







人工智能咨询培训老师叶梓 转载标明出处
多模态图像生成是内容创作领域的热点技术,尤其在媒体、艺术和元宇宙等领域。该技术旨在模拟人类的想象力,将视觉、文本和音频等多种模态属性相关联,以生成图像。早期的方法主要侧重于单一模态输入的图像生成,例如基于图像、文本或音频的生成。这些方法在处理现实世界中更复杂的模态输入时受到限制。
香港科技大学(广州)的研究团队提出了一种名为ImgAny的新型多模态图像生成框架。这一框架无需训练,能够从语言、音频到视觉等多种模态中生成高质量图像,包括图像、点云、热成像、深度和事件数据等。ImgAny通过模仿人类的认知过程,实现了模态间的整合与协调,生成视觉上吸引人的图像。

ImgAny
ImgAny是一个端到端的多模态生成模型,它能够接受多达七种不同模态的输入,包括语言、音频和五种视觉模态(图像、点云、热成像、深度和事件数据)。这一框架的设计灵感来源于人类的认知过程,通过在实体和属性两个层面上整合多种输入模态,实现了无需特定调整的生成过程。
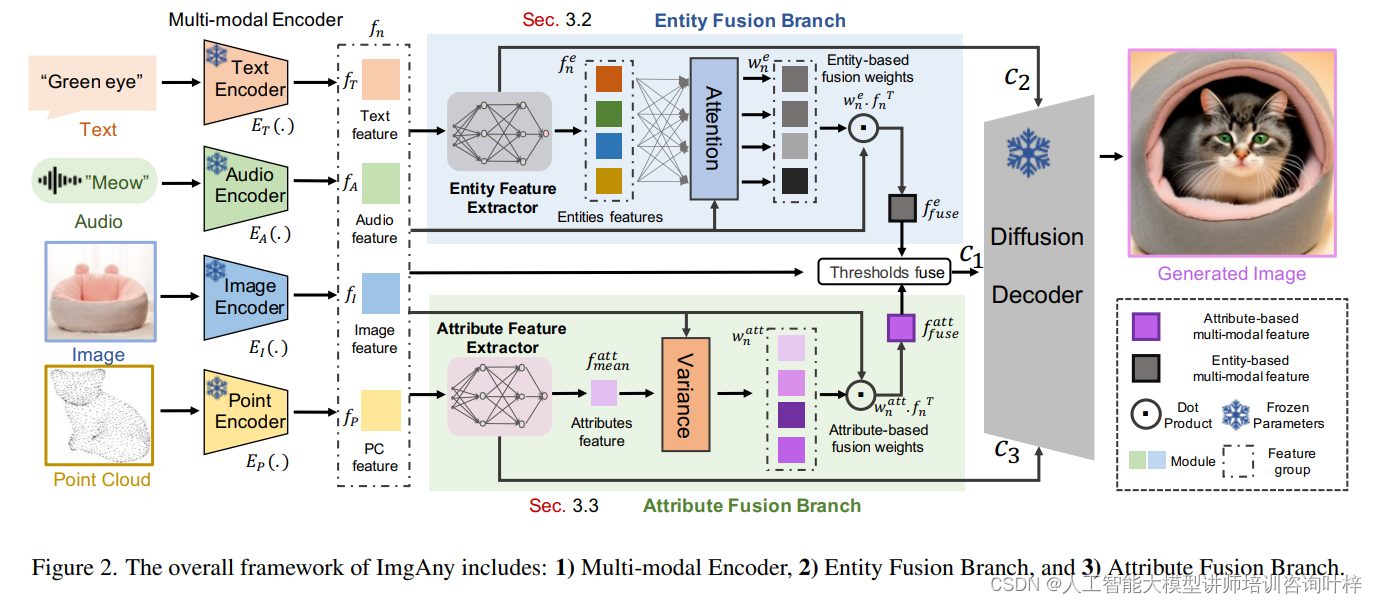
ImgAny的整体框架由三个主要部分组成,整体来看ImgAny的框架设计允许它灵活地处理多种模态输入,并通过实体和属性的融合,生成在视觉上具有吸引力且与输入条件一致的图像。
-
Multi-modal Encoder(多模态编码器):
这是ImgAny框架的第一部分,负责从各种模态输入中提取特征。对于给定的n种模态&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 693
693

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











