







各位知乎儿大家好,这是<EYD与机器学习>专栏迁移学习系列文章的第四篇文章,在上次的文章中我们介绍了一个迁移学习与对抗网络结合的算法框架(笨笨:<EYD与机器学习>迁移学习:DANN域对抗迁移网络),这次我们依旧为大家介绍一篇关于对抗网络和迁移学习结合的论文:Partial Transfer Learning with Selective Adversarial Networks(SAN)[1]。这篇文章是由清华大学的龙明盛老师发表的,文中要解决的问题和我们之前介绍的论文的工作都有所不同,下面我来详细为大家介绍。
一、简介
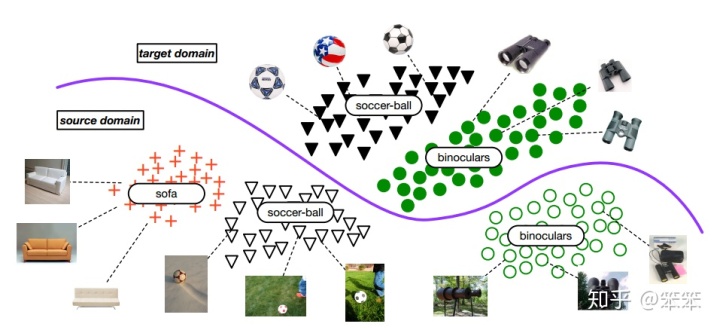
之前介绍的迁移学习方法的前提是源域标记空间和目标域标记空间相同,也就是说源域和目标域的类别数量和内容都是相同的,但是在如今这个大数据时代这个假设过于严格了。网络上或者数据库里的数据是很丰富的,类别通常都会远远超过目标域的类别数量。例如我们想要构建一个图像的分类器,对一百类图像进行分类。当训练数据不足时我们可以借用ImageNet里的图片进行预训练,这就是一个迁移学习的过程,但是问题是ImageNet中有那么多类图像,到底哪些可以拿来进行预训练呢?一般情况下我们都是根据自己的经验为当前的目标任务选择可以迁移的源域,但是我们只能是以各种距离或者相似度来作为选择源域的依据,这样不仅会有很大误差,而且还会丢掉很多有用的信息。
针对上述问题,作者提出了选择式对抗网络,让网络能够自己为目标域选择合适的源域类别进行迁移。 不再假设源域和目标域的标记空间相同,而是假设目标域的标记空间是源域标记空间的一个子空间。如下图所示:
下面我们来学习一下PTL的具体工作原理。
二、Partial Transfer Learning with Selective Adversarial Networks(SAN)
选择式对抗网络(SAN)属于无监督迁移学习,即训练时目标域无带标记样本,但是源域有丰富的带标记样本,同时目标域的类别是源域类别的子集。其符号定义如下:
-
:表示源域数据
-
:表示目标域数据
-
:表示特征提取器
-
:表示类别预测器
-
:表示域判别器
-
:表示源域中的类别数
-
:表示目标域中的类别数
下面是SAN的网络结构:
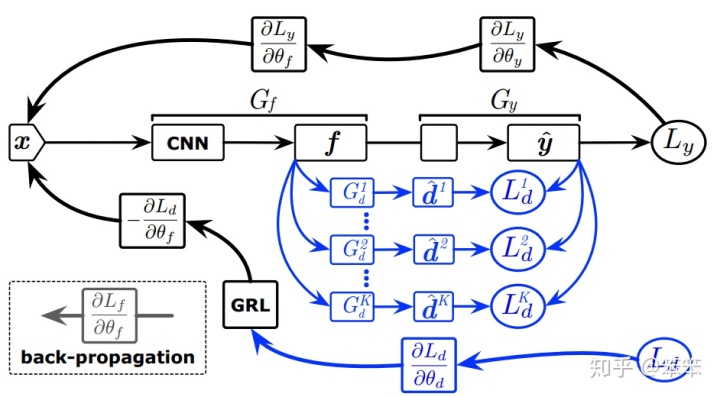
在图中
当
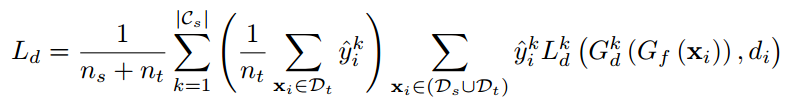
从上述过程中可以看出,在训练时是很依赖对目标域的预测结果的,然而目标域本身又是无标记的,无法直接训练,所以为了提高目标域预测结果的准确性,作者提出了条件熵这一损失函数:
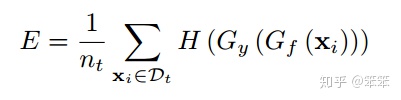
在上式中,样本
因为
最小化条件熵的目的是让当前的预测结果
此外,和上一篇文章介绍的相同,源域数据是有标记的所以在训练类别预测器的时候是一个有监督过程,因此整个网络的损失函数为:
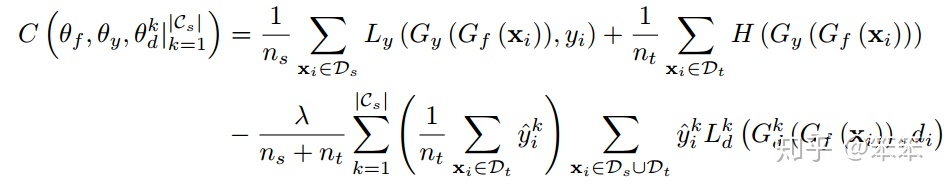
由于是对抗网络,所以在训练时还是分成两步:

训练终止时会达到两个效果:第一,域判别器不能判断出输入给网络的样本时源域还是目标域;第二,类别预测器可以同时对源域样本和目标域样本进行分类。
SAN对于源域类别对于目标域类别的情况比其他迁移学习网络确实好了很多,下面是作者的实验结果:
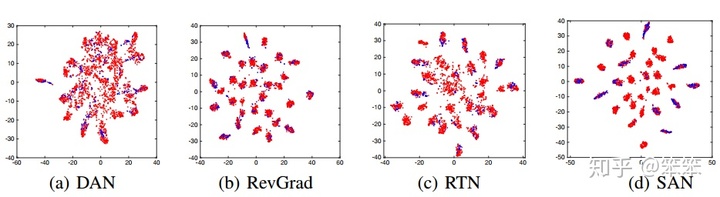
图中蓝色点表示目标域样本,红色点表示源域样本,可以看出源域的类别比目标域多(簇的数量表示类别数量),SAN的适配结果是最好的。
三、总结
可以看出,SAN的本质和之前介绍的DANN区别不大,不过它在对抗网络这个框架下引入了源域类别选择的功能,能够在无目标域标记的情况下自主选择源域对应的样本进行迁移,为每个类别分别构建域判别器,不再将整个源域的各个类混在一起,剔除了源域中的不相关类,减少了负迁移。但是SAN由于设计了多个对抗网络(每个类一个域判别器),导致算法在类别比较多的时候没有办法很好的收敛。
本次文章中如果有哪些错误或者不严谨的地方,希望大家批评指正,后续我们会继续向大家介绍关于迁移学习的文章。
——Double编辑
参考文献
[1]
https://arxiv.org/pdf/1707.07901.pdfarxiv.org














 6636
6636











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









