态B,那么计算状态B之前一定要计算状态A,实际上,如果我们把每一个状态看成节点,转移关系看成有向边
Zbw:我们就会得到一个DAG(有向无环图),QWQ,能理解吗QWQ
Ywj:能
Zbw:你的dp顺序可以使这个图的任意一个拓扑序,当状态转移图没有明显的拓扑序时可以想直接for的时候往往记忆化搜索,如果有明显的拓扑序,比如dpi*只会连到dpi+1*,那么你就可以用一个数组来for
Zbw:实际上你for循环的时候转移顺序就是一个拓扑序
Ywj: 
这个可以举一个例子吗。。?
Zbw:我找一下,我找一个简单粗暴的例子…..
Zbw:DAG上dp,QWQ,比如说求DAG最长路,当然你也可以找出一个顺序,你只需要求出拓扑序即可,但是我觉得记忆化搜索还是方便,还有就是状压dp,有时候很难找简单的dp顺序
…..(充分显示我有多鶸,感谢zbw帮我打通dp思考的思路(至少线性dp要稳多了
例题*3
I-country(SGU167)
在n*m的矩阵中,每个格子有一个权值,要求需要一个包含k个格子的凸连通块(联通块中间没有空缺,并且轮廓是凸的),使这个连通块的格子的权值和最大。求这个最大的权值和、
任何一个凸连通块可以划分成连续的若干行,每行的左端点列号先递减后递增,右端点列号先递增后递减,并求出连通块的具体方案
思考阶段如何划分:
由已经处理的行数向下扩展,但是仅有行数我们无法描述状态空间
那我们再加入已经选过的格子数,这样我们似乎可以确定我们已经完成了多少行,哪些格子已经选过
但是这是凸连通块,我们靠以上两个信息还远远不够
那么我们想一想如何使阶段转移完成后最终得到的是凸连通块,再加入什么信息?
我们可以再加入每行的左端点和右端点,确定下一行端点的范围,以满足单调性
那么我们还可以再加入轮廓的单调类型
加起来5维
f[i,j,l,r,x,y]
表示前i行,选了j个格子,其中第i行选了第l到r的格子,左轮廓的单调性是x,右轮廓的单调性是r时,能构成的凸连通块的最大权值和
行数和格子数可以作为dp的“阶段”,每次转移到下一行,同时选出的格子递增,符合“阶段线性增长”的特点
然后我们会发现,我们在进行状态转移的时候,需要第i行中l到r的区间和,显然边转移边计算需要不低的复杂度,于是我们可以预处理出表示每一行的前缀和数组A,这样在计算时,l到r的区间和就可以表示为A[i][r]-A[i][l],在转移结束时,再定义两个变量p,q,表示当前行的左端点l和右端点r
然后我们来写一下状态转移方程试试:
根据我们的分析,我们可以得到4种可能状态://1表示递减,0表示递增
1.左边界列号递减,右边界列号递增(两边界都处于扩张状态)
f[i,j,l,r,1,0] = A[i][r]-A[i][l] + max{f[i-1,j-(r-l+1),p,q,1,0]};//j>r-l+1>0
` = A[i][r]-A[i][l] + max{f[i-1,0,0,0,1,0]};//j=r-l+1>0
2.左右边界列号都递减(左边界扩张,右边界收缩)
f[i,j,l,r,1,1] = A[i][r]-A[i][l] + max{max{f[i-1,j-(r-l+1),p,q,1,y]}(0<=y<=1)}
3.左右边界列号都递减(左边界收缩,右边界扩张)
f[i,j,l,r,0,0] = A[i][r]-A[i][l] + max{{f[i-1,j-(r-l+1),p,q,x,0](0<=x<=1)}}
4.左边界列号递增,右边界列号递减(两边界都处于收缩状态)
f[i,j,l,r,0,1] = A[i][r]-A[i][l] + max{max{max{f[i-1,j-(r-l+1),p,q,x,y]}(0<=y<=1)}(0<=x<=1)}(p<=l<=r<=q)
对于2,3,4的max嵌套max,可能有点难以理解
我们来想一下,我们要进行收缩,那么我们这个收缩的状态是怎么得来的?
答:由上一行扩张或收缩而来
所以当收缩右边界时,我们先比较的是上一行右边界标记扩张和右边界标记收缩的最大值,再和当前行比较
左边界收缩时同理。
这样我们就能推出2和3。
进而我们想4这种情况。
左右边界同时进行收缩,我们就要嵌套3次,先由上述确定右边界状态,再由已确定右边界状态来确定左边界状态,最后由已确定的左边界状态和右边界状态来确定当前行
//此处状态单指标记为收缩或扩张,即上一行的左/右边界由上上一行的左/右边界扩张或收缩得到
本题还要求输出方案。
在动态规划需要给出方案时,通常做法是额外使用一些与DP状态大小相同的数组记录下来每个状态的“最优解”是从何处转移而来的。最终,在DP求出最优解后,通过一次递归,沿着记录的每一步“转移来源”回到初态,得到一条从初态到最优解的转移路径,也就是所求的具体方案
例题
Cookies*4
圣诞老人共用有个饼干,准备全部分给N个孩子。每个孩子有一个贪婪度,第i个孩子的贪婪度为g[i]。如果有a[i]个孩子拿到的饼干数比第i个孩子多,那么第i个孩子会产生g[i]*a[i]的怨气。给定N,M和序列g,圣诞老人请你帮他安排一种分配方式,使得每一个孩子至少分到一块饼干,并且所以孩子的怨气总和最小。1<=N<=30,N<=M<=5000
每个孩子的怒气值与其他孩子获得的饼干数量相关联
emmm似乎很难对状态进行划分得到“子结构”,也很难计算
出每个孩子的怒气值
仔细(简单?)思考后我们发现,贪婪度大的孩子应该得到更多的饼干,因此首先可以把孩子的贪婪度从大到小,孩子得到饼干的数量将是单调递减的
设f[i,j]表示前i个孩子一个分配了j块饼干时,怒气值总和的最小值,直观的思考是考虑分配给第i+1个孩子多少饼干,然后进行转移。
转移时有两种情况:
1.当前孩子的贪婪度比下一个孩子大,即:第i个孩子的饼干数比第i+1个孩子多,a[i+1]=i;
2.当前孩子的贪婪度与下一个孩子一样,即:第i个孩子的饼干数与第i+1个孩子一样,那么这时我们还需要知道前i个孩子中有多少个获得饼干数与第i个孩子相同才能求出a[i+1]
总而言之,无论哪种情况,我们都需要知道第i个孩子获得的饼干数,以及i前面有多少个孩子与i获得的饼干数相同,然而在现有DP状态下,很难高效维护这两个信息,虽然不是没法维护,比如我们添加两个维度去记录,那是那样我们要多大的数组?四维数组,极限一共30个孩子,5000块饼干,30*5000*30^2,135000000,10位数的总空间,显然没法写。
不扩维呢,我们需要多开数组,似乎并非不可写?我们似乎确实可以做得到,但是我们对于每个孩子获得多少饼干似乎并没办法得到实现,或者实现麻烦(我懒得想了qwq)
那么我们不妨对状态转移做一个等价交换,
1.若第i个孩子获得的饼干数大于1,则等价于分配j-i个饼干给前i个孩子,也就是说平均每个孩子都少分一块饼干,获得饼干数的相对大小顺序不变,从而怨气和也不变
2.若第i个孩子获得的饼干数为1,枚举i前面有多少个孩子也获得1块饼干
想想为什么能这样,我们在第i个孩子那,用j-i的方式强行使前i个孩子每个人获得的饼干都少了1,那么这样不断-1-1-1-1...下去,肯定会出现到最后只获得了1块的情况,由1状态可知,这样操作下去并不会是结果有任何变化,所以2状态并不会对结果产生影响,这样我们也就能得到状态转移方程
i
f[i,j] = min{f[i,j-i], min{f[k,j-(i-k)] + k * Σg[p]}(0<=k<i)]}
p=k+1
i
对min中嵌套的min,我们先挨个枚举k,f[k,j-(i-1)]表示到第k个孩子,共分了j-(i-k)块饼干。k*Σg[p]则表示假设从第k
p=k+1
个孩子向后获得的饼干数都相同,总的怨气和,这样一遍后,我们得到加入i之前有和i获得饼干相等的情况,所能得到的最小怨气和,然后再与i之前没有孩子与i获得饼干数相等的情况所需的怨气和,就能得到第i个孩子得到第j个饼干并且怨气和最小结果
初态:f[0][0],末态:f[n,m]
分析一下,O(nmk)(0<=k<i),加上n和k的范围极大的小于m,m也仅有5000,可写
这道题启发我们,有时可以通过额外的算法确定DP计算顺序,有时可以在状态空间中运用等效手段对状态进行缩放。这样一般可以使需要计算的问题得到极大的简化
背包
0/1背包
给定N个物品,其中第i个物品的体积为vi,价值为wi。有一容积为M的背包,要求选择一些物品放入背包,是的物品的总体
积不超过M的前提下,物品的总价值和最大
通过之前的学习,我们可以很容易的想到一个解法
用“已经处理的物品数”作为DP的阶段,“处理到第i个物品时背包的总体积”作为附加维度,“处理到第i个物品时背包
的总价值”作为状态
状态转移方程就是
f[i,j] = max(f[i-1,j],f[i-1,j-vi]+wi);//i表示处理到第i个物品,j表示选出了总体积为j的物品放入背包
初值f[0,0] = 0,其余全为负无穷,末态max{f[N][M]}
1 memset(f, 0xcf,sizeof(f));
2 for(int i = 1; i <= n; i++) {
3 for(int j = 0; j <= m; ++j)
4 f[i][j] = f[i - 1][j];
5 for(int j = v[i]; j <= m; ++j)
6 f[i][j] = max(f[i][j], f[i - 1][j - v[i]] + w[i]);
7 }
通过DP的状态转移方程我们发现,每阶段i的状态只与上一阶段i-1的阶段有关。在这种情况下,可以使用“滚动数组”的
优化方法,降低空间开销
我们把阶段i的状态存储在第一维下标为i&1的二维数组里。当i为奇数时,i&1等于1,,当i为偶数时,i&1等于0.。因此,
DP的状态就相当于在f[0][]和f[1][]两个数组中交替转移,空间复杂度从O(NM)降为O(M)
1 int f[2][MAX_M + 1];
2 memset(f, 0xcf, sizeof(f));
3 for(int i = 1; i <= n; i++) {
4 for(int j = 0; j <= m; ++j)
5 f[i & 1][j] = f[(i - 1) & 1][j];
6 for(int j = v[i]; j <= m;j++)
7 f[i & 1][j] = max(f[i & 1][j], f[(i - 1) & 1][j - v[i]] + w[i]);
8 }
9 int ans = 0;
10 for(int j = 0; j <= m; j++)
11 ans = max(ans, f[n & 1][j]);
进一步分析,容易发现在阶段开始时,我们实际执行了一次f[i-1][]到f[i][]的拷贝操作。因此我们可以想,能不能忽略
掉第一维,只用一维数组呢?
答案是可行的,因为当你从阶段i-1到阶段i时,最外层循环也从i-1到了i,实际上我们可以设想这一维算在了外层循环里
,通过循环实现阶段转移,f[j]就表示当外层循环到第i个物品时,放入背包总体积为j的物品的最大价值和
int f[2][MAX_M + 1];
memset(f, 0xcf,sizeof(f));
f[0] = 0;
for(int i = 1; i <= n; ++i)
for(int j = m; j >= v[i]; --j)
f[j] = max(f[j], f[j - v[i]] + w[i]);
注意循环是倒序循环的,循环到j时
1.f数组后半部分f[j~m]处于“第i个阶段”,也就是考虑已经放入第i个物品的情况
2.前半部分f[0~j-1]处于“第i-1个阶段”,也就是还没有第i个物品更新
接下来,j不断减小,我们DP总是有“第i-1个阶段”的状态向“第i个阶段”的状态进行转移,符合线性DP的原则,进而保
证第i个物品只会被放入背包1次
但是如果正序循环呢,假设f[j]被f[j-vi]+wi更新,接下来j增加到vi时,f[j+vi]又可能被f[j]+wi更新,相当于两个都处
于“第i个阶段”的状态之间发生了转移,违背了线性DP的原则,相当于第i个物品被用了两次,所以必须倒序
完全背包
给定N种物品,其中第i中物品体积为vi,价值为wi,并且有无数个,有一个容量为M的背包,要求选择若干个物品放入背包,使得物品总体积不超过M的前提下,物品的总价值最大
我们会发现0/1背包特别像,唯一的区别就在于每个物品有无限个,
我在0/1背包分析内层循环搜索顺序时得到,若正着搜索,就会出现重复计算,在0/1背包中,一个物品只能取一次,但完全背包相反,物品无限,这样我们要想实现这无限物品获取,只需要把0/1背包中内层循环的倒序改成正序就可以了.
1 int f[MAX_M + 1];
2 memset(f, 0xcf, sizeof(f));
3 f[0] = 0;
4 for(int i = 1; i <= n; ++i)
5 for(int j = v[i]; j <= M; ++j)
6 f[j] = max(f[j], f[j - v[i]] + w[i]);
例题*5
poj1015
在遥远的国家佛罗布尼亚,嫌犯是否有罪,须由陪审团决定。陪审团是由法官从公众中挑选的。先随机挑选n个人作为陪审团的候选人,然后再从这n个人中选m人组成陪审团。选m人的办法是:
控方和辩方会根据对候选人的喜欢程度,给所有候选人打分,分值从0到20。为了公平起见,法官选出陪审团的原则是:选出的m个人,必须满足辩方总分和控方总分的差的绝对值最小。如果有多种选择方案的辩方总分和控方总分的之差的绝对值相同,那么选辩控双方总分之和最大的方案即可。
输入 输入包含多组数据。每组数据的第一行是两个整数n和m,n是候选人数目,m是陪审团人数。注意,1<=n<=200, 1<=m<=20 而且 m<=n。接下来的n行,每行表示一个候选人的信息,它包含2个整数,先后是控方和辩方对该候选人的打分。候选人按出现的先后从1开始编号。两组有效数据之间以空行分隔。最后一组数据n=m=0 输出 对每组数据,先输出一行,表示答案所属的组号,如 'Jury #1', 'Jury #2', 等。接下来的一行要象例子那样输出陪审团的控方总分和辩方总分。再下来一行要以升序输出陪审团里每个成员的编号,两个成员编号之间用空格分隔。每组输出数据须以一个空行结束。 样例输入
4 2
1 2
2 3
4 1
6 2
0 0
样例输出
Jury #1
Best jury has value 6 for prosecution and value 4 for defence:
2 3
翻译一下?n件物品,第i件物品有ai和bi两个价值,每件物品的体积为1,要塞满体积为m的背包,并且要求选择的M件物品满足第一价值总和D和第二价值总和P的差的最小,如果选择方法不唯一,在从中选择第一价值和第二价值和最大的方案
1.n个人,每个人只有一次,填满M个人
2.第i个人的控方得分a[i]
3.第i个人的辩方得分b[i]
0/1背包?但是有2个体积哇emmm?
划分阶段:
i个人,目前已有j个人进团
很直观的是,把每个人划分为单独阶段,把a[i]和b[i]作为附加状态
状态转移:
我们对于某个人j,有两种决策,能选,或是不能,那么我们好像也没有能用来转移的啊?
f[j,p,q] = f[j,p,q] or f[j,p-a[i],q-b[i]
并且|p-q|尽量小,|p-q|相同时,p+q尽量大
然后bool标记?emmm我是不知道能不能写,但是看着都觉得违和
想想怎么优化写法?
优化的重点显然在于后两维
我们想想后两维,发现|d-p|决定着d+p,
我们不妨,把d-p的差,作为一个单独的量,然后把d+p当做价值
即:f[j,k],表示选到第j个人,控方和辩方总和的差为k时,最大的价值d+p
f[j,k] = max{f[j - 1, k - (a[i] - b[i])] + a[i] + b[i]}
初态f[0,0] = 0,其余皆为负无穷
a[i]-b[i]显然可以预处理出来的,a[i]+b[i]也可以
然后这道题还需输出方案
d[j,k]数组记录状态f[j,k]是选了哪一名候选人得到的
丢人的是,我还是A不掉这道题,就当思考题orz,解决不了转移方案。
加入要A的题的列表
分组背包
给定N组物品,其中第i组有ci个物品。第i组的第j个物品的体积为vij,价值为wij。有一个容量为m的背包,要求选择若干个物品放入背包,使得每组至多选择一个物品并且物品总体积不超过M的前提下,物品的总价值和最大
考虑原始线性DP做法,为了满足“每组至多选择一个物品”,很自然的就是利用“阶段”线性增长的特征,把“物品组数”作为DP的“阶段”,只要使用了第i组的物品,就从第i个阶段转移到第i+1个阶段的状态。设f[i,j]表示从前i组中选出总体积为j的物品放入背包,物品的最大价值和.
f[i,j] = max{f[i - 1, j], max{f[i - 1, j - vik] + wik}(1 <= k <= ci)}
用j的倒序循环来控制“阶段i”的状态只能从“阶段i-1”转移而来。
1 memset(f, 0xcf, sizeof(f));
2 f[0] = 0;
3 for(int i = 1; i <= n; ++i)
4 for(int j = m; j >= 0; j--)
5 for(int k = 1; k <= c[i]; ++k) {
6 if(j >= v[i][k])
7 f[j] = max(f[j], f[j - v[i][k]] + w[i][k]);
8 }
除了倒序循环j,对于每一组内c[i]个物品的循环k应该放在j的内层。从背包角度看,这是因为每组内至多选择一个物品,若把k置于j的外层,就会类似于多重背包,每组物品在F数组上的转移会产生累乘,最终选择超过1件物品,从DP的角度,i是“阶段”,i与j共同构成“状态”,而k是“决策”——在第i组中使用哪一样物品,这三者顺序不能混淆
例题*6
配置魔药
在《Harry Potter and the Chamber of Secrets》中,Ron的魔杖因为坐他老爸的Flying Car撞到了打人柳,不幸被打断了,从此之后,他的魔杖的魔力就大大减少,甚至没办法执行他施的魔咒,这为Ron带来了不少的烦恼。这天上魔药课,Snape要他们每人配置一种魔药(不一定是一样的),Ron因为魔杖的问题,不能完成这个任务,他请Harry在魔药课上(自然是躲过了Snape的检查)帮他配置。现在Harry面前有两个坩埚,有许多种药材要放进坩埚里,但坩埚的能力有限,无法同时配置所有的药材。一个坩埚相同时间内只能加工一种药材,但是不一定每一种药材都要加进坩埚里。加工每种药材都有必须在一个起始时间和结束时间内完成(起始时间所在的那一刻和结束时间所在的那一刻也算在完成时间内),每种药材都有一个加工后的药效。现在要求的就是Harry可以得到最大的药效。
输入文件的第一行有2个整数,一节魔药课的t(1≤t<≤500)和药材数n(1≤n≤100)。
输入文件第2行到n+1行中每行有3个数字,分别为加工第i种药材的起始时间t1、结束时间t2、(1≤t1≤t2≤t)和药效w(1≤w≤100)。
但是这道题目给的数据,显然时间的起始和结束都是无序的,排序后我们就能使时间有序化
那么我们是排序起始时间,还是结束时间呢?
我们假设某个状态,我们不知道这个状态在题目给出的几种药材中是否存在,我们从前一个状态向当前状态更新,我们需要什么
我们肯定需要这个任务的开始时间,那么我们需要上一个任务的什么才能由前一个状态推导到当前任务呢,我们需要结束时间,也就是说,能将当前状态与前一个状态建立起联系的东西,是前一个任务的结束时间和当前任务的开始时间。但是似乎排序开始时间,修改思考方向,也能完成?
但最关键的,决定性的是,当排序完结束时间后,完成所有任务所需要的时间的区间长度就确定了,但排序开始时间不行,排序完开始时间后,我们所知道的有序的时间长度是第一个任务的开始时间到最后一个任务的结束时间,但是在这个时间长度的最后,会缺失一块结束时间,在这个时间中,可能会出现最后的数个任务结束时间重叠的问题。(纯属脑洞,无严格证明,最好能打我脸)
想好解题初步后,思考状态转移方程
n种药材,总时间为t,每种药材只有1个,这个药材有需要的时间和价值
我们换个思路就变成了:
n个物品,每种物品只有一个,这个物品有价值w,和需要的体积v,放入一个总容量为t的背包,使背包总价值最大
0/1背包,只不过不同的是,题目有两个坩埚
那么我们就把状态设为f[i,j],表示完成到第k个任务,第一个坩埚煮过药材的时间为i,第二个坩埚煮过药材的时间为j时,药材的总价值为f[i,j]
那么我们只需要特判一下两个坩埚哪一个能放入药材k就行了
f[i,j] = max{f[a[k].st - 1, j] + a[k].w}(i >= a[i].end)
= max{f[i, a[k].st - 1] + a[k].w}(j >= a[i].end)
这样我们就可以轻松AC了
初态:f[][]数组全为0,末态:max{f[t][t]}
例题*7
交错匹配
有两行自然数,UP[1..N],DOWN[1..M],如果UP[I]=DOWN[J]=K,那么上行的第I个位置的数就可以跟下行的第J个位置的数连一条线,称为一条K匹配,但是同一个位置的数最多只能连一条线。另外,每个K匹配都必须且至多跟一个L匹配相交且K≠L 。现在要求一个最大的匹配数。
例如:以下两行数的最大匹配数为8

1 2 3 3 2 4 1 5 1 3 5 10
3 1 2 3 2 4 12 1 5 5 3
划分阶段,
处理到上方第i个数与下方第j个数时,所能得到的最大匹配数
状态,匹配到上方第i个数和下方第j个数时,已得到的最大匹配数
但是我们仅仅这样,够吗?
分析一下,我们实际上根本不知道能哪些数能匹配,哪些不能,我们也就没办法进行转移
因此,我们需要预处理出哪些数能够匹配
运用贪心思想,我们可以知道,在上方第i个点和下方第j个点的连线要想相交,上方i所连的一定在j之前,下方j连的一点在上方i之前,然后我们要想匹配数最大,那么i相连的点距离j最近,j相连的点要距离i最近
这样我们单独计算两个dp,分别表示上方序列到第i个数,第i个数能够匹配距离下方j最近的点
和下方序列到第j个数时,第j个数所能匹配的距离上方i最近的点
dp1[i][j] = (up[i] == down[j - 1])?j - 1:dp1[i][j-1]
dp2[i][j] = (up[i - 1] == down[j])?i - 1:dp2[i-1][j]
得到了能够匹配的点后,我们来思考如何构造dp方程
在上面划分阶段时,我们已经把阶段划分为了:
处理到上方第i个数与下方第j个数时,所能得到的最大匹配数
思考:
对于序列的匹配,可能有几种情况?
我们要先理清,前一个状态是怎么转移到当前状态的?
既然是双进程,我想当然的把两个序列当成单独的两个结构来看
上方得到i,是由i-1扩展来的,
下方得到j,是由j-1扩展来的
根据上面的贪心分析我们知道,
i实际匹配的是j-1,j实际匹配的是i-1,
如果我们想,i,j这个位置不能上下匹配出新的数来,可以得到三种推导到当前位置的情况
由上序列匹配下序列,前一个处理后扩展到当前位置
f[i][j] = f[i][j - 1]
下序列匹配上序列,前一个阶段处理后扩展到当前位置
f[i][j] = f[i - 1][j]
上序列和下序列匹配点处在同一位置,同时向后扩展得到当前位置
f[i][j] = f[i - 1][j - 1]
还有可能是,在i这个位置能够和下序列中某一个匹配,j这个位置能够和上序列中某一个位置匹配,由上述贪心思考得出的结论看,必定是相交的,那么我们可以得到新的推导,即在i,j的位置可以完成新的匹配,i匹配下序列j前某个点,j匹配上序列中i前的某个点,则当前状态就应由上序列处理到i匹配的j中的点的位置,下序列处理到j匹配的i中的点的位置时对应的状态扩展得来
f[i][j] = f[dp1[i][j]][dp2[i][j]] + 2
四种情况取max值,方程就是
f[i][j] = max{f[i-1][j], f[i][j-1], f[i-1][j-1], f[dp1[i][j]][dp2[i][j]]}
初态:f数组全为0,从f[2][2]开始
末态:max{f[n][m]}
然而不如换个思路吧...
以上是第一次第一轮艰难的思考,思路还不是很清晰
然后我又思考了第二次:
在写了一系列单进程DP后,似乎陷入了诡异的思维定式,似乎认为这一整块是一个进程
但是这题是双进程DP,这就意味着,up,down两个数列,是两个进程
f[i,j]是描述两个进程的
i是描述第一个进程的,j是描述第二个进程的
是的,这是独立的
然后看看有什么信息:
知道两个序列的长度,知道每个位置的值
不知道什么:
不知道哪两个数可以匹配,不知道有多少匹配数
匹配数是我们DP要解决的
但是哪两个可以匹配呢
问题是,这两个数或许可以匹配,但我们不知道他能不能用上,所以我们需要的是什么?
是每一个数能够和另一个序列的多少数匹配,能够匹配的数在另一个序列都是什么位置
那么怎么去找呢?要找什么究竟?
看看我们的f[i,j]是什么
一序列进行到第i个数,二序列进行到第j个数时,最大的匹配数
决策点是(i,j),我们假设(i,j)都在另一个序列上有对应匹配的点,这个点的位置要尽可能的靠近(i,j)这个决策点,最优的就是i匹配j-1,j匹配i-1
然后第一感觉,我们似乎发现:
序列中的每一个点在另一个序列在找能够与它匹配的位置最大的点,似乎很像是一个子DP?
确实可以用DP解决,还是很明显的那种
我们设一个新的阶段:
dp1[i,j]表示第一个序列的第i个点,在尝试匹配第二个序列的点,匹配到第j个点时,所能够得到的位置最大的点,同时由于决策的必须,这个点的位置不能比i大
dp2[i,j]表示第二个序列的第i个点,在尝试匹配第一个序列的点,匹配到第j个点时,所能够得到的位置最大的点,同时由于决策的必须,这个点的位置不能比j大
然后处理完这个后
我们思考f[i,j]的转移方式,首先思考有多少种情况可以使第一个序列进行到i,第二个序列进行到j
1.由f[i-1,j]得到
2.由f[i,j-1]得到
3.由f[i-1,j-1]得到
这是三个直观的正常转移,还有第四种决策情况
4.假如(i,j)是一个无论i还是j都有对应匹配的决策点,那么根据DP的进程方式思考,因为i,j的对应匹配点都在他们之后,因此,我们显然已经计算过他们对应的点ii和jj时的最大匹配值
那么我们可以由f[ii,jj]直接导出f[i,j],特判一下up[i]和down[j]是否相等就可以解决K≠L的问题
总的DP方程就是
f[i,j] = max{f[i-1][j], f[i][j-1], f[i-1][j-1], (f[dp2[i][j],dp1[i][j]]+2 (up[i]!=down[j]))}
初态:f数组全为0
末态:max{f[n][m]}
但是倒最后,真的很惨,真的很惨,也真的很菜,
我们办法把这道题A掉,卡在了K!=L的问题上,说实话,我解决不了
优化方式写炸,最后无奈,写了个显然的四重循环
1 #include<bits/stdc++.h>
2 #define l 300
3 #define maxn 33000
4 using namespace std;
5 int n, m;
6 int dp1[l][l], dp2[l][l];
7 int f[l][l];
8 int up[l], down[l];
9 inline int read() {
10 int x = 0, y = 1;
11 char ch = getchar();
12 while(!isdigit(ch)) {
13 if(ch == '-') y = -1;
14 ch = getchar();
15 }
16 while(isdigit(ch)) {
17 x = (x << 1) + (x << 3) + ch - '0';
18 ch = getchar();
19 }
20 return x * y;
21 }
22 int main() {
23 int i, j, p, q;
24 n = read(), m = read();
25 for(i = 1; i <= n; ++i)
26 up[i] = read();
27 for(i = 1; i <= m; ++i)
28 down[i] = read();
29 /* for(int i = 2; i <= n; ++i)
30 for(int j = 2; j <= m; ++j) {
31 if(up[i] != up[i - 1] && down[j] != down[j - 1]) {
32 dp1[i][j] = (up[i] == down[j - 1]) ? j - 1 : dp1[i][j - 1];
33 dp2[i][j] = (down[j] == up[i - 1]) ? i - 1 : dp2[i - 1][j];
34 }
35 }*/
36 /*for(int i = 1; i <= n; ++i)
37 for(int j = 1; j < min(i, m); ++j)
38 dp1[i][j] = (up[i] == down[j - 1]) ? j - 1 : dp1[i][j - 1];
39 for(int i = 2; i <= n; ++i)
40 for(int j = 2; j <= m; ++j)
41 dp2[i][j] = (down[j] == up[i - 1]) ? i - 1 : dp2[i - 1][j];
42 for(int i = 1; i <= n; ++i) {
43 for(int j = 1; j <= m; ++j)
44 cout << dp1[i][j] << ' ';
45 cout << endl;
46 }
47 for(int i = 1; i <= n; ++i) {
48 for(int j = 1; j <= m; ++j)
49 cout << dp2[i][j] << ' ';
50 cout << endl;
51 }*/
52 for(i = 1; i <= n; ++i)
53 for(j = 1; j <= m; ++j) {
54 f[i][j] = max(f[i - 1][j], f[i][j]);
55 f[i][j] = max(f[i][j - 1] ,f[i][j]);
56 f[i][j] = max(f[i - 1][j - 1], f[i][j]);
57 /*if(up[i] != down[j] && (dp1[i][j] != 0 || dp2[i][j] != 0)){
58 f[i][j] = max(f[dp1[i][j]][dp2[i][j]] + 1, f[i][j]);
59 }
60 for(p = 1; p <= i; ++p)
61 for(q = 1; q <= j; ++q)
62 f[i][j] = max(f[i][j], f[p][q]);*/
63 if(up[i] != down[j])
64 for(p = 1; p < i; ++p) {
65 if(up[p] == down[j])
66 for(q = 1; q < j; ++q)
67 if(down[q] == up[i])
68 f[i][j] = max(f[i][j], f[p - 1][q - 1] + 1);
69 }
70 }
71 cout << f[n][m] * 2<<'\n';
72 return 0;
73 }
区间DP
例题*1
合并石子
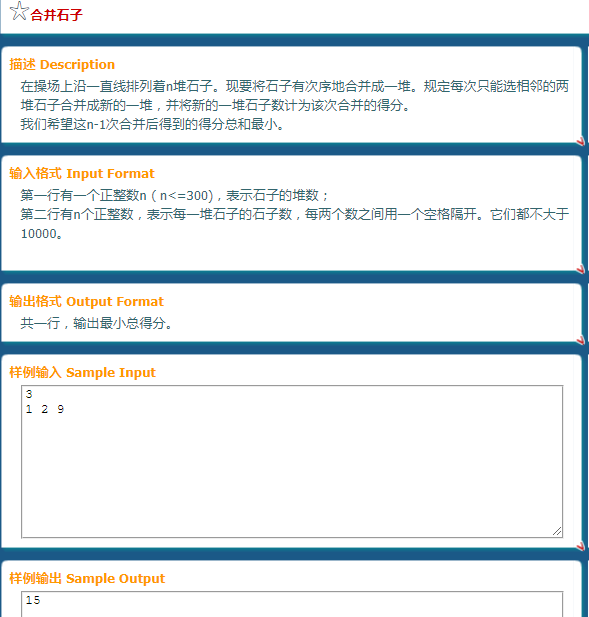
若最初的第l堆式子和第r堆石子被合并成一堆,这说明l~r之间的每堆石子也已经被合并,这样l和r才有可能相邻,因此在任意时刻,任意一堆石子均可以用一个闭区间[l, r]描述,表示这对石子是由最初第l~r堆石子合并而成的,其重量为l到r堆石子的累加和。并且,一定存在一个整数k(l<=k<=r),在第l~r堆石子形成前,先有第l~k堆石子(闭区间[l,k])被合并成一堆,第k+1~r堆石子(闭区间[k+1,r])被合并成一堆,然后这两堆石子才合并成[l,r]
对应到动态规划中,就意味着两个长度较小的区间上的信息向一个更长的区间发生了转移,划分点k就是转移的决策,自然地,应该把区间长度len作为决策的阶段,不过区间长度可以用l和r表示出,即len=r-l+1。本着动态规划“选择最小的能覆盖状态空间的维度集合”的思想,我们可以只用左、右端点表示DP的状态。
设f[l,r]表示把最初的第l堆到第r堆石子合并成1堆,需要消耗的最小体力
我们假设已求出一前缀和数组A
状态转移方程:
f[l,r] = min{f[i,k] + f[k+1,r]}(l<=k<=r) + A[r] - A[l-1];
初值:l∈[1,n],f[ll] = A[l],其余均为正无穷
目标:f[1,n];
但是对于动态规划问题,除了状态转移方程,还有一个非常重要的问题:合适的循环的顺序
这就告诉我们:分清阶段,状态和决策,这三者从外向内循环
阶段:根绝题目分析,我们把区间的长度作为了阶段,
状态:我们用左右端点作为了动态规划的状态,那么这样我们已知了上一阶段区间长度,向下一阶段转移,我们需要求出左右端点,有len = r - l + 1可得r = len + l - 1和 l = r - len + 1,这样我们就可以只用一重循环来确定状态,枚举左端点,我们就计算得出右端点,枚举右端点,就计算得出左端点。
决策,从左端点开始向右端点依次枚举k作为决策点。
这样就确定了循环内容及循环顺序,然后就可以套着AC了
1 #include<bits/stdc++.h>
2 #define maxn 1086
3 using namespace std;
4 int f[maxn][maxn];
5 int n;
6 int a[maxn], sum[maxn];
7 inline int read() {
8 int x = 0, y = 1;
9 char ch = getchar();
10 while(!isdigit(ch)) {
11 if(ch == '-') y = -1;
12 ch = getchar();
13 }
14 while(isdigit(ch)) {
15 x = (x << 1) + (x << 3) + ch - '0';
16 ch = getchar();
17 }
18 return x * y;
19 }
20 int main() {
21 memset(sum, 0, sizeof(sum));
22 memset(f, 10, sizeof(f));
23 n = read();
24 for(int i = 1; i <= n; ++i)
25 a[i] = read();
26 for(int i = 1; i <= n; ++i) {
27 f[i][i] = 0;
28 sum[i] = sum[i - 1] + a[i];
29 }
30 for(int len = 2; len <= n; ++len)
31 for(int l = 1; l <= n - len + 1; ++l) {
32 int r = len + l - 1;
33 for(int k = l; k < r; ++k)
34 f[l][r] = min(f[l][r], f[l][k] + f[k + 1][r]);
35 f[l][r] += sum[r] - sum[l - 1];
36 }
37 cout << f[1][n] <<'\n';
38 return 0;
39 }
IOI1998 Polygon
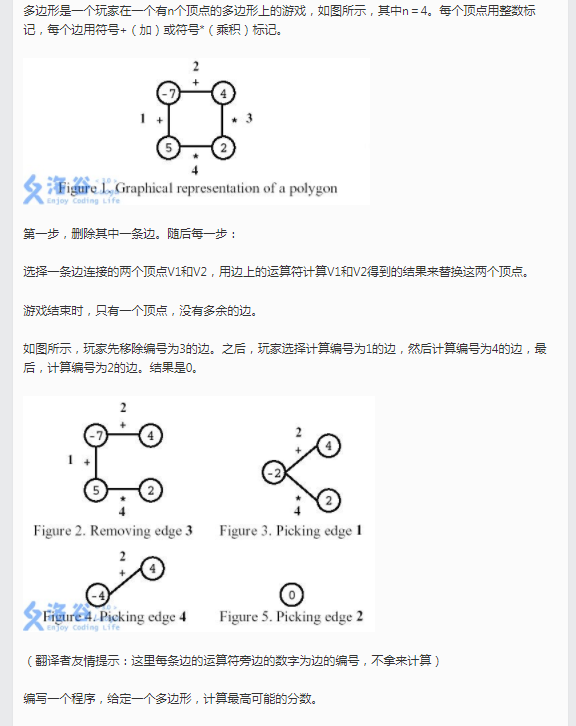
在枚举哪一条边删除过后,这道题就与“石子合并非常相似了”,仍然是在每一步中对两个端点做某种运算将他们合并。简便起见,我们把被删除的边逆时针方向的顶点称为“第一个顶点”,依此类推。容易想到,用f[l,r]表示第l到第r个顶点合成一个顶点后,顶点的最大数值是多少。
如果这道题的顶点全为正数,我们已经A了这道题了
我们先来看看动态规划的三个前提:
“子问题重叠性”“无后效性”和“最优子结构”
什么是最优子结构呢?
搬用算法导论的话:“如果一个问题的最优解包含其子问题的最优解,我们就称此问题具有最优子结构。”
我们再看看这道题是否满足
事实上,最优子结构不再满足了。
因为负数的存在,在由小区间向大区间合并时,大区间[l,r]合成的顶点的最大值无法由[l,k]和[k+1,r]导出,因为[l,k]和[k+1,r]合成的两个顶点的最小数值可能是很小的负数,但如果符号为乘号,负负得正,运算的结果可能会变得更大
那么我们想一想问题怎么解决。
如果我们把区间[l,r]合并的最小值和最大值同时作为子问题[l,r]的代表信息,就可以满足最优子结构了。最大值的来源只可能是两个最大值相加、相乘或两个最小值相乘(负负得正),这是很显然的,若两个最大值都是正数,合并后,自然是相乘或是相加,但是两个最小值都是负数并且特别小,他们的乘积就会很大,所以有这3种可能来源。
而[l,r]合并后的最小值,来源只可能是两个最小值想加、相乘,或一个最大值与一个最小值相乘(正负得负),这也是很显然的,不再赘述。
因此,可以设f[l,r,0]表示第l到r顶点合成一个顶点后的最大值,f[l,r,1]表式第l到r顶点合成一个顶点后的最小值是多少,枚举区间划分点k决策,然后我们就可以仿照合并石头写出状态转移方程,op表示符号
f[l,r,0] = max{f[l,k,0] op f[k+1,r,0]}
{f[l,k,1] op f[k+1,r,1](若op为乘号)}
f[l,r,1] = min{f[l,k,1] op f[k+1,r,1]}
min{f[l,k,1] op f[k+1,r,0], f[l,k,1] op f[k+1,r,1]}(若op为乘号)
初态: f[l,l,0] = f[l,l,1] = Al,其余均为正或负无穷
目标: f[1,n,0]
但是在实际写题的时候还是需要考虑循环的东西....emmmm
ioi题再水也不好写....(虽然我很不想说,看着题解写过的).....
1 #include<bits/stdc++.h>
2 #define maxn 150
3 using namespace std;
4 int n, a[maxn];
5 int dp1[maxn][maxn], dp2[maxn][maxn];//dp1表示最大值,dp2表示最小值
6 int cal[maxn];
7 int ans = -2e9, pre[maxn], top = 0;
8 inline int read() {
9 int x = 0, y = 1;
10 char ch = getchar();
11 while(!isdigit(ch)) {
12 if(ch == '-') y = -1;
13 ch = getchar();
14 }
15 while(isdigit(ch)) {
16 x = (x << 1) + (x << 3) + ch - '0';
17 ch = getchar();
18 }
19 return x * y;
20 }
21 inline int dtgh(int x) {
22 memset(dp1, 0xcf, sizeof(dp1));
23 memset(dp2, 0x3f, sizeof(dp2));
24 for(int i = x; i <= x + n - 1; ++i)
25 dp1[i][i] = dp2[i][i] = a[i];
26 for(int len = 1; len <= n; ++len)
27 for(int l = x; l <= (x + n - 1) - len + 1; ++l) {
28 int r = l + len - 1;
29 for(int k = l + 1; k <= r; ++k) {
30 if(cal[k]) {//如果是乘号
31 dp1[l][r] = max(dp1[l][r], dp1[l][k - 1] * dp1[k][r]);
32 dp1[l][r] = max(dp1[l][r], dp2[l][k - 1] * dp2[k][r]);
33 dp2[l][r] = min(dp2[l][r], dp2[l][k - 1] * dp1[k][r]);
34 dp2[l][r] = min(dp2[l][r], dp1[l][k - 1] * dp2[k][r]);
35 dp2[l][r] = min(dp2[l][r], dp2[l][k - 1] * dp2[k][r]);
36 }
37 else if(cal[k] == 0){//如果是加号
38 dp1[l][r] = max(dp1[l][r], dp1[l][k - 1] + dp1[k][r]);
39 dp2[l][r] = min(dp2[l][r], dp2[l][k - 1] + dp2[k][r]);
40 }
41 }
42 }
43 return dp1[x][x + n - 1];
44 }
45 int main() {
46 memset(cal, -1,sizeof(cal));
47 n = read();
48 for(int i = 1; i <= n; ++i) {
49 char c;
50 cin >> c;
51 a[i] = read();
52 if(c == 'x')
53 cal[i + n] = cal[i] = 1;//0表示加号,1表示乘号
54 else cal[i + n] = cal[i] = 0;
55 a[i + n] = a[i];
56 }
57 for(int i = 1; i <= n; ++i) {
58 int y = dtgh(i);
59 if(ans == y) pre[++top] = i;
60 else if(ans < y) ans = y, top = 0, pre[++top] = i;
61 }
62 cout << ans <<'\n';
63 for(int i = 1; i <= top; ++i)
64 cout << pre[i] <<' ';
65 return 0;
66 }
以上算法是O(n^4)的,因为在上述算法中,除了基本的三重循坏外,我们还需要枚举删除哪一条边
但实际我们是可以把这个优化掉的,我们先这样想,比如:
1 3 -7 8
这样一个环
我们设1和3之间是+号,我们删掉[1,3]后,原序列变为
4 -7 8
我们会发现,序列长度减小了,也就是说我们只能算先删掉[1,3]这一种情况了,那么我们要怎么办?
我们把这个序列再复制一次接在原序列后面看看
4 -7 8 4 -7 8
我们再看看是否能够完成我们刚才所说的问题
答案是能,
[1,3][2,4][3,5]这些都是与原来等效的,我们如此处理后,就可以一次枚举所有情况而不用枚举每次删掉哪一条边
然后再想,如果最初的[1,3]不进行合并,直接复制一次呢?
1 3 -7 8 1 3 -7 8
我们就能发现,可行,这样我们就省去了枚举断边的问题
我们原本枚举断掉第i条边的问题就可以对应为[i, i + n]
[i, i + n]就可以描述先断掉第i条边合并第i条边连接的两点,复杂度就降低为O(n^3)了
从这个问题我们可以总结出一条规律性结论:
对于动态归划的环形问题,“任意选择一个位置断开,复制形成2倍长度的链”是解决环形问题的常用手段之一。
其表现为,将链的长度扩为2*n,对于一个序列a,a[i+n] = a[i]
鬼畜的一些新知识
1.对于方案计数类的动态规划问题,通常一个状态的各个决策之间满足“加法原理”,而每个决策划分的几个子状态之间满足“乘法原理”
树形DP
给定一颗有N个节点的树(通常是无根树,也就是有N-1条无向边),我们可以任选一个节点为根节点,从而定义出每个节点的深度和每颗子树的根。在书上设计动态规划算法时,一般就以节点从深到浅(子树从小到大)的顺序作为DP的“阶段”。DP的状态表示中,第一维通常是节点编号(代表以该节点为根的子树)。大多数时候,我们采用递归的方式实现树形动态规划。对于每个节点x,先递归在它的每个子节点上进行DP,在回溯时,从子节点想节点x进行状态转移
例题*1
没有上司的舞会(TYVJ1052)
Ural大学有N个职员,编号为1~N。他们有从属关系,也就是说他们的关系就像一棵以校长为根的树,父结点就是子结点的直接上司。每个职员有一个快乐指数。现在有个周年庆宴会,要求与会职员的快乐指数最大。但是,没有职员愿和直接上司一起与会。
输入格式
第一行一个整数N。(1<=N<=3000)
接下来N行,第i+1行表示i号职员的快乐指数Ri。(-128<=Ri<=127)
接下来N-1行,每行输入一对整数L,K。表示K是L的直接上司。
最后一行输入0,0。
输出格式
输出最大的快乐指数
根据树形DP最初讨论,我们以节点编号(子树的根)作为DP状态的第一维
因为一名职员是否愿意与会,只与他的上司是否愿意与会有关,所以我们在每颗子树递归完成时,保留两个“代表信息”:即“根节点参加与会时整颗子树的最大快乐指数和”和“根节点不参加与会时整颗子树的最大快乐指数和”,这样就可以满足最优子结构
f[x,0]表示以x为节点的子树中邀请一部分职员参加并且x本人不参与与会时,整颗子树的最大快乐指数,此时,x的下属可以参加与会,也可以不参加与会
f[x,1]表示以x为节点的子树中邀请一部分职员参加并且x本人参与与会时,整颗子树的最大快乐指数,此时,x的下属不可以参加与会
然后,emmmm,我不会,写,树形DP的,状态,转移,方程,或者说,不会,在,代码,以外,的,地方,写!
至少,现在,不会!
解题思路,本题读入的是一颗有根树,所以我们先找个没有根的节点作为根节点,逐层向下递归,
我们在上述情况中分析有两个情况
1.根节点不参加与会
2.根节点参加与会
我们想到根节点时的最大值是由子节点传递而来的,我们已经标记根节点是否参加聚会,那么我们从根节点向下递归,一直找到叶子节点,叶子节点能否与会,取决于他的根节点是否与会,这样我们可以直接处理叶子节点的值
1.当根节点与会时,叶子节点不与会
2.当根节点不与会时,叶子节点与会,然后向上逐层传递,每层设两个变量max1,max0,标记根节点与会时的最大快乐值和根节点不与会时的最大快乐值。
最后向上逐层计算即可
1 #include<bits/stdc++.h>
2 #define maxn 10011
3 using namespace std;
4 struct noe{
5 int to, next;
6 }e[maxn];
7 int f[maxn][3], lin[maxn];
8 int a[maxn];
9 int len = 0;
10 int n, root = 0;
11 int myson[maxn];
12 inline int read() {
13 int x = 0, y = 1;
14 char ch = getchar();
15 while(!isdigit(ch)) {
16 if(ch == '-') y = -1;
17 ch = getchar();
18 }
19 while(isdigit(ch)) {
20 x = (x << 1) + (x << 3) + ch - '0';
21 ch = getchar();
22 }
23 return x * y;
24 }
25 inline void insert(int pre, int son) {
26 e[len].to = son;
27 e[len].next = lin[pre];
28 lin[pre] = len++;
29 }
30 void dpdfs(int pre) {
31 f[pre][0] = 0;
32 f[pre][1] = a[pre];
33 int max0 = 0, max1 = 0;
34 for(int i = lin[pre]; i != -1; i = e[i].next) {
35 int son = e[i].to;
36 dpdfs(son);
37 max0 += max(f[son][0], f[son][1]);
38 max1 += f[son][0];
39 }
40 f[pre][0] += max0;
41 f[pre][1] += max1;
42 }
43 int main() {
44 memset(myson, 0, sizeof(myson));
45 memset(lin, -1, sizeof(lin));
46 n = read();
47 for(int i = 1; i <= n; ++i)
48 a[i] = read();
49 for(int i = 1; i <= n; ++i) {
50 int u, v;
51 v = read(), u = read();
52 if(i == n) break;
53 insert(u, v);
54 myson[v]++;
55 }
56 for(int i = 1; i <= n; ++i)
57 if(myson[i] == 0) {
58 root = i;
59 break;
60 }
61 dpdfs(root);
62 cout << max(f[root][0], f[root][1]) <<'\n';
63 return 0;
64 }
正如BFS和DFS都可以对树或图进行遍历一样,除了自顶向下的递归外,我们也可以用自底向上的拓扑排序来执行树形DP。
再更多地题目中,树是以一张N个点,N-1条边的无向图的形式给出的。在这种情况下使用树形DP算法时,我们就要用邻接表存下来这N-1条无向边,任选一个点出发执行深度优先遍历,并注意标记节点是否已经被访问过,以避免在遍历中沿着反向边回到父节点。
水题*1
马拦过河卒
棋盘上A点有一个过河卒,需要走到目标B点。卒行走的规则:可以向下、或者向右。同时在棋盘上C点有一个对方的马,该马所在的点和所有跳跃一步可达的点称为对方马的控制点。因此称之为“马拦过河卒”。
棋盘用坐标表示,A点(0, 0)、B点(n, m)(n, m为不超过20的整数),同样马的位置坐标是需要给出的。
现在要求你计算出卒从A点能够到达B点的路径的条数,假设马的位置是固定不动的,并不是卒走一步马走一步。
已知卒可以向下或是向右
信息:起点,终点,卒走路的方式,马的位置
我们知道了马所在的位置,把马所有能控制的点给打上标记表示这是不能走的
然后我们的基本思路:肯定不是搜索就是DP
搜索差不多也就是dfs回溯?
要求的是从A到B的路径条数,
我们先想
假设是如下棋盘
0 0
0 0
(1,1)是起点,(2,2)是终点,,卒只能向右或向下,有多少的方法数
答:2种,因为到(1,2)只有1种,(2,1)只有一种,有(2,1)和(1,2)扩展到(2,2)各只有一种方式,加起来2种
再把棋盘扩大
0 0 0
0 0 0
0 0 0
起点仍是(1,1)我们要到(3,2)有多少种方法
我们目前已知到(2,2)有两种方式,到(1,3)有一种方式,由这两点扩展到(1,3)各一种方式,所以到(1,3)有3种方式
总的分析:由加法原理,我们可以知道到某个点的方法数是由所有到达能到达目标点的点的方法数的累加
在本题中,由一个点向下一个点扩展,一共只有两种方式,向下或是向右
所以对于被扩展的点,所记录的到达方法数是他左边的点和上边的点的方法数的和
划分阶段:每一个到达的点
状态是到达某个点时的方法数
决策是左边的点的方法数+上边的点的方法数
这样就可以写出状态转移方程:
用f[i,j]表示到达某个点(i,j)时的方法数
f[i,j] = f[i - 1][j] + f[i][j - 1]
初值:f[0][0] = 1,其余全为0
末态:f[n][m]
但是建议把起点和终点全部偏移一位,不然就自己处理边界问题.....
1 #include<bits/stdc++.h>
2 #define l 50
3 #define ll long long
4 using namespace std;
5 ll f[l][l];
6 int n, m;
7 bool tu[l][l];
8 int ex, ey, hx, hy;
9 int dx[9] = {1, 1, -1, -1, 2, 2, -2, -2};
10 int dy[9] = {-2, 2, 2, -2, -1, 1, 1, -1};
11 inline int read() {
12 int x = 0, y = 1;
13 char ch = getchar();
14 while(!isdigit(ch)) {
15 if(ch == '-') y = -1;
16 ch = getchar();
17 }
18 while(isdigit(ch)) {
19 x = (x << 1) + (x << 3) + ch - '0';
20 ch = getchar();
21 }
22 return x * y;
23 }
24 int main() {
25 memset(f, 0, sizeof(f));
26 memset(tu, 0, sizeof(tu));
27 ex = read(), ey = read(), hx = read(), hy = read();
28 ex++, ey++, hx++, hy++;
29 tu[hx][hy] = 1;
30 for(int i = 0; i < 8; ++i) {
31 int xx = dx[i] + hx;
32 int yy = dy[i] + hy;
33 if(xx > ex || xx < 1 || yy > ey || yy < 1) continue;
34 tu[xx][yy] = 1;
35 }
36 f[1][1] = 1;
37 /*for(int i = 0; i <= ex; ++i) {
38 for(int j = 0; j <= ey; ++j)
39 cout << tu[i][j] << ' ';
40 cout << endl;
41 }*/
42 for(int i = 1; i <= ex; ++i)
43 for(int j = 1; j <= ey; ++j) {
44 if(!tu[i][j] && (!(i == 1 && j == 1)))
45 f[i][j] = f[i - 1][j] + f[i][j - 1];
46 }
47 cout << f[ex][ey] <<'\n';
48 return 0;
49 }
题目*1
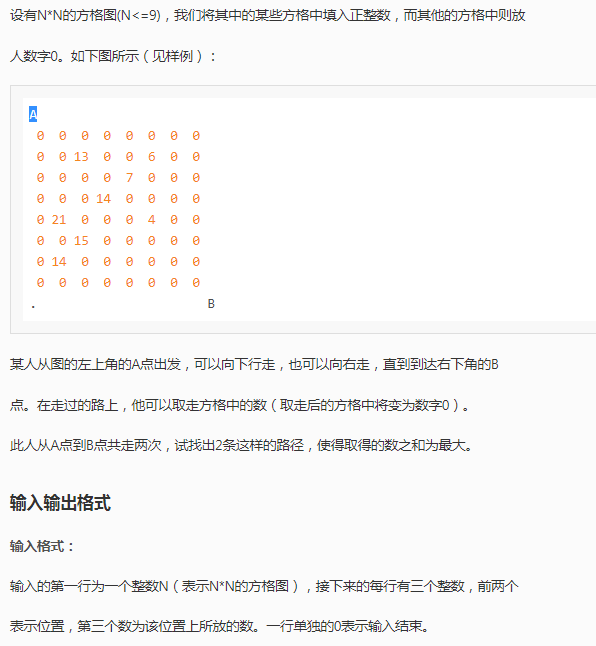
我甚至都觉得这是水题(写过noip2008的传纸条的话这题真没什么)
但是我连续写炸,仔细查错后发现方程上写错了个字母,论样例多么没用,然后改完后还是过不去,反复思索找不到错后决定重读题面,然后我发现:这题的读入要用死循环
是的,也就是说并没有告诉你读入多少组数,然后我傻傻的去for(int i = 1; i <= n; ++i),然后完美的炸了
对本题做一番讲解,然后你就可以用这套代码,稍作修改后A掉传纸条
双进程的DP,甚至可以说就是传纸条
我们从左上角走到右下角,可以向下或是向右
根据题目意思我们知道,要走两次
但是我们显然不能分成两次去计算,双进场DP不能白学....
我们先分阶段
f[i][j]表示当走到某个点时,能取得的最大和
但是我们知道这是分成两条路的, 所以上面的分法是错误的
我们需要能够描述整个状态空间的信息,我们能够发现的是,不管怎么走,因为被限制为只能向下或是向右,所以任意一条路径我们从左上角走到右下角的总步数一定是确定的,我们用n表示行,m表示列,我们要走的总步数一定是n + m - 1,我们思考为什么,只能向下或向右,显然从左上角走到右下角,我们横着走过的步数是等于n的,竖着走过的步数是等于m的,但是n与m存在一个交点,在这个点我们计算了两次,所以我们要-1
根据上面的分析,我们可以用m + n - 1来同时描述两条路径的进程。
然后我们还需要知道的是两条路径分别走到了哪两个点,直观的思路是,我们再给数组添加两个维度
f[1~n+m-1][x1][y1][x2][y2]
来覆盖整个状态空间但是这样会耗费巨额的空间,所以我们要简化状态
我们想能否由x1导出y1,并且使用的是已知信息
我们想,我们目前已经知道走了多少步,知道x1的话,怎么得到y1
联系上文我们推导出m+n-1的过程可以很容易发现,步数i等于x1+y1-1,因为我们知道,走了多少步是看在水平方向和竖直方向移动的总和再减去一步重复步数得到的
这样我们就得到了x1+y1 == x2+y2 == i+1
如此我们就能把状态空间转化为三维f[i][x1][x2]
这样一定是能够覆盖整个状态空间的,然后我们推导状态转移方程
我们可以由题意显然读到只能向下或是向右,这样可以得到显然的方程:(a表示原方格)
add = a[x1][y1]+a[x2][y2](x1 != x2) a[x1][x2](x1 == x2)
f[i][x1][x2] = max{f[i][x1-1][x2], f[i][x1][x2], f[i][x1][x2-1], f[i][x1-1][x2-1]}+add
1 #include<bits/stdc++.h>
2 #define m 20
3 using namespace std;
4 int n, x, y, v;
5 int a[m][m];
6 int f[m << 1][m][m];
7 int add;
8 inline int read() {
9 int x = 0, y = 1;
10 char ch = getchar();
11 while(!isdigit(ch)) {
12 if(ch == '-') y = -1;
13 ch = getchar();
14 }
15 while(isdigit(ch)) {
16 x = (x << 1) + (x << 3) + ch - '0';
17 ch = getchar();
18 }
19 return x * y;
20 }
21 int main() {
22 memset(a, 0, sizeof(a));
23 memset(f, 0, sizeof(f));
24 n = read();
25 for(;;) {
26 x = read(), y = read(), v = read();
27 if(x == 0 && y == 0 && v == 0) break;
28 a[x][y] = v;
29 }
30 //f[2][1][1] = a[1][1];
31 int len = n + n;
32 for(int k = 2; k <= len; ++k)
33 for(int i = 1; i < k && i <= n; ++i)
34 for(int j = 1; j < k && j <= n; ++j) {
35 if(i == j) add = a[i][k - i];
36 else if(i != j) add = a[i][k - i] + a[j][k - j];
37 f[k][i][j] = max(f[k][i][j], f[k - 1][i][j]);
38 f[k][i][j] = max(f[k][i][j], f[k - 1][i - 1][j]);
39 f[k][i][j] = max(f[k][i][j], f[k - 1][i][j - 1]);
40 f[k][i][j] = max(f[k][i][j], f[k - 1][i - 1][j - 1]);
41 f[k][i][j] += add;
42 }
43 cout << f[len][n][n] << '\n';
44 return 0;
45 }
最后总结一下就结束这一整篇吧,太长了,.....我自己都懒得看
目前动态规划学了线性DP所包含的所有,树DP,也算是写了40到50多的题,现在不再像刚刚学DP时跟个傻子一样的情况了。这个用作启发的例题也就到此打住吧。
个人感觉混杂了不少也不多的例题,思路也算是理清了,怎么说,估计也不会有人看的...
最后感谢zbw的讲解,可以说我对DP的认识的转变就是从zbw开始的,至此。















 225
225











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









