









YOLOV2、YOLO9000论文连接:https://arxiv.org/abs/1612.08242
YOLOv2主要是改进原有的YOLO算法,2017年,作者 Joseph Redmon 和 Ali Farhadi 在 YOLOv1 的基础上,进行了大量改进,提出了 YOLOv2 和 YOLO9000,重点解决YOLOv1召回率和定位精度方面的不足。
YOLO的缺点:
- 对相互靠近的物体,以及很小的群体检测效果不好,这是因为一个网格只预测了2个框,并且都只属于同一类;
- 对不常见的角度的目标泛化性能偏弱;
- 定位不准确,尤其是大小物体的处理上,还有待加强;
- 端对端网络在前期训练时非常困难,很难收敛;
- 预训练的输入224x224,预测的输入448x448,模型需要适应图像分辨率的改变;
YOLOv2的改进:


1、Batch Normalization(批归一化)
- 对网络的每一层的输入(每个卷积层后)都做了归一化,这样网络就不需要每层都去学数据的分布,收敛会更快;
- map得到2%的提升;
- 对模型起到正则化的效果;
- 不需要再使用dropout层;

2、High Resolution Classifier(更高分辨率的分类器)
- YOLOv1使用的是224x224的输入,在ImageNet上进行预训练;
- YOLOv2则将预训练分成两步:
先用224x224的输入从头开始训练网络,大概160个epoch,然后再将输入调整到448x448,再训练10个epoch,然后再fine-tuning自己的数据; - map提高了4%;

3、Anchor Boxes
- 原来的YOLO是利用全连接层直接预测bounding box的坐标,而YOLOv2借鉴了Faster R-CNN的思想,引入anchor;
- 首先将原网络的全连接层和最后一个pooling层去掉;
- 缩减网络,由448x448–>416x416,最终输出13x13的feature map;
- 检测的box变多,提高Object的定位准确率,YOLO(bounding box):7x7x2=98,YOLOv2(anchor box,每个box预测的5个值:tx,ty,tw,th和to):13x13x5=845;

4、Dimension Clusters
- 利用K-means聚类(用欧式距离来衡量差异)对训练集的bounding boxes做聚类,计算出更好的Anchor模板;
- 通过IOU定义距离函数,使得误差和box的大小无关:
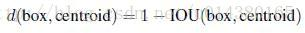
- 根据模型复杂度与recall,选择了K=5


5、Direct location prediction
- Faster R-CNN 算法中,是通过预测 bounding box 与 ground truth 的位置偏移值tx,ty间接得到bounding box的位置
- 由于tx,ty没有限制,会导致每个位置预测的边界框可以落在图片任何位置,这会导致模型的不稳定性,其公式如下:
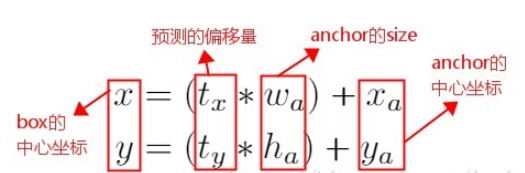
改进为: - 预测边界框中心点相对于该网格左上角坐标(Cx,Cy)的相对偏移量,同时为了将bounding box的中心点约束在当前网格中;
- 使用 sigmoid 函数将tx,ty(tx,ty是预测的关于anchor的偏移量)归一化处理,将值约束在0-1,这使得模型训练更稳定;
- 即每个anchor只负责预测目标中心点落在的那个grid cell区域的目标;
- to也是需要用sigmoid函数进行限制的;

- cx和cy表示中心点落在的那个grid cell与图像左上角的横纵坐标距离,黑色虚线框是bounding box,蓝色矩形框就是预测的结果。

6、Fine-Graind Features
结合底层的信息
- 输出13x13,融合相对更低层的26x26分辨率的特征图;
- 通过passthrough layers来实现,能将相对底层的特征图与高层的特征图进行融合,提升小目标的检测效果;
- 宽高变为原来的1/2,深度变为原来的4倍,26x26x64 —>13x13x256
,将13x13x256与13x13x1024进行融合—>13x13x1280,与论文中有所不同,作者的源码加入了一个1x1的卷积层;



7、Multi-Scale Training
多尺度训练
- 将图片缩放到不同的尺寸训练,提升鲁棒性;
- 每迭代10个batch,就将网络的输入尺寸进行随机选择(32的倍数);

8、网络结构的改进
-
19个卷积层,5个池化层;
-
输入416x416x3,输出13x13x125(125=5x25=5x(20+4+1),5个先验框,20个类别,4个坐标值,1个置信度)
-
去掉最后一个卷积层;
-
添加3个3x3的卷积层(每个卷积层有1024个filter),最后连接一个1x1的卷积层,1x1卷积的filter个数根据需要检测的类来定(每个grid cell5个box=5x(5+20)=125)。
即:

-
每一个convolutional都是由conv2d + BN + LeakyReLu 组成;
参考博主:https://blog.csdn.net/u014380165/article/details/77961414
参考视频:https://www.bilibili.com/video/BV1yi4y1g7ro?p=2














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









