






Hello,大家好,这里是糖葫芦喵喵~!
ようこそ実力至上主义のCS231n教室へ
已经进入了糖葫芦贩卖的季节了呢^ ^!北方的同学们已经享受上了暖气,南方的同学们请抱好你们的1080Ti来取暖(虽然我们在本次作业中用不到GPU
那么,第二篇CS231n 2017 Spring Assignment2 就要开始了~!
喵喵的代码实现:Observerspy/CS231n,欢迎watch和star!
Observerspy/CS231ngithub.com
视频讲解CS231n Assignment2:
Assignment 2-AI慕课学院www.mooc.ai
Part 1 Fully-connected Neural Network
上一次的作业中我们实现了一个两层的神经网络,这里主要是对代码进行模块化,把每一层都抽象出来,分别实现每一层的前向和反向部分。
1 Affine layer(线性层)
前向:wx+b,很简单,np.dot()就行了
反向:db就是上游传回来的值dout直接sum起来,dw是x和dout相乘(就是线性wx+b对w求导嘛),dx是w和dout相乘,请注意dw和dx的形状,到底是谁和谁(或是谁的转置)乘,一定要搞清楚!dw和w形状一致,dx和x形状一致,所以算一下形状就很好确定啦!
2 ReLU
前向:ReLU不过就是和0比较,输出大的那个,np.maximum()搞定
反向:反向只向后传递在前向时输出大于0的位置(梯度为1)的dout,其他的由于小于0所以梯度为0
dx = (x > 0) * dout3 affine_relu
就是把上面两个连在一起,已经为你实现好了,读一下吧!
4 loss
loss上次我们也做过了,忘记了的可以回去看一看。
5 Two-layer network
结构:affine - relu - affine - softmax
基本的模块上面已经做好了,下面组合在一起就好:
参数初始化===>前向 + Loss===>反向
注意w初始化np.random.normal()的三个参数的意义!尤其是形状一定要把握好。
跑一下你的模型,10epoch可以在validation上得到50%左右的结果。
6 Multilayer network
结构:{affine - [batch norm] - relu - [dropout]} x (L - 1) - affine - softmax
无非就是套层循环,在循环时要想一想哪些是可以循环的,哪些是不行的(最后一层)
循环时一定要注意用的参数的名字,一定要注意i和你的参数名字的关系!
反向小技巧,逆序循环:
for i in range(self.num_layers - 1, 0, -1):跑一下模型,你可以调一调参数,20epoch就过拟合了
7 SGD+Momentum
官方文档给了很多梯度更新的说明,很详细喵喵就不多说了。
Momentum:mu是超参,多用0.9,交叉验证可以用[0.5, 0.9, 0.95, 0.99]
# Momentum update
v = mu * v - learning_rate * dx # integrate velocity
x += v # integrate position 8 RMSProp and Adam
RMSProp:decay_rate是超参,多用[0.9, 0.99, 0.999],eps是平滑项,范围为1e-4 ~ 1e-8
# RMSProp update
cache = decay_rate * cache + (1 - decay_rate) * dx**2
x += - learning_rate * dx / (np.sqrt(cache) + eps)Adam:推荐超参数eps = 1e-8, beta1 = 0.9,beta2 = 0.999
# Adam update
m = beta1*m + (1-beta1)*dx
v = beta2*v + (1-beta2)*(dx**2)
x += - learning_rate * m / (np.sqrt(v) + eps)最终调一调参数,可以在validation上得到55%左右的结果。
Part 2 Batch Normalization
这是我们接触到的第一个黑魔法!
这个黑魔法用在卷积层/全连接层后,激励函数前。
这个黑魔法可以有效减缓过拟合,减小不好的初始化影响以及你可以用大一点的学习率了!
前向:
(训练)非常经典的一张图,其中

简单说前向就是计算minibatch的均值和方差,然后对minibatch做normalize和scale、shift
(测试)测试的时候没有minibatch啊,怎么来计算均值和方差呢?这里我们的解决方案是通过使用基于momentum的指数衰减,从而估计出均值和方差:
running_mean = momentum * running_mean + (1 - momentum) * sample_mean
running_var = momentum * running_var + (1 - momentum) * sample_varmomentum超参,一般是0.9
通过这样的方式在训练时不断更新预测的均值(running_mean)和方差(running_var),测试时直接用这两个数计算normalize和scale、shift,和训练时的计算方式一样。
反向:
我们需要求dx,dgamma和dbeta,前向时我们分了四步计算出了输出(对照图中公式,分别为mean,var,xhat和输出y),这里我们要反向去计算每个部分。
第四步:线性,因此 dxhat = dout * gamma;dgamma = sum(dout * xhat);dbeta = sum(dout)(具体形状一定要注意,为什么要sum呢,因为这两个学习的参数是一维的,类似神经元里的bias,注意axis参数的设置)
解决了gamma和beta,我们来分析dx是哪里来的。
根据公式,x和min,var,xhat都是相关的,因此,dx要由这三部分构成,分别求导
第三步:
第二步:
第一步:
m是什么,minibatch的大小,x的shape[0]。
那么我们把求dx转化为求上面三部分,dxhat已经有了,剩下要求dmean和dvar(同理,var和mean也都是一维的,所以要sum)
var只有第三步有贡献,直接求导 :
mean第二步第三步都有贡献,为两部分之和:
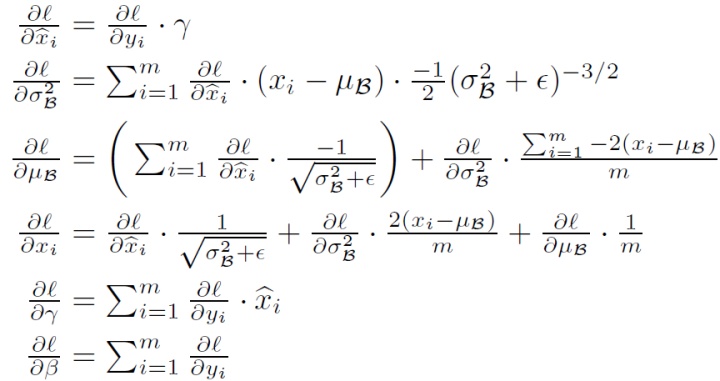
这样就终于通过公式则把dx求出来了,然后轻松愉快实现代码。其实作业要求的部分是通过链式法则直接计算,选作的部分是公式计算,不过公式计算的运算速度快一些,有兴趣的可以去试试。
最后把黑魔法放到网络里,看看变化吧!
Part 3 (inverted) Dropout
这又是一个有用的黑魔法!
这个黑魔法用在激励函数后。
这个黑魔法可以有效缓解过拟合。
其实原理很简单,就是以一定的概率选择使用一部分神经元。
inverted dropout通过多除一个p保证了训练预测分布的统一。
前向:
(训练)用mask选择神经元,有了mask元素乘一下就好了。
mask = (np.random.rand(x.shape[0], x.shape[1]) < p) / p(测试)当然是什么也不做了!
反向:
类似ReLU,不参与更新的部分都用mask去和dout相乘(元素乘)。
在刚才的网络里加上dropout黑魔法吧,你可以对比加与不加的效果。
休息一下!因为后面就是手撸CNN大boss啦!

Part 4 Convolutional Networks
古人云:学习CNN最好的方式就是手写一个CNN
是非常有道里的话!
那么就让我们开始挑战吧!(强烈推荐deeplearning.ai第四课CNN,第一周作业详细讲了怎么手撸CNN,不过那个作业给的循环太多,而本节作业是向量化的)
1 卷积核
(前向)
首先明确输入x和卷积核的形状(数量,通道,高,宽):
N, C, H, W = x.shape
F, C, HH, WW = w.shape(1) 确定输出的形状
pad参数: P,决定了你要在四周pad多少
stride参数:S,决定了卷积核每次移动多少
所以根据公式,可以直接计算输出out的形状(N,F,Hnew,Wnew),记得用0初始化
(2) zero padding
np.pad()就是实现这个功能的,请仔细阅读函数接受的参数意义。pad_width接受每个维度上前后pad的大小,当某一维度使用(pad,)表示前后都是pad大小(等于(pad, pad))
(3) 卷积操作
这里的卷积和通信原理里的卷积还是稍有区别的,在这里其实只是卷积核和相应的区域进行元素乘,然后求和,课程官网给的说明十分形象生动:

也就是每个卷积核分别在每个通道上和对应区域进行元素乘,然后求和,对应图中:
(-3(通道1元素乘后求和) + -1(通道2元素乘后求和) + 0 (通道3元素乘后求和))(三个通道求和) + 1(bias_0) = -3(out的第一个格子里的值)
所以,关键问题就是根据步长如何确定x对应区域,这里需要对Hnew(下标i)和Wnew(下标j)进行双循环:
x_mask = [:, :, i*stride:i*stride+HH, j*stride:j*stride+WW]选好区域直接和每个卷积(下标k)核作元素乘就行了,注意sum的时候我们其实是在(C, H, W)上作的,因此axis=(1, 2, 3)。这时候一个输出out[:, k , i, j]就计算好了。
所以上述一共套了i, j ,k三层循环,循环完毕后out再加上bias就行了。注意b的形状(F,),因此要先把b扩展成和out一样的形状:b[None, :, None, None](None相当于np.newaxis)
至此,前向计算完毕!
(反向)
首先明确我们要求什么。dx,dw和db。
(1) db
db最好求啊,直接就是sum(dout),还要和b的形状(F,)一致,所以axis=(0, 2, 3)
那么dx,dw到底是什么呢。其实dx和dw是另外两个卷积。只不过这次是换在dout的对应区域进行卷积操作了。这篇博客写的很详细,这里借用其几张图片:
(2) dx
dx对应区域 = dout对应区域和卷积核w进行卷积:
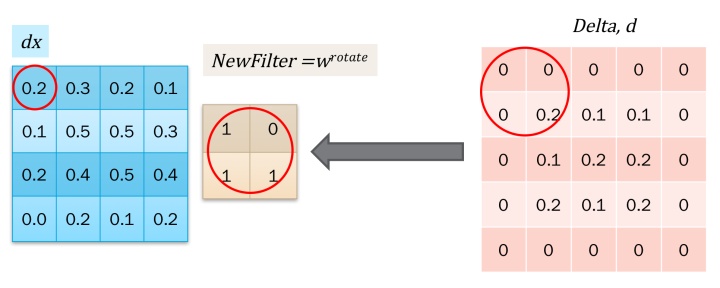
这个图中的是通过对dout进行padding然后和旋转180度的卷积核进行卷积计算的,实际上可以不这么麻烦。用dout中的每一个值和原卷积核进行元素乘,然后对dx的对应区域进行叠加就可以了。数学上是等价的:

如图所示,4*4的矩阵中每一个颜色对应dout中的一个值(共9种),粗体对应原卷积核。每一个蓝框对应一个dout值和w的元素乘操作。把重叠区域加起来后和上图结果一致。
卷积我们已经会了,剩下就是确定对应区域到底是什么了。
dx的形状是(N, C, H, W)
w的形状是(F, C, HH, WW)
dout的形状是(N,F,Hnew,Wnew)
对于每个样本(即对N循环,n为下标):
n,i,j将确定一个dout,确定后dout的形状变为(F,),因此和前向bias同理需要维度扩展为
[:, None, None, None],以保证和w的形状一致
dx的对应区域由n和x_mask(就是前向中的x对应区域)共同确定:
dx_mask[n, :, i*stride:i*stride+HH, j*stride:j*stride+WW]三层循环i,j,n完成卷积后,需要对pad过的dx进行解pad:
dx = dx_pad[:,:,pad:-pad,pad:-pad](3) dw
dw对应区域 = dout和x对应区域进行卷积:

对于每个卷积(即对F循环,k为下标):
x对应区域为(向前时已经给出了,就是那个x_mask)
k,i,j将确定一个dout,此时dout的形状为(N,),为了何x_mask一致同样需要扩展为
[:, None, None, None]
然后就可以三层循环i,j,k做卷积了,计算结果就是dw[k]。
OK,至此反向计算完毕!大功告成!
剩下一个简单的操作,pooling。
2 pooling
2.1 max pooling
(前向)
pooling同样有步长,确定输出形状的公式:
其中HH,WW是pooling的大小。
max pooling顾名思义就是取这个pooling大小区域内的max值。注意axis=(2, 3)。
(反向)
反向和ReLU、DropOut是类似的,也就是说只有刚才前向通过的才允许继续传递梯度。
那么我们需要记录max在区域里的位置,用temp_binary_mask表示:
x_padded_mask = x[:, :, i*stride:i*stride+pool_height, j*stride:j*stride+pool_width] #(:, :, HH, WW)
max_mask = np.max(x_padded_mask, axis=(2,3))
temp_binary_mask = (x_padded_mask == (max_mask)[:,:,None,None])max_mask形状是(HH, WW),为了和x_padded_mask形状对应也要扩展。
然后dout和这个temp_binary_mask元素乘即可。同样注意dout是由i,j确定的,因此形状需要扩展。
2.2 average pooling
附送一个average pooling,也很简单。
前向就是在pooling大小区域内求平均值。
反向就是把dout平均在pooling区域内。
3 CNN
结构:conv - relu - 2x2 max pool - affine - relu - affine - softmax
快把刚才完成的结构组合在一起吧!1epoch可以得到40%的准确率。
4 Spatial batch normalization
以前我们做的BN形状是(N, D),这里不过是将(N, C, H, W)reshape为(N*H*W, C)。因为spatial batch normalization computes a mean and variance for each of the C feature channels by computing statistics over both the minibatch dimension N and the spatial dimensions H and W.
需要用到np.transpose(),现将(N, C, H, W)变为(N, H, W, C),再reshape。反向也是同理。
至此,手撸CNN全部结束!
完结撒花!(并没有完结!
Part 5 Tensorflow on CIFAR-10
欢迎来到TensorFlow的世界,从此你可以告别复杂的反向传播推导了!
tensorflow入门资料回顾,在part D哦。
在这个世界中我们只需要考虑怎么样设计网络和loss就行了。
层,激励函数,Loss:https://www.tensorflow.org/api_guides/python/nn
优化器:https://www.tensorflow.org/api_guides/python/train#Optimizers
BN:https://www.tensorflow.org/api_docs/python/tf/layers/batch_normalization
这里强调一点,使用BN黑魔法时请务必注意:
A 在你的优化器上套上这两句:
# batch normalization in tensorflow requires this extra dependency
extra_update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(extra_update_ops):
train_step = optimizer.minimize(mean_loss)B 注意tf.layers.batch_normalization()中的is_training(是一个tf.placeholder)在训练和测试时的设置!如果你要使用dropout也是类似的。
你可以尝试各种各样的网络。这里喵喵10epoch在test达到了76.2%。相信你可以做得更好。
恭喜你达到了第二章的BOSS,下一次让我们来做一些有趣的事情吧!
じゃ、おやすみ~!
















 4111
4111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









