








写在前面的话:
关于盲态下样本量再估计:
何为盲态下样本量再估计?在未揭盲情况下,我们不知道受试者属于哪一分组,因此我们不能基于期中数据估算此时的处理效应。其次,如前一节所述:盲态条件下的样本量再估计对I类错误的影响微乎其微,可忽略不计,故无需对检验水准进行校正。因此,这意味着我们不能用上一节给大家介绍的内容来进行样本量再估计。
那么究竟在盲态下如何进行?Wittes and Brittain(1990) 和Gould 及Shih(1992, 1998)等统计学家已经提出相应的方法。本节介绍两种样本量再估计方法,分别是基于合并正态分布的峰度、EM算法。
关于本篇文章:
本系列第三篇文章,主要聚焦于盲态下样本量再估计。本篇文章结构如下:
· 背景
· 盲态下的样本量再估计
· 模拟试验
· 总结与讨论
—— 正文开始 ——
01
背景
在临床试验中,样本量估计是通过预先设置一个组间差异和主要终点指标的变异来完成的。由于指定变异时,我们缺乏足够把握,因此常常会导致样本量估计的不够准确。此外,为了保持试验的最大完整性,若试验采用双盲设计,则建议在不揭盲的情况下进行样本量再估计。
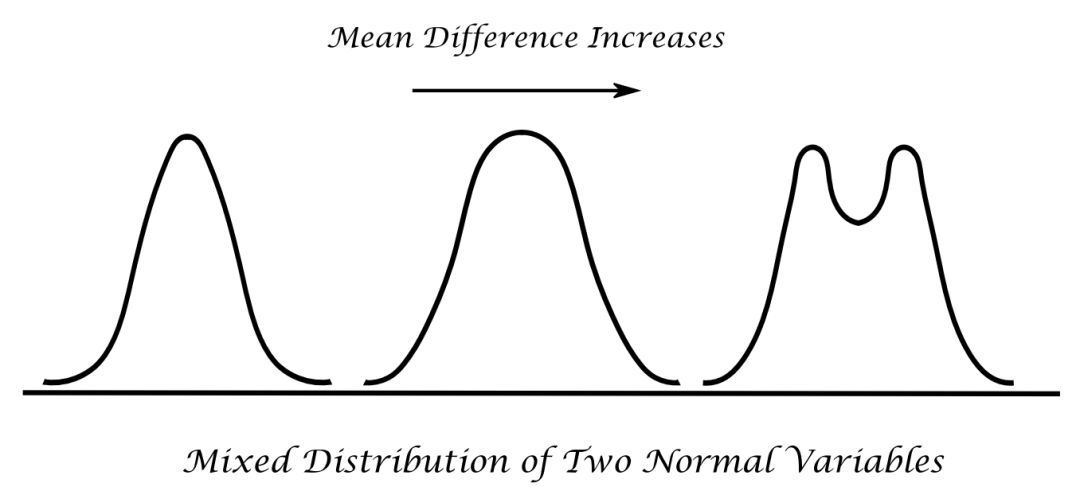
大家可能会认为,我们不能基于合并(盲态下不知道分组情况)数据精确估算试验药和对照药之间的差异。但真实情况截然相反。这是因为如果两个均值之差足够大,则来自两个不同的正态分布的混合数据将具有两种模式,而如果两组均值相同则将具有单一模式。从下图就可以看出这一现象。因此,盲态下也完全可以进行样本量再估计。
02
盲态下的样本量再估计
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









