






 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| [Topics] [Projects] [Downloads] [People] [Publications] [Press] [Events] | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Automatic Audio Segmentation: Segment Boundary and Structure Detection in Popular Musicby Ewald Peiszer ([firstname].peiszer@gmx.at) Automatic audio segmentation aims at extracting information on a songs structure, i.e., segment boundaries, musical form and semantic labels like verse, chorus, bridge etc. This information can be used to create representative song excerpts or summaries, to facilitate browsing in large music collections or to improve results of subsequent music processing applications like, e.g., query by humming. This thesis features algorithms that extract both segment boundaries and recurrent structures of everyday pop songs. Numerous experiments are carried out to improve performance. For evaluation a large corpus is used that comprises various musical genres. The evaluation process itself is discussed in detail and a reasonable and versatile evaluation system is presented and documented at length to promote a common basis that makes future results more comparable. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
AlgorithmPhase 1: Boundary detection This phase tries to detect the segment boundaries of a song, i.e., the time points where segments begin and end. The output of this phase is used as the input for the next phase. The classic similarity matrix / novelty score approach has been used. In addition, various attempts to further improve the result have been carried out. The figure below shows the novelty score plot of KC and the Sunshine Band: That’s the Way I Like It. Vertical dotted lines indicate groundtruth boundaries. 
Note that automatic boundary extraction worked very well for this song: all major segment boundaries have been found (red askerisks). 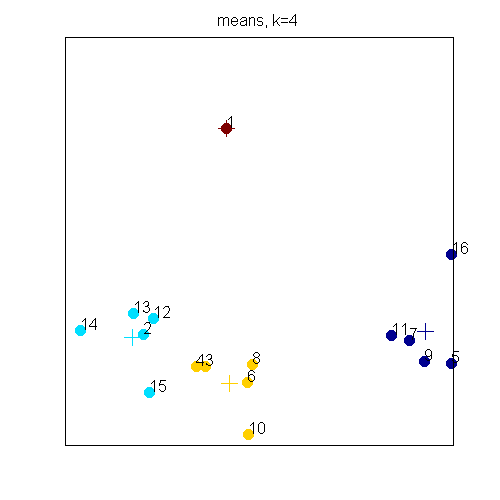 Phase 2: Structure detection This phase tries to detect the form of the song, i.e., a label is assigned to each segment where segments of the same type (verse, chorus, intro, etc.) get the same label. The labels themselves are single characters like A, B, C, and thus not semantically meaningful. The songs have been fully annotated. Both sequential-unaware approaches and an approach that takes temporal information into account have been used. In addition, cluster validity indices have been employed to find the correct number of segment types for each song. The right figure (click to enlarge) shows clustering result of KC and the Sunshine Band: That’s the Way I Like It song segments. Numbered circles indicate segments, crosses mark cluster centroids. The source code of the algorithm implemented in Matlab can be obtain from the download section. For information on how to use it, please refer to the included README file (or ask the author if there are still problems). | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
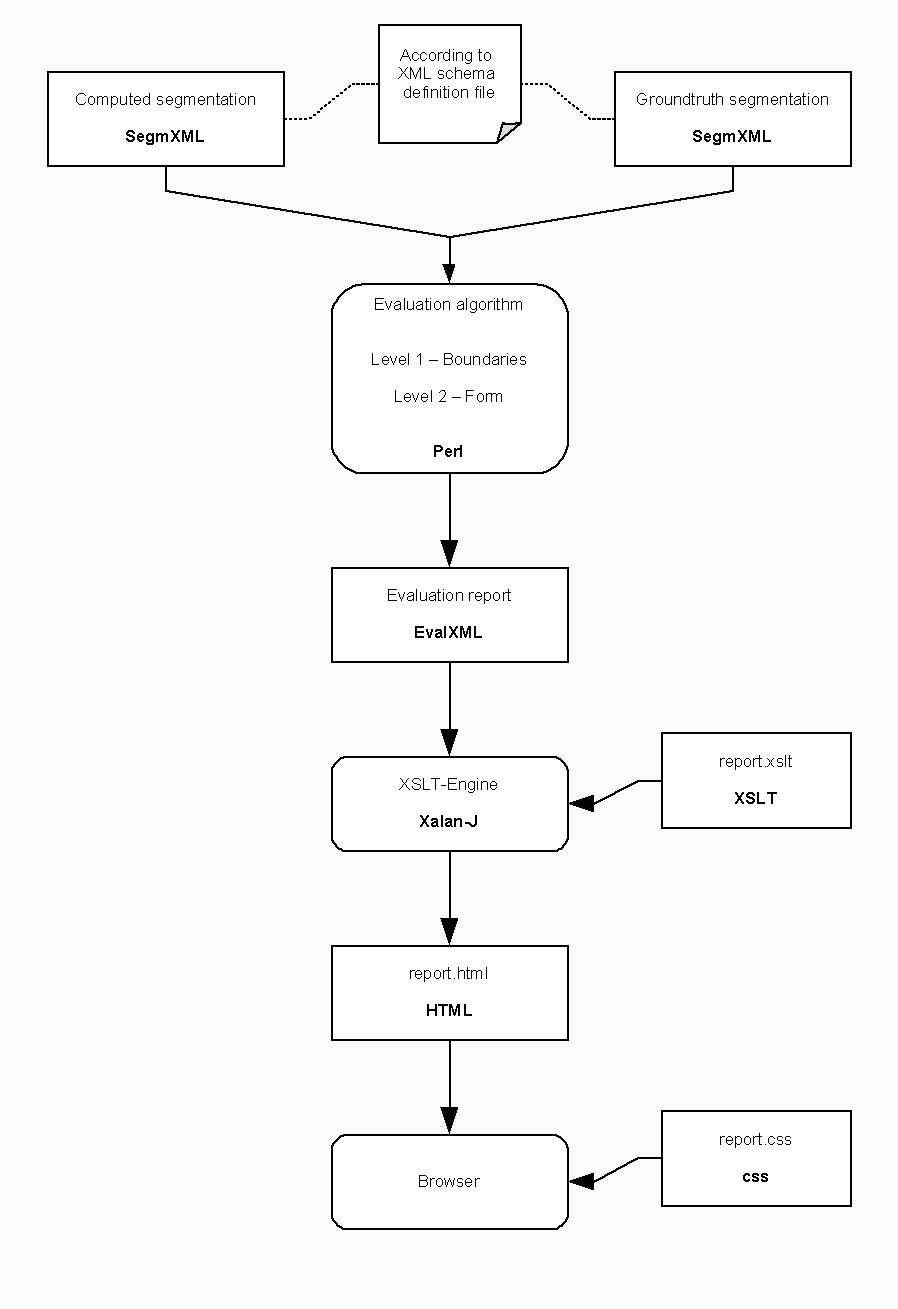 Evaluation setupA significant amount of time has been invested in careful considerations about good evaluation. An easy-to-use evaluation program that produces both appealing and informative HTML reports has been designed and implemented. You can download the source code from the download section at the bottom of this page. A novel file format for audio segmentations (SegmXML) has been introduced. This format can contain information about hierarchical segments and alternative labels. See the example groundtruth file for Alanis Morisette: Thank You. A corresponding XML schema definition file for validating SegmXML files is available, too.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Selected evaluation reportsThe evaluation reports of the following algorithm runs are available. Note that this table corresponds to Table 3.1 of the thesis. For an explanation of symbols and abbreviations used please refer to the thesis.
MFCC40 and CQT1 are names of two parameter value sets that are explained in Table 3.2 of the thesis. MFCC40 uses Mel Frequency Cepstrum Coefficients features whereas CQT1 employs Constant Q Transform with such parameter values for fundamental frequency, maximal frequency and number of bins that the feature vectors model the semitones of seven octaves, each octave containing twelve notes. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
CorpusThe corpus on which this work is based contains 94 songs of various genres (Rock, Pop, Hiphop, RNB, etc). Final algorithm runs are conducted on a 109 song corpus which is the largest corpus used so far in this research field. The following table contains all songs of the corpus. Unfortunately, the demonstration songs cannot be published due to copyright issues.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
ConclusionsBoth boundary detection and structure extraction are quite acceptable, yet improvable. The algorithm, however, proved to be robust in a negative and positive sense: Many experiments conducted with various parameter settings and heuristics applied did not lead to a statistically significant improvement of the mean performance. On the other hand, cross validation and the performance on an independent test set did not show any decline in performance either. Thus, the algorithm presented seems suitable to be applied to a wide range of songs and genres. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Downloads
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
转载于:https://www.cnblogs.com/daleloogn/p/4267923.html















 2830
2830

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









