









SAST Weekly 是由电子工程系学生科协推出的科技系列推送,内容涵盖信息领域技术科普、研究前沿热点介绍、科技新闻跟进探索等多个方面,帮助同学们增长姿势,开拓眼界,每周更新,欢迎关注!欢迎愿意分享知识的同学投稿至 eesast@mail.tsinghua.edu.cn , 期待你的作品!



什么是YOLO

YOLO是“You Only Look Once”的简称,是继R-CNN,fast-RCNN 和 faster-RCNN之后的又一个深度学习目标检测框架。YOLO 的核心思想就是利用整张图作为网络的输入,直接在输出层回归边界框的位置和类别。相较于之前的框架,YOLO的速度要快上许多,不过准确率仍有待提升(不过在后人的努力下,YOLO的准确率较最初已经有了很大进步)。


YOLO的网络结构

YOLO的整体架构如上图所示,包含了三个部分:(1)将输入图像的大小调整为448×448(2)在图像上运行单个卷积网络(3)根据模型的置信度对得到的检测进行阈值化。

检测网络包括24个卷积层和2个全连接层,具体细节可以参看上图。YOLO网络借鉴了GoogLeNet分类网络结构。不同的是,YOLO未使用inception module。

具体实现细节(部分)
YOLO将输入图像分成SxS个格子,每个格子负责检测‘落入’该格子的物体。若某个物体的中心位置的坐标落入到某个格子,那么这个格子就负责检测出这个物体。
每个格子输出B个bounding box的信息,以及C个物体属于某种类别的概率信息。其中,每个bounding box包含了x,y,w,h以及confidence共5个数据,其中x,y是指当前格子预测得到的物体的bounding box的中心位置的坐标。w,h是bounding box的宽度和高度。Confidence反映当前bounding box是否包含物体以及物体位置的准确性,计算公式如下图所示:
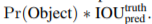
这里,IOU(intersection over union)为预测bounding box与物体真实区域的交集面积
因此,YOLO网络最终的全连接层的输出维度是 S*S*(B*5 + C)。YOLO论文中,作者训练采用的输入图像分辨率是448x448,S=7,B=2;采用VOC 20类标注物体作为训练数据,C=20。因此输出为7*7*(20 + 2*5)=1470维的张量。
效果
下表给出了YOLO与其他物体检测方法,在检测速度和准确性方面的比较结果(使用VOC 2007数据集)。
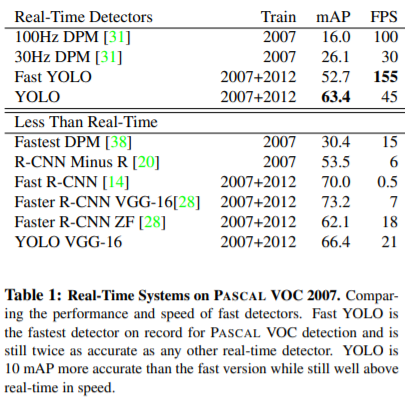
不难看出,在该数据集下,YOLO的速度比R-CNN系列的框架要快上非常多。
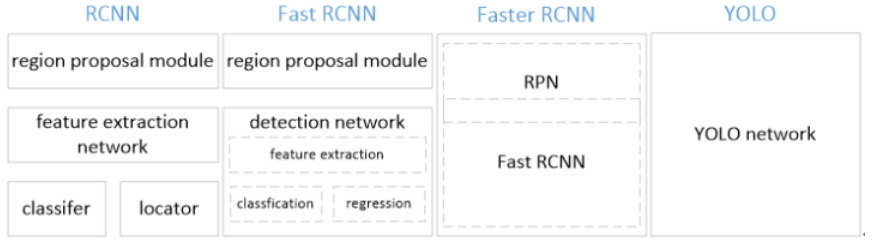
优点&缺点
先说说优点,YOLO最为突出的优点就是快。结构的简单使得YOLO在titan x GPU上,在保证检测准确率的前提下(63.4% mAP,VOC 2007 test set),可以达到45fps(frame per second)的检测速度。
YOLO的第二个优点是背景误检率低。YOLO在训练和推理过程中能‘看到’整张图像的整体信息,而基于region proposal的物体检测方法(如R-CNN/fast RCNN),在检测过程中,只能‘看到’候选框内的局部图像信息。
当然,YOLOv1的缺点同样存在。比如,YOLO对相互靠的很近的物体,还有很小的群体检测效果不好,这是因为一个网格中只预测了两个框,并且只属于一类。同时,泛化能力偏弱也是YOLOv1的缺点之一。
运行YOLOv3的实例
说了那么多,那我们赶紧来试一试这个程序吧!在https://pjreddie.com/darknet/yolo/上我们可以看到作者提供的使用这些代码的方式。如果懒得点开看英文也没关系,我在下面示范一下该如何进行操作,代码如下:
$git clone https://github.com/pjreddie/darknet
$cd darknet
$cd make
接下来是下载预训练的数据的文件,分为正常(237MB)和迷你版,下载指令如下:(这是linux指令,如果是windows直接到这个网页上下载即可,但要把这个文件放在darknet的子目录下)
$wget https://pjreddie.com/media/files/yolov3.weights
$wget https://pjreddie.com/media/files/yolov3-tiny.weights
然后输入下面的代码开始运行(当然你要把dog换成其他的什么诸如“data/eagle.jpg, data/person.jpg”也完全没所谓):
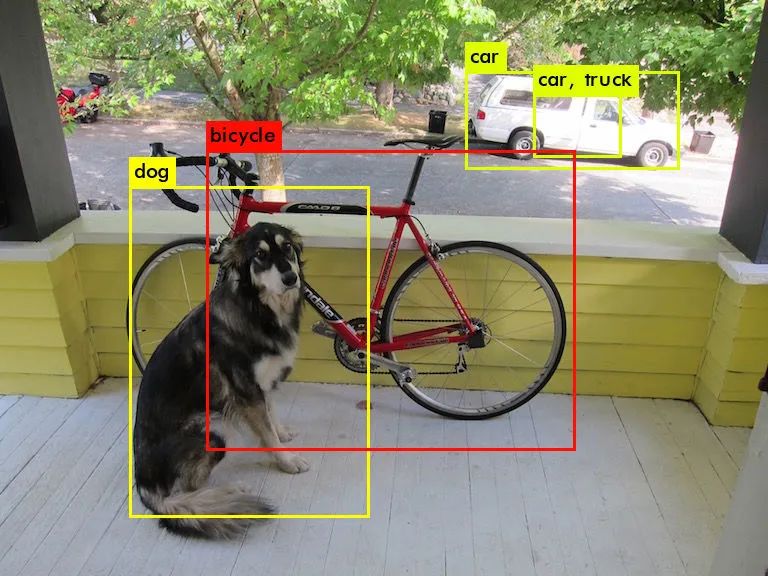
$./darknet detect cfg/yolov3-tiny.cfg yolov3-tiny.weights data/dog.jpg
当我们看到下面的输出时说明我们成功运行了文件并生成了prediction.png,这里的输出给出了置信度的信息,由于这里我使用的是mini所以置信度不高,但如果使用正常版的话是可以正确预测,并且置信度是很高的,大概在90%以上。
Loading weights from yolov3-tiny.weights...Done!
data/dog.jpg: Predicted in 1.042714 seconds.
dog: 57%
car: 52%
truck: 56%
car: 62%
bicycle: 59%
下面分别展示一下使用正常的预处理weights和tiny-weights的生成的图片:
买家秀

卖家秀
写在最后
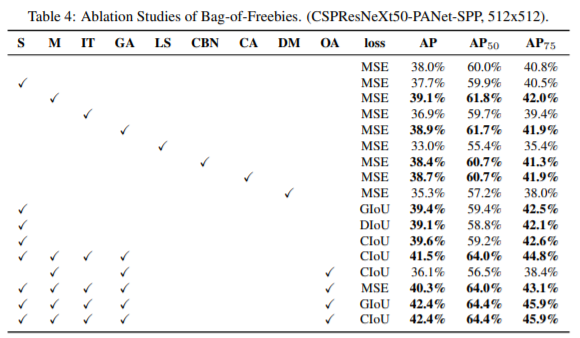
值得一提的是,就在几天前,YOLOv4已经问世,其在COCO数据集上的表现较YOLOv3也有了非常大的提升。在这个网络中,作者用到了非常多的tricks,比如Mosaic数据增强,Cross mini-batch Normal(跨最小批的归一化)等手段来提升网络的性能。这里我放一张论文中使用的图来让大家直观感受一下作者的码力。
对YOLOv4感兴趣的同学可以去https://arxiv.org/pdf/2004.10934.pdf进行下载。其代码也已经放在了github上:https://github.com/AlexeyAB/darknet,感兴趣的同学可以去跑一跑看~
参考文献:
1.You Only Look Once: Unified, Real-Time Object Detection by Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi(https://arxiv.org/abs/1506.02640)
2.YOLOv4: Optimal Speed and Accuracy of Object Detection Alexey Bochkovskiy et.al

撰稿:郑荣坤
审核:孙志尧
















 988
988











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









