







第七章 反向传播算法
The longer you can look back, the farther you can look forward. - 丘吉尔
第 6 章我们已经系统地介绍完基础的神经网络算法:从输入和输出的表示开始,介绍感知机的模型,介绍多输入、多输出的全连接网络层,然后扩展至多层神经网络;介绍了针对不同的问题场景下输出层的设计,最后介绍常用的损失函数,及实现方法。
本章我们将从理论层面学习神经网络中的核心算法之一:反向传播算法(Backpropagation,BP)。实际上,反向传播算法在 1960 年代早期就已经被提出,然而并没有引起业界重视。1970 年,Seppo Linnainmaa 在其硕士论文中提出了自动链式求导方法,并将反向传播算法实现在计算机上。1974 年,Paul Werbos 在其博士论文中首次提出了将反向传播算法应用到神经网络的可能性,但遗憾的是,Paul Werbos 并没有后续的相关研究发表。实际上,Paul Werbos 认为,这种研究思路对解决感知机问题是有意义的,但是由于人工智能寒冬,这个圈子大体已经失去解决那些问题的信念。直到 10 年后,1986 年,Geoffrey Hinton 等人在神经网络上应用反向传播算法 (Rumelhart, Hinton, & Williams,1986),使得反向传播算法在神经网络中焕发出勃勃生机。
有了深度学习框架自动求导、自动更新权值的功能,算法设计者几乎不需要对反向传播算法有深入的了解也可以搭建复杂的模型和网络,通过优化工具方便地训练网络模型。但是反向传播算法和梯度下降算法是神经网络的核心算法,深刻理解其工作原理十分重要。我们先回顾导数、梯度等数学概念,然后推导常用激活函数、损失函数的梯度形式,并开始逐渐推导感知机、多层神经网络的梯度传播方式。
7.1 导数与梯度
在高中阶段,我们就接触到导数(Derivative)的概念,它被定义为自变量𝑥在
x
0
x_{0}
x0处产生一个微小扰动∆𝑥后,函数输出值的增量∆𝑦与自变量增量∆𝑥的比值在∆𝑥趋于 0 时的极限𝑎,如果存在,𝑎即为在𝑥0处的导数:
a
=
lim
Δ
x
→
0
Δ
y
Δ
x
=
lim
Δ
x
→
0
f
(
x
+
x
0
)
−
f
(
x
)
Δ
x
a=\lim _{\Delta x \rightarrow 0} \frac{\Delta y}{\Delta x}=\lim _{\Delta x \rightarrow 0} \frac{f\left(x+x_{0}\right)-f(x)}{\Delta x}
a=Δx→0limΔxΔy=Δx→0limΔxf(x+x0)−f(x)
函数的导数可以记为
f
′
(
x
)
f^{\prime}(x)
f′(x)或
d
y
d
x
\frac{d y}{d x}
dxdy。从几何角度来看,一元函数在某处的导数就是函数的切线在此处的斜率,函数值沿着𝑥方向的变化率。考虑物理学中例子:自由落体运动的位移函
数的表达式
y
=
1
2
g
t
2
y=\frac{1}{2} g t^{2}
y=21gt2,位移对时间的导数
d
y
d
t
=
d
1
2
g
t
2
d
t
=
g
t
\frac{d y}{d t}=\frac{d \frac{1}{2} g t^{2}}{d t}=g t
dtdy=dtd21gt2=gt,考虑到速度𝑣定义为位移的变化率,因此𝑣 = gt,位移对时间的导数即为速度。
实际上,(方向)导数是一个非常宽泛的概念,只是因为我们以前接触到的函数大多是一元函数,自变量∆𝑥只有 2 个方向:𝑥+,𝑥−。当函数的自变量大于一个时,函数的导数拓展为函数值沿着任意∆𝒙方向的变化率。导数本身是标量,没有方向,但是导数表征了函数值在某个方向∆𝒙的变化率。在这些任意∆𝒙方向中,沿着坐标轴的几个方向比较特殊,此时的导数也叫做偏导数(Partial Derivative)。对于一元函数,导数记为 d y d x \frac{d y}{d x} dxdy;对于多元函数的偏导数,记为 ∂ y ∂ x 1 , ∂ y ∂ x 2 , … \frac{\partial y}{\partial x_{1}}, \frac{\partial y}{\partial x_{2}}, \ldots ∂x1∂y,∂x2∂y,…等。偏导数是导数的特例,也没有方向。
考虑为多元函数的神经网络模型,比如 shape 为[784, 256]的权值矩阵 W,它包含了784×256 个连接权值,我们需要求出 784*256 个偏导数。需要注意的是,在数学公式中,我们一般要讨论的自变量是𝒙,但是在神经网络中,𝒙一般用来表示输入,比如图片,文本,语音数据等,网络的自变量是网络参数集𝜃 = {𝑤1, 𝑏1, 𝑤2, 𝑏2, … },我们关心的也是误差对网络参数的偏导数
∂
L
∂
w
1
,
∂
L
∂
b
1
\frac{\partial \mathcal{L}}{\partial w_{1}}, \frac{\partial \mathcal{L}}{\partial b_{1}}
∂w1∂L,∂b1∂L等。它其实就是函数输出ℒ沿着某个自变量𝜃𝑖变化方向上的导数,即偏导数。利用梯度下降算法优化网络时,需要求出网络的所有偏导数。我们把函数所有偏导数写成向量形式:
∇
L
=
(
∂
L
∂
θ
1
,
∂
L
∂
θ
2
,
∂
L
∂
θ
3
,
…
∂
L
∂
θ
n
)
\nabla \mathcal{L}=\left(\frac{\partial \mathcal{L}}{\partial \theta_{1}}, \frac{\partial \mathcal{L}}{\partial \theta_{2}}, \frac{\partial \mathcal{L}}{\partial \theta_{3}}, \quad \ldots \frac{\partial \mathcal{L}}{\partial \theta_{n}}\right)
∇L=(∂θ1∂L,∂θ2∂L,∂θ3∂L,…∂θn∂L)
此时梯度下降算法可以按着向量形式进行更新:
θ
′
=
θ
−
η
∗
∇
L
\theta^{\prime}=\theta-\eta * \nabla \mathcal{L}
θ′=θ−η∗∇L
梯度下降算法一般是寻找函数的最小值,有时希望求解函数的最大值,如增强学习中希望最大化奖励函数,则可按着梯度方向更新
θ
′
=
θ
+
η
∗
∇
L
\theta^{\prime}=\theta+\eta * \nabla \mathcal{L}
θ′=θ+η∗∇L
即可,这种方式的更新称为梯度上升算法。其中向量
(
∂
L
∂
θ
1
,
∂
L
∂
θ
2
,
∂
L
∂
θ
3
,
…
∂
L
∂
θ
n
)
\left(\frac{\partial \mathcal{L}}{\partial \theta_{1}}, \frac{\partial \mathcal{L}}{\partial \theta_{2}}, \frac{\partial \mathcal{L}}{\partial \theta_{3}}, \dots \frac{\partial \mathcal{L}}{\partial \theta_{n}}\right)
(∂θ1∂L,∂θ2∂L,∂θ3∂L,…∂θn∂L)叫做函数的梯度(Gradient),它由所有偏导数组成,表征方向,梯度的方向表示函数值上升最快的方向,梯度的反向表示函数值下降最快的方向。
通过梯度下降算法并不能保证得到全局最优解,这主要是目标函数的非凸性造成的。考虑图 7.1 非凸函数,深蓝色区域为极小值区域,不同的优化轨迹可能得到不同的最优数值解。

神经网络的模型表达式非常复杂,模型参数量可达千万、数亿级别,几乎所有的神经网络的优化问题都是依赖于深度学习框架去自动计算每层的梯度,然后采用梯度下降算法循环迭代优化网络的参数直至性能满足需求。
在介绍多层神经网络的反向传播算法之前,我们先介绍导数的常见属性,常见激活函数、损失函数的梯度推导,然后再推导多层神经网络的梯度传播规律。
7.2 导数常见性质
本节介绍常见的求导法则和样例,为神经网络函数求导铺垫。
7.2.1 基本函数的导数
❑ 常数函数 c 导数为 0,如𝑦 = 2函数导数𝑦′ = 0
❑ 线性函数𝑦 = 𝑎 ∗ 𝑥 + 𝑐 导数为𝑎,如函数𝑦 = 2 ∗ 𝑥 + 1导数𝑦′ = 2
❑ 幂函数 x a x^{a} xa导数为𝑎 ∗ x a − 1 x^{a-1} xa−1,如𝑦 = x 2 x^{2} x2函数𝑦′ = 2 ∗ 𝑥
❑ 指数函数 a x a^{x} ax 导数为𝑎𝑥 ∗ 𝑙𝑛 𝑎,如𝑦 = e x e^{x} ex函数𝑦′ = e x e^{x} ex ∗ 𝑙𝑛 𝑒 = e x e^{x} ex
❑ 对数函数 log a x \log _{a} x logax导数为 1 x ln a \frac{1}{x \ln a} xlna1,如𝑦 = 𝑙𝑛 𝑥函数𝑦′ = 1 x ln e \frac{1}{x \ln e} xlne1
7.2.2 常用导数性质
❑ 函数加减 (𝑓 + 𝑔)′ = 𝑓′ + 𝑔′
❑ 函数相乘 (𝑓𝑔)′ = 𝑓′ ∗ 𝑔 + 𝑓 ∗ 𝑔′
❑ 函数相除 ( f g ) ′ = f ′ g − f g ′ g 2 , g ≠ 0 \left(\frac{f}{g}\right)^{\prime}=\frac{f^{\prime} g-f g^{\prime}}{g^{2}}, g \neq 0 (gf)′=g2f′g−fg′,g=0
❑ 复合函数的导数 考虑复合函数𝑓(𝑔(𝑥)),令𝑢 = 𝑔(𝑥),其导数
d
f
(
g
(
x
)
)
d
x
=
d
f
(
u
)
d
u
d
g
(
x
)
d
x
=
f
′
(
u
)
∗
g
′
(
x
)
\frac{d f(g(x))}{d x}=\frac{d f(u)}{d u} \frac{d g(x)}{d x}=f^{\prime}(u) * g^{\prime}(x)
dxdf(g(x))=dudf(u)dxdg(x)=f′(u)∗g′(x)
7.2.3 导数求解实战
考虑目标函数
L
=
x
⋅
w
2
+
b
2
\mathcal{L}=x \cdot w^{2}+b^{2}
L=x⋅w2+b2,则
∂
L
∂
w
=
∂
x
∗
w
2
∂
w
=
x
∗
2
w
∂
L
∂
b
=
∂
b
2
∂
b
=
2
b
\begin{array}{c} \frac{\partial \mathcal{L}}{\partial w}=\frac{\partial x * \mathrm{w}^{2}}{\partial w}=x * 2 w \\ \frac{\partial \mathcal{L}}{\partial b}=\frac{\partial b^{2}}{\partial b}=2 b \end{array}
∂w∂L=∂w∂x∗w2=x∗2w∂b∂L=∂b∂b2=2b
考虑目标函数
L
=
x
⋅
e
w
+
e
b
\mathcal{L}=x \cdot e^{w}+e^{b}
L=x⋅ew+eb,则
∂
L
∂
w
=
∂
x
∗
e
w
∂
w
=
x
∗
e
w
∂
L
∂
b
=
∂
e
b
∂
b
=
e
b
\begin{array}{c} \frac{\partial \mathcal{L}}{\partial w}=\frac{\partial x * \mathrm{e}^{\mathrm{w}}}{\partial w}=x * \mathrm{e}^{\mathrm{w}} \\ \frac{\partial \mathcal{L}}{\partial b}=\frac{\partial e^{b}}{\partial b}=e^{b} \end{array}
∂w∂L=∂w∂x∗ew=x∗ew∂b∂L=∂b∂eb=eb
考虑目标函数
L
=
[
y
−
(
x
w
+
b
)
]
2
=
[
(
x
w
+
b
)
−
y
]
2
\mathcal{L}=[y-(x w+b)]^{2}=[(x w+b)-y]^{2}
L=[y−(xw+b)]2=[(xw+b)−y]2,令𝑔 = 𝑥𝑤 + 𝑏 − y
∂
L
∂
w
=
2
g
∗
∂
g
∂
w
=
2
g
∗
x
=
2
(
x
w
+
b
−
y
)
∗
x
\frac{\partial \mathcal{L}}{\partial w}=2 \mathrm{g} * \frac{\partial \mathrm{g}}{\partial w}=2 g * x=2(x w+b-y) * x
∂w∂L=2g∗∂w∂g=2g∗x=2(xw+b−y)∗x
∂
L
∂
b
=
2
g
∗
∂
g
∂
b
=
2
g
∗
1
=
2
(
x
w
+
b
−
y
)
\frac{\partial \mathcal{L}}{\partial b}=2 \mathrm{g} * \frac{\partial \mathrm{g}}{\partial b}=2 g * 1=2(x w+b-y)
∂b∂L=2g∗∂b∂g=2g∗1=2(xw+b−y)
考虑目标函数ℒ = 𝑎 𝑙𝑛(𝑥𝑤 + 𝑏),令𝑔 = 𝑥𝑤 + 𝑏,则
∂
L
∂
w
=
a
∗
1
g
∗
∂
g
∂
w
=
a
x
w
+
b
∗
x
∂
L
∂
b
=
a
∗
1
g
∗
∂
g
∂
b
=
a
x
w
+
b
\begin{array}{c} \frac{\partial \mathcal{L}}{\partial w}=\mathrm{a} * \frac{1}{g} * \frac{\partial \mathrm{g}}{\partial w}=\frac{a}{x w+b} * x \\ \frac{\partial \mathcal{L}}{\partial b}=\mathrm{a} * \frac{1}{g} * \frac{\partial \mathrm{g}}{\partial b}=\frac{a}{x w+b} \end{array}
∂w∂L=a∗g1∗∂w∂g=xw+ba∗x∂b∂L=a∗g1∗∂b∂g=xw+ba
7.3 激活函数导数
7.3.1 Sigmoid 函数导数
回顾 Sigmoid 函数表达式:
σ
(
x
)
=
1
1
+
e
−
x
\sigma(x)=\frac{1}{1+e^{-x}}
σ(x)=1+e−x1
我们来推导 Sigmoid 函数的导数表达式:

可以看到,Sigmoid 函数的导数表达式最终可以表达为激活函数的输出值的简单运算,利用这一性质,在神经网络的梯度计算中,通过缓存每层的 Sigmoid 函数输出值,即可在需要的时候计算出其导数。Sigmoid 函数的导数曲线如图 7.2 所示。

为了不使用 TensorFlow 的自动求导功能,本章将使用 Numpy 实现一个通过反向传播算法优化的多层神经网络,因此本章的实现部分我们使用 Numpy 演示,实现 Sigmoid 函数的导数:
# 导入 numpy 库
import numpy as np
from matplotlib import pyplot as plt
plt.rcParams['font.size'] = 16
plt.rcParams['font.family'] = ['STKaiti']
plt.rcParams['axes.unicode_minus'] = False
def set_plt_ax():
# get current axis 获得坐标轴对象
ax = plt.gca()
ax.spines['right'].set_color('none')
# 将右边 上边的两条边颜色设置为空 其实就相当于抹掉这两条边
ax.spines['top'].set_color('none')
ax.xaxis.set_ticks_position('bottom')
# 指定下边的边作为 x 轴,指定左边的边为 y 轴
ax.yaxis.set_ticks_position('left')
# 指定 data 设置的bottom(也就是指定的x轴)绑定到y轴的0这个点上
ax.spines['bottom'].set_position(('data', 0))
ax.spines['left'].set_position(('data', 0))
def sigmoid(x):
# 实现 sigmoid 函数
return 1 / (1 + np.exp(-x))
def sigmoid_derivative(x):
# sigmoid 导数的计算
# sigmoid 函数的表达式由手动推导而得
return sigmoid(x)*(1-sigmoid(x))
x = np.arange(-6.0, 6.0, 0.1)
sigmoid_y = sigmoid(x)
sigmoid_derivative_y = sigmoid_derivative(x)
set_plt_ax()
plt.plot(x, sigmoid_y, color='C9', label='Sigmoid')
plt.plot(x, sigmoid_derivative_y, color='C4', label='导数')
plt.xlim(-6, 6)
plt.ylim(0, 1)
plt.legend(loc=2)
plt.show()
7.3.2 ReLU 函数导数
回顾 ReLU 函数的表达式:
ReLU
(
x
)
:
=
max
(
0
,
x
)
\operatorname{ReLU}(x):=\max (0, x)
ReLU(x):=max(0,x)
它的导数推导非常简单,直接可得
d
d
x
Re
L
U
=
{
1
x
≥
0
0
x
<
0
\frac{d}{d x} \operatorname{Re} L U=\left\{\begin{array}{ll} 1 & x \geq 0 \\ 0 & x<0 \end{array}\right.
dxdReLU={10x≥0x<0
可以看到,ReLU 函数的导数计算简单,x 大于等于零的时候,导数值恒为 1,在反向传播的时候,它既不会放大梯度,造成梯度爆炸(Gradient exploding);也不会缩小梯度,造成梯度弥散(Gradient vanishing)。ReLU 函数的导数曲线如图 7.3 所示。

在 ReLU 函数被广泛应用之前,神经网络中激活函数采用 Sigmoid 居多,但是 Sigmoid函数容易出现梯度弥散现象,当网络的层数增加后,较前层的参数由于梯度值非常微小,参数长时间得不到(有效)更新,无法训练深层神经网络,导致神经网络的研究一直停留在浅层;随着 ReLU 函数的提出,很好的解决了梯度弥散的现象,神经网络的层数能够地达到较深层数,如 AlexNet 中采用了 ReLU 激活函数,层数达到了 8 层,后续提出的上百层的卷积神经网络也多是采用 ReLU 激活函数。
通过 Numpy,我们可以方便地实现 ReLU 函数的导数:
def relu(x):
return np.maximum(0, x)
def relu_derivative(x): # ReLU 函数的导数
d = np.array(x, copy=True) # 用于保存梯度的张量
d[x < 0] = 0 # 元素为负的导数为 0
d[x >= 0] = 1 # 元素为正的导数为 1
return d
x = np.arange(-6.0, 6.0, 0.1)
relu_y = relu(x)
relu_derivative_y = relu_derivative(x)
set_plt_ax()
plt.plot(x, relu_y, color='C9', label='ReLU')
plt.plot(x, relu_derivative_y, color='C4', label='导数')
plt.xlim(-6, 6)
plt.ylim(0, 6)
plt.legend(loc=2)
plt.show()
7.3.3 LeakyReLU 函数导数
回顾 LeakyReLU 函数的表达式:
LeakyReLU
=
{
x
x
≥
0
p
∗
x
x
≤
0
\text { LeakyReLU }=\left\{\begin{array}{cl} x & x \geq 0 \\ p * x & x \leq 0 \end{array}\right.
LeakyReLU ={xp∗xx≥0x≤0
它的导数可以推导为
d
d
x
LeakyReLU
=
{
1
x
≥
0
p
x
<
0
\frac{d}{d x} \text { LeakyReLU }=\left\{\begin{array}{ll} 1 & x \geq 0 \\ p & x<0 \end{array}\right.
dxd LeakyReLU ={1px≥0x<0
它和 ReLU 函数的不同之处在于,当 x 小于零时,LeakyReLU 函数的导数值并不为 0,而是𝑝,p 一般设置为一个较小的数值,如 0.01 或 0.02,LeakyReLU 函数的导数曲线如图 7.4所示。

LeakyReLU 函数有效的克服了 ReLU 函数的缺陷,使用也比较广泛。我们可以通过Numpy 实现 LeakyReLU 函数的导数如下:
def leakyrelu(x, p):
y = np.copy(x)
y[y < 0] = p * y[y < 0]
return y
# 其中 p 为 LeakyReLU 的负半段斜率,为超参数
def leakyrelu_derivative(x, p):
dx = np.ones_like(x) # 创建梯度张量,全部初始化为 1
dx[x < 0] = p # 元素为负的导数为 p
return dx
x = np.arange(-6.0, 6.0, 0.1)
p = 0.1
leakyrelu_y = leakyrelu(x, p)
leakyrelu_derivative_y = leakyrelu_derivative(x, p)
set_plt_ax()
plt.plot(x, leakyrelu_y, color='C9', label='LeakyReLU')
plt.plot(x, leakyrelu_derivative_y, color='C4', label='导数')
plt.xlim(-6, 6)
plt.yticks(np.arange(-1, 7))
plt.legend(loc=2)
plt.show()
7.3.4 Tanh 函数梯度
回顾 tanh 函数的表达式:
tanh
(
x
)
=
(
e
x
−
e
−
x
)
(
e
x
+
e
−
x
)
\tanh (x)=\frac{\left(e^{x}-e^{-x}\right)}{\left(e^{x}+e^{-x}\right)}
tanh(x)=(ex+e−x)(ex−e−x)
=
2
∗
sigmoid
(
2
x
)
−
1
=2 * \operatorname{sigmoid} \operatorname{} (2 x)-1
=2∗sigmoid(2x)−1
它的导数推导为
d
d
x
tanh
(
x
)
=
(
e
x
+
e
−
x
)
(
e
x
+
e
−
x
)
−
(
e
x
−
e
−
x
)
(
e
x
−
e
−
x
)
(
e
x
+
e
−
x
)
2
=
1
−
(
e
x
−
e
−
x
)
2
(
e
x
+
e
−
x
)
2
=
1
−
tanh
2
(
x
)
\begin{aligned} \frac{d}{d x} \tanh (x) &=\frac{\left(e^{x}+e^{-x}\right)\left(e^{x}+e^{-x}\right)-\left(e^{x}-e^{-x}\right)\left(e^{x}-e^{-x}\right)}{\left(e^{x}+e^{-x}\right)^{2}} \\ &=1-\frac{\left(e^{x}-e^{-x}\right)^{2}}{\left(e^{x}+e^{-x}\right)^{2}}=1-\tanh ^{2}(x) \end{aligned}
dxdtanh(x)=(ex+e−x)2(ex+e−x)(ex+e−x)−(ex−e−x)(ex−e−x)=1−(ex+e−x)2(ex−e−x)2=1−tanh2(x)
tanh 函数及其导数曲线如图 7.5 所示。

在 Numpy 中,可以实现 Tanh 函数的导数如下:
def sigmoid(x): # sigmoid 函数实现
return 1 / (1 + np.exp(-x))
def tanh(x): # tanh 函数实现
return 2*sigmoid(2*x) - 1
def tanh_derivative(x): # tanh 导数实现
return 1-tanh(x)**2
x = np.arange(-6.0, 6.0, 0.1)
tanh_y = tanh(x)
tanh_derivative_y = tanh_derivative(x)
set_plt_ax()
plt.plot(x, tanh_y, color='C9', label='Tanh')
plt.plot(x, tanh_derivative_y, color='C4', label='导数')
plt.xlim(-6, 6)
plt.ylim(-1.5, 1.5)
plt.legend(loc=2)
plt.show()
7.4 损失函数梯度
前面已经介绍了常见的损失函数,我们这里推导均方误差损失函数和交叉熵损失函数的梯度表达式。
7.4.1 均方误差函数梯度
均方差损失函数表达式为:
L
=
1
2
∑
k
=
1
K
(
y
k
−
o
k
)
2
\mathcal{L}=\frac{1}{2} \sum_{k=1}^{K}\left(y_{k}-o_{k}\right)^{2}
L=21k=1∑K(yk−ok)2
则它的偏导数 ∂ L ∂ o i \frac{\partial \mathcal{L}}{\partial o_{i}} ∂oi∂L可以展开为
∂ L ∂ o i = 1 2 ∑ k = 1 K ∂ ∂ o i ( y k − o k ) 2 \frac{\partial \mathcal{L}}{\partial o_{i}}=\frac{1}{2} \sum_{k=1}^{K} \frac{\partial}{\partial o_{i}}\left(y_{k}-o_{k}\right)^{2} ∂oi∂L=21k=1∑K∂oi∂(yk−ok)2
利用链式法则分解为
∂
L
∂
o
i
=
1
2
∑
k
=
1
K
2
∗
(
y
k
−
o
k
)
∗
∂
(
y
k
−
o
k
)
∂
o
i
\frac{\partial \mathcal{L}}{\partial o_{i}}=\frac{1}{2} \sum_{k=1}^{K} 2 *\left(y_{k}-o_{k}\right) * \frac{\partial\left(y_{k}-o_{k}\right)}{\partial o_{i}}
∂oi∂L=21k=1∑K2∗(yk−ok)∗∂oi∂(yk−ok)
即
∂
L
∂
o
i
=
∑
k
=
1
K
(
y
k
−
o
k
)
⋅
−
1
⋅
∂
o
k
∂
o
i
=
∑
k
=
1
K
(
o
k
−
y
k
)
⋅
∂
o
k
∂
o
i
\begin{aligned} \frac{\partial \mathcal{L}}{\partial o_{i}} &=\sum_{k=1}^{K}\left(y_{k}-o_{k}\right) \cdot-1 \cdot \frac{\partial o_{k}}{\partial o_{i}} \\ &=\sum_{k=1}^{K}\left(o_{k}-y_{k}\right) \cdot \frac{\partial o_{k}}{\partial o_{i}} \end{aligned}
∂oi∂L=k=1∑K(yk−ok)⋅−1⋅∂oi∂ok=k=1∑K(ok−yk)⋅∂oi∂ok
∂
o
k
∂
o
i
\frac{\partial o_{k}}{\partial o_{i}}
∂oi∂ok仅当𝑘 = 𝑖时才为 1,其他点都为 0,也就是说,
∂
L
∂
θ
i
\frac{\partial L}{\partial \theta_{i}}
∂θi∂L只与第
i
i
i号节点相关,与其他节点无关。因此上式中的求和符号可以去掉。均方差的导数可以推导为:
∂
L
∂
o
i
=
(
o
i
−
y
i
)
\frac{\partial \mathcal{L}}{\partial o_{i}}=\left(o_{i}-y_{i}\right)
∂oi∂L=(oi−yi)
7.4.2 交叉熵函数梯度
可以参考文章:Softmax函数详解以及求导过程
在计算交叉熵损失函数时,一般将Softmax函数与交叉熵函数统一实现。我们先推导Softmax 函数的梯度,再推导交叉熵函数的梯度。
7.4.2.1Softmax 梯度
回顾 Softmax 函数的表达式:
p i = e z i ∑ k = 1 K e z k p_{i}=\frac{e^{z_{i}}}{\sum_{k=1}^{K} e^{z_{k}}} pi=∑k=1Kezkezi
它的功能是将 K K K个输出节点的值转换为概率,并保证概率之和为 1,如图 7.6 所示。

回顾
f
(
x
)
=
g
(
x
)
h
(
x
)
f(x)=\frac{g(x)}{h(x)}
f(x)=h(x)g(x)
函数的导数
f
′
(
x
)
=
g
′
(
x
)
h
(
x
)
−
h
′
(
x
)
g
(
x
)
h
(
x
)
2
f^{\prime}(x)=\frac{g^{\prime}(x) h(x)-h^{\prime}(x) g(x)}{h(x)^{2}}
f′(x)=h(x)2g′(x)h(x)−h′(x)g(x)
对于 Softmax 函数,
g
(
x
)
=
e
z
i
,
h
(
x
)
=
∑
k
=
1
K
e
z
k
g(x)=e^{z_{i}}, h(x)=\sum_{k=1}^{K} e^{z_{k}}
g(x)=ezi,h(x)=∑k=1Kezk,下面我们根据𝑖 = 𝑗时和𝑖 ≠ 𝑗来分别推导Softmax 函数的梯度。
❑ 当𝑖 = 𝑗时 Softmax 函数的偏导数可以展开为

提取公共项
e
Z
i
e^{Z_{i}}
eZi=

拆分为 2 部分=

可以看到,它们即是 2 个概率值的相乘,同时𝑝𝑖 = 𝑝j := 𝑝𝑖(1 − 𝑝j )
❑ 当𝑖 ≠ 𝑗时 展开 Softmax 函数为
∂
e
z
i
∑
k
=
1
K
e
z
k
∂
z
j
=
0
−
e
z
j
e
z
i
(
∑
k
=
1
K
e
z
k
)
2
\frac{\partial \frac{e^{z_{i}}}{\sum_{k=1}^{K} e^{z_{k}}}}{\partial z_{j}}=\frac{0-e^{z_{j}} e^{z_{i}}}{\left(\sum_{k=1}^{K} e^{z_{k}}\right)^{2}}
∂zj∂∑k=1Kezkezi=(∑k=1Kezk)20−ezjezi
去掉 0 项,并分解为 2 项
=
−
e
z
j
∑
k
=
1
K
e
z
k
×
e
z
i
∑
k
=
1
K
e
z
k
=
−
p
j
⋅
p
i
\begin{array}{c} =\frac{-e^{z_{j}}}{\sum_{k=1}^{K} e^{z_{k}}} \times \frac{e^{z_{i}}}{\sum_{k=1}^{K} e^{z_{k}}} \\ =-p_{j} \cdot p_{i} \end{array}
=∑k=1Kezk−ezj×∑k=1Kezkezi=−pj⋅pi
可以看到,虽然 Softmax 函数的梯度推导稍复杂,但是最终的结果还是很简洁的:

7.4.2.2交叉熵梯度
考虑交叉熵损失函数的表达式
L
=
−
∑
k
y
k
log
(
p
k
)
\mathcal{L}=-\sum_{k} y_{k} \log \left(p_{k}\right)
L=−k∑yklog(pk)
我们直接来推导最终损失函数对网络输出 logits 变量
z
i
z_{i}
zi的偏导数,展开为
∂
L
∂
z
i
=
−
∑
k
y
k
∂
log
(
p
k
)
∂
z
i
\frac{\partial \mathcal{L}}{\partial z_{i}}=-\sum_{k} y_{k} \frac{\partial \log \left(p_{k}\right)}{\partial z_{i}}
∂zi∂L=−k∑yk∂zi∂log(pk)
将𝑙𝑜𝑔 ℎ复合函数利用链式法则分解为
=
−
∑
k
y
k
∂
log
(
p
k
)
∂
p
k
×
∂
p
k
∂
z
i
=-\sum_{k} y_{k} \frac{\partial \log \left(p_{k}\right)}{\partial p_{k}} \times \frac{\partial p_{k}}{\partial z_{i}}
=−k∑yk∂pk∂log(pk)×∂zi∂pk
即
=
−
∑
k
y
k
1
p
k
×
∂
p
k
∂
z
i
=-\sum_{k} y_{k} \frac{1}{p_{k}} \times \frac{\partial p_{k}}{\partial z_{i}}
=−k∑ykpk1×∂zi∂pk
其中
∂
p
k
∂
z
i
\frac{\partial p_{k}}{\partial z_{i}}
∂zi∂pk即为我们已经推导的 Softmax 函数的偏导数。
将求和符号分开为𝑘 = 𝑖以及𝑘 ≠ 𝑖的 2 种情况,并代入
∂
p
k
∂
z
i
\frac{\partial p_{k}}{\partial z_{i}}
∂zi∂pk求解的公式,可得
∂
L
∂
z
i
=
−
y
i
(
1
−
p
i
)
−
∑
k
≠
i
y
k
1
p
k
(
−
p
k
⋅
p
i
)
\frac{\partial \mathcal{L}}{\partial z_{i}}=-y_{i}\left(1-p_{i}\right)-\sum_{k \neq i} y_{k} \frac{1}{p_{k}}\left(-p_{k} \cdot p_{i}\right)
∂zi∂L=−yi(1−pi)−k=i∑ykpk1(−pk⋅pi)
进一步化简为
=
−
y
i
(
1
−
p
i
)
+
∑
k
≠
i
y
k
⋅
p
i
=
−
y
i
+
y
i
p
i
+
∑
k
≠
i
y
k
⋅
p
i
\begin{aligned} &=-y_{i}\left(1-p_{i}\right)+\sum_{k \neq i} y_{k} \cdot p_{i}\\ &=-y_{i}+y_{i} p_{i}+\sum_{k \neq i} y_{k} \cdot p_{i} \end{aligned}
=−yi(1−pi)+k=i∑yk⋅pi=−yi+yipi+k=i∑yk⋅pi
提供公共项
p
i
p_{i}
pi
=
p
i
(
y
i
+
∑
k
≠
i
y
k
)
−
y
i
=p_{i}\left(y_{i}+\sum_{k \neq i} y_{k}\right)-y_{i}
=pi⎝⎛yi+k=i∑yk⎠⎞−yi
完成交叉熵函数的梯度推导。
特别地,对于分类问题中 y 通过 one-hot 编码的方式,则有
∑
k
y
k
=
1
y
i
+
∑
k
≠
i
y
k
=
1
\begin{aligned} &\sum_{k} y_{k}=1\\ &y_{i}+\sum_{k \neq i} y_{k}=1 \end{aligned}
k∑yk=1yi+k=i∑yk=1
因此交叉熵的偏导数可以进一步简化为
∂
L
∂
z
i
=
p
i
−
y
i
\frac{\partial \mathcal{L}}{\partial \mathbf{z}_{i}}=p_{i}-y_{i}
∂zi∂L=pi−yi
7.5 全连接层梯度
在介绍完梯度的基础知识后,我们正式地进入到神经网络的反向传播算法的推导中。实际使用中的神经网络的结构多种多样,我们将以全连接层,激活函数采用 Sigmoid 函数,误差函数为 Softmax+MSE 损失函数的神经网络为例,推导其梯度传播方式。
7.5.1 单个神经元梯度
对于采用 Sigmoid 激活函数的神经元模型,它的数学模型可以写为
o 1 = σ ( w 1 x + b 1 ) o^{1}=\sigma\left(w^{1} x+b^{1}\right) o1=σ(w1x+b1)
其中变量的上标表示层数,如 o 1 o^{1} o1表示第一个隐藏层的输出,𝑥表示网络的输入,我们以权值𝑤的偏导数推导为例。
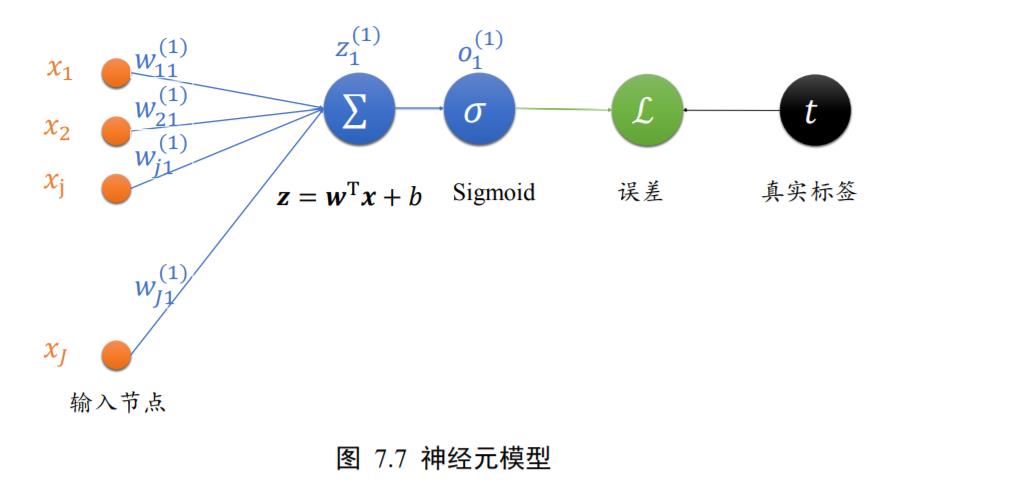
为了方便演示,我们将神经元模型绘制如图 7.7 所示,图中未画出偏置𝑏,输入节点数为J。其中输入第𝑗个节点到输出
o
1
o^{1}
o1的权值连接记为
w
j
1
1
w_{j1}^{1}
wj11,上标表示权值属于的层数,下标表示当前连接的起始节点号和终止节点号,如下标𝑗1表示上一层的第𝑗号节点到当前层的 1 号节点。经过激活函数𝜎之前的变量叫做
z
1
1
z_{1}^{1}
z11,经过激活函数𝜎之后的变量叫
o
1
o^{1}
o1,由于只有一个输出节点,
o
1
1
o^{1}_{1}
o11 =
o
1
o^{1}
o1。输出与真实标签之间计算误差,误差记为ℒ。
如果我们采用均方差误函数,考虑到单个神经元只有一个输出
o
1
1
o^{1}_{1}
o11,那么损失可以表
达为
L
=
1
2
(
o
1
1
−
t
)
2
\mathcal{L}=\frac{1}{2}\left(o_{1}^{1}-t\right)^{2}
L=21(o11−t)2
其中𝑡为真实标签值,添加1/2并不影响梯度的方向,计算更简便。我们以权值连接的第𝑗 ∈[1,𝐽]号节点的权值
w
j
1
w_{j1}
wj1为例,考虑损失函数ℒ对其的偏导数
∂
L
∂
w
j
1
\frac{\partial \mathcal{L}}{\partial w_{j 1}}
∂wj1∂L:
∂
L
∂
w
j
1
=
(
o
1
−
t
)
∂
o
1
∂
w
j
1
\frac{\partial \mathcal{L}}{\partial w_{j 1}}=\left(o_{1}-t\right) \frac{\partial o_{1}}{\partial w_{j 1}}
∂wj1∂L=(o1−t)∂wj1∂o1
将
o
1
=
σ
(
z
1
)
o_{1}=\sigma\left(z_{1}\right)
o1=σ(z1)分解,考虑到 Sigmoid 函数的导数
σ
′
=
σ
(
1
−
σ
)
\sigma^{\prime}=\sigma(1-\sigma)
σ′=σ(1−σ):
∂
L
∂
w
j
1
=
(
o
1
−
t
)
∂
σ
(
z
1
)
∂
w
j
1
=
(
o
1
−
t
)
σ
(
z
1
)
(
1
−
σ
(
z
1
)
)
∂
z
1
1
∂
w
j
1
\begin{aligned} &\frac{\partial \mathcal{L}}{\partial w_{j 1}}=\left(o_{1}-t\right) \frac{\partial \sigma\left(z_{1}\right)}{\partial w_{j 1}}\\ =&\left(o_{1}-t\right) \sigma\left(z_{1}\right)\left(1-\sigma\left(z_{1}\right)\right) \frac{\partial z_{1}^{1}}{\partial w_{j 1}} \end{aligned}
=∂wj1∂L=(o1−t)∂wj1∂σ(z1)(o1−t)σ(z1)(1−σ(z1))∂wj1∂z11
σ
(
z
1
)
\sigma\left(z_{1}\right)
σ(z1)写成
o
1
o_{1}
o1,继续推导
∂
L
∂
w
j
1
\frac{\partial \mathcal{L}}{\partial w_{j 1}}
∂wj1∂L:
∂
L
∂
w
j
1
=
(
o
1
−
t
)
o
1
(
1
−
o
1
)
∂
z
1
1
∂
w
j
1
\frac{\partial \mathcal{L}}{\partial w_{j 1}}=\left(o_{1}-t\right) o_{1}\left(1-o_{1}\right) \frac{\partial z_{1}^{1}}{\partial w_{j 1}}
∂wj1∂L=(o1−t)o1(1−o1)∂wj1∂z11
考虑
∂
z
1
1
∂
w
j
1
=
x
j
\frac{\partial z_{1}^{1}}{\partial w_{j 1}}=x_{j}
∂wj1∂z11=xj,可得:
∂
L
∂
w
j
1
=
(
o
1
−
t
)
o
1
(
1
−
o
1
)
x
j
\frac{\partial \mathcal{L}}{\partial w_{j 1}}=\left(o_{1}-t\right) o_{1}\left(1-o_{1}\right) x_{j}
∂wj1∂L=(o1−t)o1(1−o1)xj
从上式可以看到,误差对权值
w
j
1
w_{j1}
wj1的偏导数只与输出值
o
1
o_{1}
o1、真实值𝑡以及当前权值连接的输入
x
j
x_{j}
xj有关。
7.5.2 全连接层梯度
我们把单个神经元模型推广到单层全连接层的网络上,如图 7.8 所示。输入层通过一个全连接层得到输出向量𝒐1,与真实标签向量𝒕计算均方误差。输入节点数为
J
J
J,输出节点数为
K
K
K。
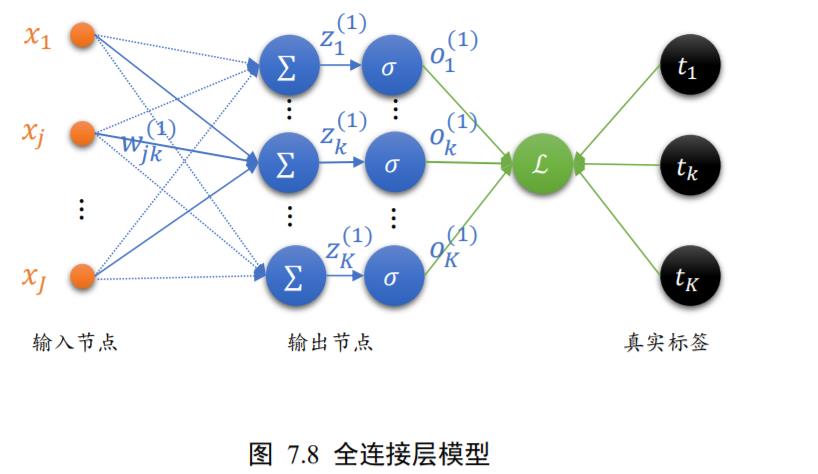
多输出的全连接网络层模型与单个神经元模型不同之处在于,它多了很多的输出节点
o
1
1
,
o
2
1
,
o
3
1
,
…
,
o
K
1
o_{1}^{1}, o_{2}^{1}, o_{3}^{1}, \ldots, o_{K}^{1}
o11,o21,o31,…,oK1,同样的每个输出节点分别对应到真实标签
t
1
,
t
2
,
…
,
t
K
t_{1}, t_{2}, \dots, t_{K}
t1,t2,…,tK。均方误差可以表达为
L
=
1
2
∑
i
=
1
K
(
o
i
1
−
t
i
)
2
\mathcal{L}=\frac{1}{2} \sum_{i=1}^{K}\left(o_{i}^{1}-t_{i}\right)^{2}
L=21i=1∑K(oi1−ti)2
由于
∂
L
∂
w
j
k
\frac{\partial \mathcal{L}}{\partial w_{j k}}
∂wjk∂L只与节点
o
k
1
o_{k}^{1}
ok1有关联,上式中的求和符号可以去掉,即𝑖 = 𝑘:
∂
L
∂
w
j
k
=
(
o
k
−
t
k
)
∂
o
k
∂
w
j
k
\frac{\partial \mathcal{L}}{\partial w_{j k}}=\left(o_{k}-t_{k}\right) \frac{\partial o_{k}}{\partial w_{j k}}
∂wjk∂L=(ok−tk)∂wjk∂ok
将
o
k
=
σ
(
z
k
)
o_{k}=\sigma\left(z_{k}\right)
ok=σ(zk)代入
∂
L
∂
w
j
k
=
(
o
k
−
t
k
)
∂
σ
(
z
k
)
∂
w
j
k
\frac{\partial \mathcal{L}}{\partial w_{j k}}=\left(o_{k}-t_{k}\right) \frac{\partial \sigma\left(z_{k}\right)}{\partial w_{j k}}
∂wjk∂L=(ok−tk)∂wjk∂σ(zk)
考虑 Sigmoid 函数的导数𝜎′ = 𝜎(1 − 𝜎):
∂
L
∂
w
j
k
=
(
o
k
−
t
k
)
σ
(
z
k
)
(
1
−
σ
(
z
k
)
)
∂
z
k
1
∂
w
j
k
\frac{\partial \mathcal{L}}{\partial w_{j k}}=\left(o_{k}-t_{k}\right) \sigma\left(z_{k}\right)\left(1-\sigma\left(z_{k}\right)\right) \frac{\partial z_{k}^{1}}{\partial w_{j k}}
∂wjk∂L=(ok−tk)σ(zk)(1−σ(zk))∂wjk∂zk1
将
σ
(
Z
k
)
\sigma\left(Z_{k}\right)
σ(Zk)记为
O
k
O_{k}
Ok:
∂
L
∂
w
j
k
=
(
o
k
−
t
k
)
o
k
(
1
−
o
k
)
∂
z
k
1
∂
w
j
k
\frac{\partial \mathcal{L}}{\partial w_{j k}}=\left(o_{k}-t_{k}\right) o_{k}\left(1-o_{k}\right) \frac{\partial z_{k}^{1}}{\partial w_{j k}}
∂wjk∂L=(ok−tk)ok(1−ok)∂wjk∂zk1
最终可得
∂
L
∂
w
j
k
=
(
o
k
−
t
k
)
o
k
(
1
−
o
k
)
x
j
\frac{\partial \mathcal{L}}{\partial w_{j k}}=\left(o_{\mathrm{k}}-t_{k}\right) o_{k}\left(1-o_{k}\right) x_{j}
∂wjk∂L=(ok−tk)ok(1−ok)xj
由此可以看到,某条连接
W
j
k
W_{jk}
Wjk上面的连接,只与当前连接的输出节点
O
k
1
O_{k}^{1}
Ok1,对应的真实值节点的标签
t
k
1
t_{k}^{1}
tk1,以及对应的输入节点
X
j
X_{j}
Xj有关。
我们令
δ
k
=
(
o
k
−
t
k
)
o
k
(
1
−
o
k
)
\delta_{k}=\left(o_{k}-t_{k}\right) o_{k}\left(1-o_{k}\right)
δk=(ok−tk)ok(1−ok),则
∂
L
∂
w
j
k
\frac{\partial \mathcal{L}}{\partial w_{j k}}
∂wjk∂L可以表达为
∂
L
∂
w
j
k
=
δ
k
x
j
\frac{\partial \mathcal{L}}{\partial w_{j k}}=\delta_{k} x_{j}
∂wjk∂L=δkxj
其中
δ
k
\delta_{k}
δk变量表征连接线的终止节点的梯度传播的某种特性,使用
δ
k
\delta_{k}
δk表示后,
∂
L
∂
w
j
k
\frac{\partial \mathcal{L}}{\partial w_{j k}}
∂wjk∂L偏导数只与当前连接的起始节点
x
j
x_{j}
xj,终止节点处
δ
k
\delta_{k}
δk有关,理解起来比较直观。后续我们将会在看到
δ
k
\delta_{k}
δk在循环推导梯度中的作用。
现在我们已经推导完单层神经网络(即输出层)的梯度传播方式,接下来我们尝试推导倒数第二层的梯度传播公式,完成了导数第二层的传播推导,可以循环往复推导所有隐藏层的梯度传播公式,从而完成所有参数的梯度计算。
在介绍反向传播算法之前,我们先学习一个导数传播的核心法则:链式法则。
7.6 链式法则
前面我们介绍了输出层的梯度
∂
L
∂
w
j
k
\frac{\partial \mathcal{L}}{\partial w_{j k}}
∂wjk∂L计算方法,我们现在来介绍链式法则,它是能在不显式推导神经网络的数学表达式的情况下,逐层推导梯度的核心公式,非常重要。
其实我们前面在推导梯度的过程中已经或多或少地用到了链式法则。考虑复合函数
y
=
f
(
u
)
,
u
=
g
(
x
)
y=f(u), u=g(x)
y=f(u),u=g(x),则
d
y
d
x
\frac{d y}{d x}
dxdy可由
d
y
d
u
\frac{d y}{d u}
dudy和
d
u
d
x
\frac{d u}{d x}
dxdu推导出:
d
y
d
x
=
d
y
d
u
⋅
d
u
d
x
=
f
′
(
g
(
x
)
)
⋅
g
′
(
x
)
\frac{d y}{d x}=\frac{d y}{d u} \cdot \frac{d u}{d x}=f^{\prime}(g(x)) \cdot g^{\prime}(x)
dxdy=dudy⋅dxdu=f′(g(x))⋅g′(x)
考虑多元复合函数,𝑧 = 𝑓(𝑥, 𝑦),其中𝑥 = 𝑔(𝑡), 𝑦 = ℎ(𝑡),那么
d
z
d
t
\frac{d z}{d t}
dtdz的导数可以由
d
z
d
x
\frac{d z}{d x}
dxdz和
d
z
d
y
\frac{d z}{d y}
dydz等推导出,具体表达为
d
z
d
t
=
∂
z
∂
x
d
x
d
t
+
∂
z
∂
y
d
y
d
t
\frac{d z}{d t}=\frac{\partial z}{\partial x} \frac{d x}{d t}+\frac{\partial z}{\partial y} \frac{d y}{d t}
dtdz=∂x∂zdtdx+∂y∂zdtdy
例如,
z
=
(
2
t
+
1
)
2
+
e
t
2
z=(2 t+1)^{2}+e^{t^{2}}
z=(2t+1)2+et2,令𝑥 = 2𝑡 + 1,
y
=
t
2
y=t^{2}
y=t2,则
z
=
x
2
+
e
y
z=x^{2}+e^{y}
z=x2+ey
d
z
d
t
=
∂
z
∂
x
d
x
d
t
+
∂
z
∂
y
d
y
d
t
=
2
x
∗
2
+
e
y
∗
2
t
d
z
d
t
=
2
(
2
t
+
1
)
∗
2
+
e
t
2
∗
2
t
d
z
d
t
=
4
(
2
t
+
1
)
+
2
t
e
t
2
\begin{aligned} \frac{d z}{d t}=\frac{\partial z}{\partial x} \frac{d x}{d t}+\frac{\partial z}{\partial y} \frac{d y}{d t}=2 x * 2+e^{y} * 2 t \\ \frac{d z}{d t}=2(2 t+1) * 2+e^{t^{2}} * 2 t \\ \frac{d z}{d t}=4(2 t+1)+2 t e^{t^{2}} \end{aligned}
dtdz=∂x∂zdtdx+∂y∂zdtdy=2x∗2+ey∗2tdtdz=2(2t+1)∗2+et2∗2tdtdz=4(2t+1)+2tet2
神经网络的损失函数ℒ来自于各个输出节点
O
k
K
O_{k}^{K}
OkK,如下图 7.9 所示,其中输出节点
O
k
K
O_{k}^{K}
OkK又与隐藏层的输出节点
O
j
J
O_{j}^{J}
OjJ相关联,因此链式法则非常适合于神经网络的梯度推导。让我们来考虑损失函数ℒ如何应用链式法则。
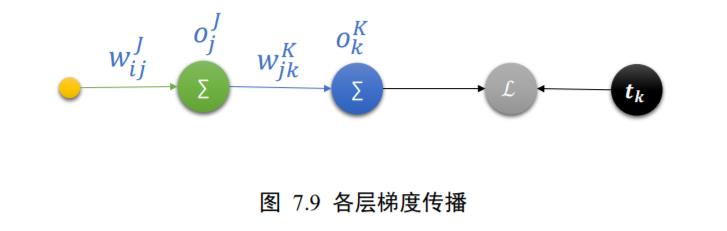
前向传播时,数据经过
w
i
j
J
w_{ij}^{J}
wijJ传到倒数第二层的节点
O
j
J
O_{j}^{J}
OjJ,再传播到输出层的节点
O
k
K
O_{k}^{K}
OkK。在每层只有一个节点时,
∂
L
∂
w
j
k
1
\frac{\partial \mathcal{L}}{\partial w_{j k}^{1}}
∂wjk1∂L可以利用链式法则,逐层分解为:
∂
L
∂
w
i
j
J
=
∂
L
∂
o
j
J
∂
o
j
J
∂
w
i
j
J
=
∂
L
∂
o
k
K
∂
o
k
K
∂
o
j
J
∂
o
j
J
∂
w
i
j
J
\frac{\partial \mathcal{L}}{\partial w_{i j}^{J}}=\frac{\partial \mathcal{L}}{\partial o_{j}^{J}} \frac{\partial o_{j}^{J}}{\partial w_{i j}^{J}}=\frac{\partial \mathcal{L}}{\partial o_{k}^{K}} \frac{\partial o_{k}^{K}}{\partial o_{j}^{J}} \frac{\partial o_{j}^{J}}{\partial w_{i j}^{J}}
∂wijJ∂L=∂ojJ∂L∂wijJ∂ojJ=∂okK∂L∂ojJ∂okK∂wijJ∂ojJ
其中
∂
L
∂
o
k
K
\frac{\partial \mathcal{L}}{\partial o_{k}^{K}}
∂okK∂L可以由误差函数直接推导出,
∂
o
k
K
∂
o
j
J
\frac{\partial o_{k}^{K}}{\partial o_{j}^{J}}
∂ojJ∂okK可以由全连接层公式推导出,
∂
o
j
J
∂
w
i
j
J
\frac{\partial o_{j}^{J}}{\partial w_{i j}^{J}}
∂wijJ∂ojJ的导数即为输入
x
i
I
x_{i}^{I}
xiI。可以看到,通过链式法则,我们不需要显式计算
L
=
f
(
w
i
j
J
)
\mathcal{L}=f\left(w_{i j}^{J}\right)
L=f(wijJ)的具体数学表达式,直接可以将偏导数分解,层层迭代即可推导出。
我们简单使用 TensorFlow 来体验链式法则的魅力:
import tensorflow as tf
#构建待优化变量
x=tf.constant(1.)
w1=tf.constant(2.)
b1=tf.constant(1.)
w2=tf.constant(2.)
b2=tf.constant(1.)
# 构建梯度记录器
with tf.GradientTape(persistent=True) as tape:
# 非tf.Variable类型的张量需要人为设置记录梯度信息
tape.watch([w1,b1,w2,b2])
#构建两层线性网络
y1=x*w1+b1
y2=y1*w2+b2
# 独立求解出各个偏导数
dy2_dy1=tape.gradient(y2,[y1])[0]
dy1_dw1=tape.gradient(y1,[w1])[0]
dy2_dw1=tape.gradient(y2,[w1])[0]
#验证连式法则
print(dy2_dy1*dy1_dw1)
print(dy2_dw1)
我们通过自动求导功能计算出 ∂ y 2 ∂ y 1 \frac{\partial y_{2}}{\partial y_{1}} ∂y1∂y2, ∂ y 1 ∂ w 1 \frac{\partial y_{1}}{\partial w_{1}} ∂w1∂y1和 ∂ y 2 ∂ w 1 \frac{\partial y_{2}}{\partial w_{1}} ∂w1∂y2,借助链式法则我们可以推断 ∂ y 2 ∂ y 1 \frac{\partial y_{2}}{\partial y_{1}} ∂y1∂y2* ∂ y 1 ∂ w 1 \frac{\partial y_{1}}{\partial w_{1}} ∂w1∂y1与 ∂ y 2 ∂ w 1 \frac{\partial y_{2}}{\partial w_{1}} ∂w1∂y2应该是相等的,他们的计算结果如下:
tf.Tensor(2.0, shape=(), dtype=float32)
tf.Tensor(2.0, shape=(), dtype=float32)
可以看到 ∂ y 2 ∂ y 1 ∗ ∂ y 1 ∂ w 1 = ∂ y 2 ∂ w 1 \frac{\partial y_{2}}{\partial y_{1}} * \frac{\partial y_{1}}{\partial w_{1}}=\frac{\partial y_{2}}{\partial w_{1}} ∂y1∂y2∗∂w1∂y1=∂w1∂y2,偏导数的传播是符合链式法则的。
7.7 反向传播算法
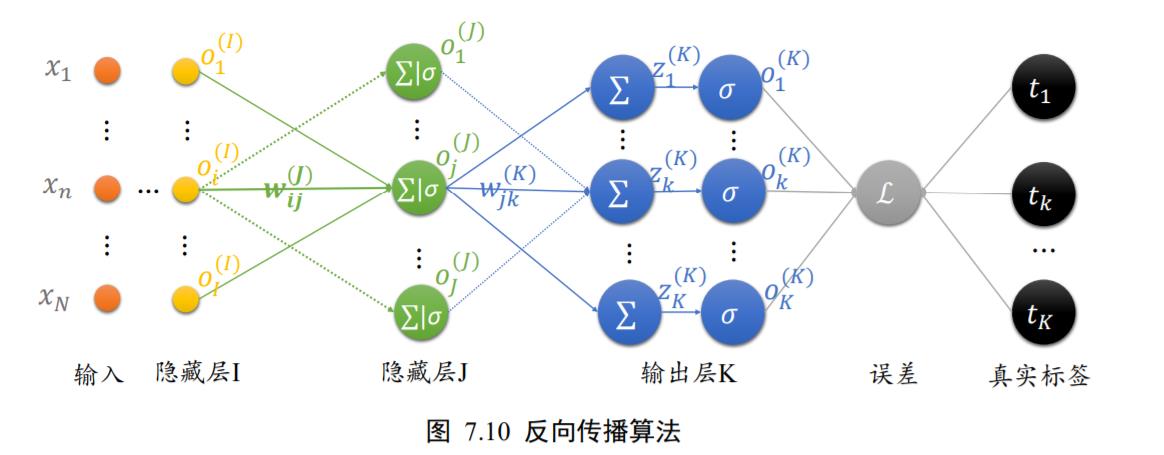
现在我们来推导隐藏层的反向传播算法。简单回顾一下输出层的偏导数公式:
∂
L
∂
w
j
k
=
(
o
k
−
t
k
)
o
k
(
1
−
o
k
)
x
j
=
δ
k
x
j
\frac{\partial \mathcal{L}}{\partial w_{j k}}=\left(o_{k}-t_{k}\right) o_{k}\left(1-o_{k}\right) x_{j}=\delta_{k} x_{j}
∂wjk∂L=(ok−tk)ok(1−ok)xj=δkxj
考虑网络倒数第二层的偏导数
∂
L
∂
w
i
j
\frac{\partial \mathcal{L}}{\partial w_{i j}}
∂wij∂L,如图 7.10 所示,输出层节点数为 K,输出为
O
k
=
O^{k}=
Ok=
[
o
1
K
,
o
2
K
,
…
,
o
K
K
]
\left[o_{1}^{K}, o_{2}^{K}, \ldots, o_{K}^{K}\right]
[o1K,o2K,…,oKK];倒数第二层节点数为
J
J
J,输出为
O
j
=
O^{j}=
Oj=
[
o
1
j
,
o
2
j
,
…
,
o
j
j
]
\left[o_{1}^{j}, o_{2}^{j}, \ldots, o_{j}^{j}\right]
[o1j,o2j,…,ojj];倒数第三层的节点数为
I
I
I,输出为
O
i
=
O^{i}=
Oi=
[
o
1
i
,
o
2
i
,
…
,
o
i
i
]
\left[o_{1}^{i}, o_{2}^{i}, \ldots, o_{i}^{i}\right]
[o1i,o2i,…,oii].
首先将均方差误差函数展开:
∂
L
∂
w
i
j
=
∂
∂
w
i
j
1
2
∑
k
(
o
k
−
t
k
)
2
\frac{\partial \mathcal{L}}{\partial w_{i j}}=\frac{\partial}{\partial w_{i j}} \frac{1}{2} \sum_{k}\left(o_{k}-t_{k}\right)^{2}
∂wij∂L=∂wij∂21k∑(ok−tk)2
由于ℒ通过每个输出节点
o
k
o_{k}
ok与
w
i
j
w_{ij}
wij 相关联,故此处不能去掉求和符号,运用链式法则将均方
差函数拆解:
∂ L ∂ w i j = ∑ k ( o k − t k ) ∂ ∂ w i j o k \frac{\partial \mathcal{L}}{\partial w_{i j}}=\sum_{k}\left(o_{k}-t_{k}\right) \frac{\partial}{\partial w_{i j}} o_{k} ∂wij∂L=k∑(ok−tk)∂wij∂ok
将 o k = σ ( z k ) o_{k}=\sigma\left(z_{k}\right) ok=σ(zk)代入
∂ L ∂ w i j = ∑ k ( o k − t k ) ∂ ∂ w i j σ ( z k ) \frac{\partial \mathcal{L}}{\partial w_{i j}}=\sum_{k}\left(o_{k}-t_{k}\right) \frac{\partial}{\partial w_{i j}} \sigma\left(z_{k}\right) ∂wij∂L=k∑(ok−tk)∂wij∂σ(zk)
利用 Sigmoid 函数的导数𝜎′ = 𝜎(1 − 𝜎)进一步分解
∂
L
∂
w
i
j
=
∑
k
(
o
k
−
t
k
)
∂
∂
w
i
j
σ
(
z
k
)
\frac{\partial \mathcal{L}}{\partial w_{i j}}=\sum_{k}\left(o_{k}-t_{k}\right) \frac{\partial}{\partial w_{i j}} \sigma\left(z_{k}\right)
∂wij∂L=k∑(ok−tk)∂wij∂σ(zk)
将
σ
(
z
k
)
\sigma\left(z_{k}\right)
σ(zk)写回
o
k
o_{k}
ok形式,并利用链式法则,将
∂
z
k
∂
w
i
j
\frac{\partial z_{k}}{\partial w_{i j}}
∂wij∂zk分解
∂
L
∂
w
i
j
=
∑
k
(
o
k
−
t
k
)
o
k
(
1
−
o
k
)
∂
z
k
∂
o
j
⋅
∂
o
j
∂
w
i
j
\frac{\partial \mathcal{L}}{\partial w_{i j}}=\sum_{k}\left(o_{k}-t_{k}\right) o_{k}\left(1-o_{k}\right) \frac{\partial z_{k}}{\partial o_{j}} \cdot \frac{\partial o_{j}}{\partial w_{i j}}
∂wij∂L=k∑(ok−tk)ok(1−ok)∂oj∂zk⋅∂wij∂oj
其中
∂
z
k
∂
o
j
=
w
j
k
\frac{\partial z_{k}}{\partial o_{j}}=w_{j k}
∂oj∂zk=wjk,因此
∂
L
∂
w
i
j
=
∑
k
(
o
k
−
t
k
)
o
k
(
1
−
o
k
)
w
j
k
∂
o
j
∂
w
i
j
\frac{\partial \mathcal{L}}{\partial w_{i j}}=\sum_{k}\left(o_{k}-t_{k}\right) o_{k}\left(1-o_{k}\right) w_{j k} \frac{\partial o_{j}}{\partial w_{i j}}
∂wij∂L=k∑(ok−tk)ok(1−ok)wjk∂wij∂oj
考虑到
∂
o
j
∂
w
i
j
\frac{\partial o_{j}}{\partial w_{i j}}
∂wij∂oj与 k 无关,可提取公共项
∂
L
∂
w
i
j
=
∂
o
j
∂
w
i
j
∑
k
(
o
k
−
t
k
)
o
k
(
1
−
o
k
)
w
j
k
\frac{\partial \mathcal{L}}{\partial w_{i j}}=\frac{\partial o_{j}}{\partial w_{i j}} \sum_{k}\left(o_{k}-t_{k}\right) o_{k}\left(1-o_{k}\right) w_{j k}
∂wij∂L=∂wij∂ojk∑(ok−tk)ok(1−ok)wjk
进一步利用
o
j
=
σ
(
z
j
)
o_{j}=\sigma\left(z_{j}\right)
oj=σ(zj),并利用 Sigmoid 导数
σ
′
=
σ
(
1
−
σ
)
\sigma^{\prime}=\sigma(1-\sigma)
σ′=σ(1−σ)将
∂
o
j
∂
w
i
j
\frac{\partial o_{j}}{\partial w_{i j}}
∂wij∂oj拆分为
∂
L
∂
w
i
j
=
o
j
(
1
−
o
j
)
∂
z
j
∂
w
i
j
∑
k
(
o
k
−
t
k
)
o
k
(
1
−
o
k
)
w
j
k
\frac{\partial \mathcal{L}}{\partial w_{i j}}=o_{j}\left(1-o_{j}\right) \frac{\partial z_{j}}{\partial w_{i j}} \sum_{k}\left(o_{k}-t_{k}\right) o_{k}\left(1-o_{k}\right) w_{j k}
∂wij∂L=oj(1−oj)∂wij∂zjk∑(ok−tk)ok(1−ok)wjk
其中
∂
z
j
∂
w
i
j
\frac{\partial z_{j}}{\partial w_{i j}}
∂wij∂zj的导数可直接推导出为
O
i
O_{i}
Oi,上式可写为
∂
L
∂
w
i
j
=
o
j
(
1
−
o
j
)
o
i
∑
k
(
o
k
−
t
k
)
o
k
(
1
−
o
k
)
⏟
δ
k
K
w
j
k
\frac{\partial \mathcal{L}}{\partial w_{i j}}=o_{j}\left(1-o_{j}\right) o_{i} \sum_{k} \underbrace{\left(o_{k}-t_{k}\right) o_{k}\left(1-o_{k}\right)}_{\delta_{k}^{K}} w_{j k}
∂wij∂L=oj(1−oj)oik∑δkK
(ok−tk)ok(1−ok)wjk
其中
δ
k
K
=
(
o
k
−
t
k
)
o
k
(
1
−
o
k
)
\delta_{k}^{K}=\left(o_{k}-t_{k}\right) o_{k}\left(1-o_{k}\right)
δkK=(ok−tk)ok(1−ok),则
∂
L
∂
w
i
j
\frac{\partial \mathcal{L}}{\partial w_{i j}}
∂wij∂L的表达式可简写为
∂
L
∂
w
i
j
=
o
j
(
1
−
o
j
)
o
i
∑
k
δ
k
K
w
j
k
\frac{\partial \mathcal{L}}{\partial w_{i j}}=o_{j}\left(1-o_{j}\right) o_{i} \sum_{\mathbf{k}} \delta_{k}^{K} w_{j k}
∂wij∂L=oj(1−oj)oik∑δkKwjk
我们仿照输出层
∂
L
∂
w
j
k
=
δ
k
K
x
j
\frac{\partial \mathcal{L}}{\partial w_{j k}}=\delta_{k}^{K} x_{j}
∂wjk∂L=δkKxj的书写方式,将
δ
j
J
\delta_{j}^{J}
δjJ定义为
δ
j
J
:
=
o
j
(
1
−
o
j
)
∑
k
δ
k
K
w
j
k
\delta_{j}^{J}:=o_{j}\left(1-o_{j}\right) \sum_{k} \delta_{k}^{K} w_{j k}
δjJ:=oj(1−oj)k∑δkKwjk
此时
∂
L
∂
w
i
j
\frac{\partial \mathcal{L}}{\partial w_{i j}}
∂wij∂L可以写为当前连接的起始节点的输出值
o
i
o_{i}
oi与终止节点 j 的梯度信息
δ
j
J
\delta_{j}^{J}
δjJ的简单相乘运算:
∂
L
∂
w
i
j
=
δ
j
J
O
i
I
\frac{\partial \mathcal{L}}{\partial w_{i j}}=\delta_{j}^{J} O_{i}^{I}
∂wij∂L=δjJOiI
通过定义𝛿变量,每一层的梯度表达式变得更加清晰简洁,其中𝛿可以简单理解为当前连接
w
i
j
w_{ij}
wij对误差函数的贡献值。
我们来小结一下每层的偏导数的计算公式。
输出层:
∂
L
∂
w
j
k
=
δ
k
K
o
j
δ
k
K
=
o
k
(
1
−
o
k
)
(
o
k
−
t
k
)
\begin{array}{c} \frac{\partial \mathcal{L}}{\partial w_{j k}}=\delta_{k}^{K} o_{j} \\ \delta_{k}^{K}=o_{k}\left(1-o_{k}\right)\left(o_{k}-t_{k}\right) \end{array}
∂wjk∂L=δkKojδkK=ok(1−ok)(ok−tk)
倒数第二层:
∂
L
∂
w
i
j
=
δ
j
J
o
i
δ
j
J
=
o
j
(
1
−
o
j
)
∑
k
δ
k
K
w
j
k
\begin{array}{c} \frac{\partial \mathcal{L}}{\partial w_{i j}}=\delta_{j}^{J} o_{i} \\ \delta_{j}^{J}=o_{j}\left(1-o_{j}\right) \sum_{k} \delta_{k}^{K} w_{j k} \end{array}
∂wij∂L=δjJoiδjJ=oj(1−oj)∑kδkKwjk
倒数第三层:
∂
L
∂
w
n
i
=
δ
i
I
o
n
δ
i
I
=
o
i
(
1
−
o
i
)
∑
j
δ
j
J
w
i
j
\begin{array}{c} \frac{\partial \mathcal{L}}{\partial w_{n i}}=\delta_{i}^{I} o_{n} \\ \delta_{i}^{I}=o_{i}\left(1-o_{i}\right) \sum_{j} \delta_{j}^{J} w_{i j} \end{array}
∂wni∂L=δiIonδiI=oi(1−oi)∑jδjJwij
其中 O n O_{n} On为倒数第三层的输入,即倒数第四层的输出。
依照此规律,只需要循环迭代计算每一层每个节点的 δ k K , δ j J , δ i I , … \delta_{k}^{K}, \delta_{j}^{J}, \delta_{i}^{I}, \ldots δkK,δjJ,δiI,…等值即可求得当前层的偏导数,从而得到每层权值矩阵 W W W的梯度,再通过梯度下降算法迭代优化网络参数即可。
至此,反向传播算法介绍完毕。
接下来我们会进行两个实战:第一个实战是采用 TensorFlow 提供的自动求导来优化Himmelblau 函数的极小值;第二个实战是基于 Numpy 实现反向传播算法,并完成多层神经网络的二分类任务训练.
7.8 Himmelblau 函数优化实战
Himmelblau 函数是用来测试优化算法的常用样例函数之一,它包含了两个自变量𝑥, 𝑦,数学表达式是:
f
(
x
,
y
)
=
(
x
2
+
y
−
11
)
2
+
(
x
+
y
2
−
7
)
2
f(x, y)=\left(x^{2}+y-11\right)^{2}+\left(x+y^{2}-7\right)^{2}
f(x,y)=(x2+y−11)2+(x+y2−7)2
首先我们通过如下实现 Himmelblau 函数的表达式:
from mpl_toolkits.mplot3d import Axes3D
def himmelblau(x):
# himmelblau 函数实现,传入参数 x 为 2 个元素的 List
return (x[0] ** 2 + x[1] - 11) ** 2 + (x[0] + x[1] ** 2 - 7) ** 2
通过 np.meshgrid 函数(TensorFlow 中也有 meshgrid 函数)生成二维平面网格点坐标:
x = np.arange(-6, 6, 0.1) # 可视化的 x 坐标范围为-6~6
y = np.arange(-6, 6, 0.1) # 可视化的 y 坐标范围为-6~6
print('x,y range:', x.shape, y.shape)
# 生成 x-y 平面采样网格点,方便可视化
X, Y = np.meshgrid(x, y)
print('X,Y maps:', X.shape, Y.shape)
Z = himmelblau([X, Y]) # 计算网格点上的函数值
并利用 Matplotlib 库可视化 Himmelblau 函数,如图 7.11 所示。
# 绘制 himmelblau 函数曲面
fig = plt.figure('himmelblau')
ax = fig.gca(projection='3d') # 设置 3D 坐标轴
ax.plot_surface(X, Y, Z, cmap = plt.cm.rainbow ) # 3D 曲面图
ax.view_init(60, -30)
ax.set_xlabel('x')
ax.set_ylabel('y')
plt.show()

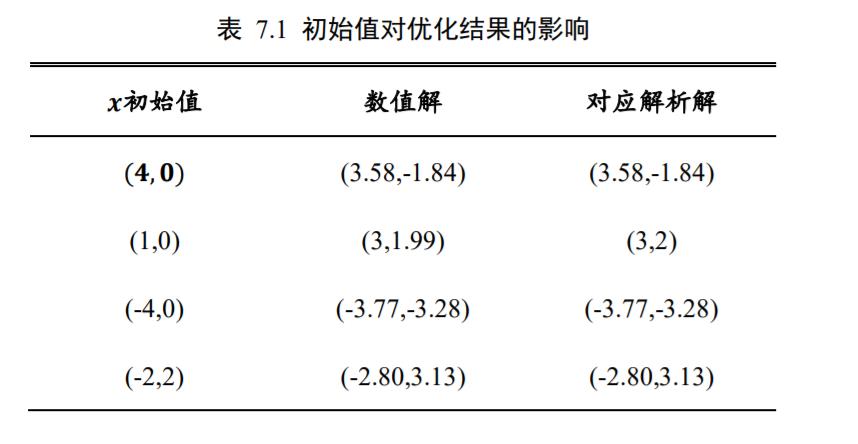
图 7.12 为 Himmelblau 函数的等高线,大致可以看出,它共有 4 个局部极小值点,并且局部极小值都是 0,所以这 4 个局部极小值也是全局最小值。我们可以通过解析的方法计算出局部极小值坐标,他们分别是(3,2), (−2 805, 3 131), (−3 779, −3 283), (3 584, −1 848)。
在已经知道极小值解的情况下,我们现在来用梯度下降算法来优化 Himmelblau 函数的数值极小值解。

利用 TensorFlow 自动求导来求出函数在𝑥, 𝑦的梯度,并循环迭代更新:
# 参数的初始化值对优化的影响不容忽视,可以通过尝试不同的初始化值,
# 检验函数优化的极小值情况
# [1., 0.], [-4, 0.], [4, 0.]
# 初始化参数
x = tf.constant([4., 0.])
for step in range(200):# 循环优化 200 次
with tf.GradientTape() as tape: #梯度跟踪
tape.watch([x]) # 加入梯度跟踪列表
y = himmelblau(x) # 前向传播
# 反向传播
grads = tape.gradient(y, [x])[0]
# 更新参数,0.01 为学习率
x -= 0.01*grads
# 打印优化的极小值
if step % 20 == 19:
print ('step {}: x = {}, f(x) = {}'.format(step, x.numpy(), y.numpy()))
经过 200 次迭代更新后,我们可以找到一个极小值解,此时函数值接近于 0:
step199:x=[ 3.5844283 -1.8481264],f(x)=2.2737367544323206e-13
这与我们的解析之一(3 584, −1 848)几乎一样。
实际上,通过改变网络参数的初始化状态,我们可以得到多种极小值解。参数的初始化状态是可能影响梯度下降算法的搜索轨迹的,甚至有可能搜索出完全不同的数值解,如表格 7.1 所示。这个例子就比较好的解释了不同的初始状态对梯度下降算法的影响。
7.9 反向传播算法实战
本节我们将利用前面介绍的多层全连接层的梯度推导结果,直接利用 Python 循环计算每一层的梯度,并按着梯度下降算法手动更新。由于 TensorFlow 具有自动求导功能,我们选择没有自动求导功能的 Numpy 实现我们的网络,并利用 Numpy 手动计算梯度并更新。
需要注意的是,我们推导的梯度传播公式是针对于多层全连接层,只有 Sigmoid 一种激活函数,并且损失函数为均方差的网络类型。对于其他类型的网络,比如激活函数采用ReLU,损失函数采用交叉熵的网络,需要重新推导梯度传播表达式,方法一样。正是因为手动推导梯度的方法局限性较大,在实践中采用极少,更多的是利用自动求导工具计算。
我们将实现一个 4 层的全连接网络实现二分类任务,网络输入节点数为 2,隐藏层的节点数设计为:25,50,25,输出层 2 个节点,分别表示属于类别 1 的概率和类别 2 的概率,如图 7.13 所示。
我们并没有采用 Softmax 函数将网络输出概率值之和进行约束,而是直接利用均方差误差函数计算与 One-hot 编码的真实标签之间的误差,所有的网络激活函数全部采用 Sigmoid 函数,这些设计都是为了能直接利用我们的梯度推导公式。

7.9.1 数据集
我们通过 scikit-learn 库提供的便捷工具生成 2000 个线性不可分的 2 分类数据集,数据的特征长度为 2,采样出的数据分布如图 7.14 所示,所有的红色点为一类,所有的蓝色点为一类,可以看到数据的分布呈月牙状,并且是是线性不可分的,无法用线性网络获得较好效果。为了测试网络的性能,我们按着7: 3比例切分训练集和测试集,其中2000 ∗ 0.3 =600个样本点用于测试,不参与训练,剩下的 1400 个点用于网络的训练。

数据集的采集使用 scikit-learn 提供的 make_moons 函数生成:
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
N_SAMPLES = 2000 # 采样点数
TEST_SIZE = 0.3 # 测试数量比率
# 利用工具函数直接生成数据集
X, y = make_moons(n_samples = N_SAMPLES, noise=0.2, random_state=100)
# 将 2000 个点按着 7:3 分割为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=TEST_SIZE, random_state=42)
print(X.shape, y.shape)
可以通过如下可视化代码绘制数据集的分布,如图 7.14 所示。
import seaborn as sns
from matplotlib import cm
def make_plot(X, y, plot_name, file_name=None, XX=None, YY=None, preds=None,dark=False):
if (dark):
plt.style.use('dark_background')
else:
sns.set_style("whitegrid")
plt.figure(figsize=(16,12))
axes = plt.gca()
axes.set(xlabel="$x_1$", ylabel="$x_2$")
plt.title(plot_name, fontsize=30)
plt.subplots_adjust(left=0.20)
plt.subplots_adjust(right=0.80)
if(XX is not None and YY is not None and preds is not None):
plt.contourf(XX, YY, preds.reshape(XX.shape), 25, alpha = 1,cmap=cm.Spectral)
plt.contour(XX, YY, preds.reshape(XX.shape), levels=[.5],cmap="Greys", vmin=0, vmax=.6)
# 绘制散点图,根据标签区分颜色
plt.scatter(X[:, 0], X[:, 1], c=y.ravel(), s=40, cmap=plt.cm.Spectral,edgecolors='none')
plt.savefig('dataset.svg')
plt.close()
# 调用 make_plot 函数绘制数据的分布,其中 X 为 2D 坐标,y 为标签
make_plot(X, y, "Classification Dataset Visualization ")
plt.show()
7.9.2 网络层
通过新建类 Layer 实现一个网络层,需要传入网络层的数据节点数,输出节点数,激活函数类型等参数,权值 weights 和偏置张量 bias 在初始化时根据输入、输出节点数自动生成并初始化:
class Layer:
# 全连接网络层
def __init__(self, n_input, n_neurons, activation=None, weights=None,
bias=None):
"""
:param int n_input: 输入节点数
:param int n_neurons: 输出节点数
:param str activation: 激活函数类型
:param weights: 权值张量,默认类内部生成
:param bias: 偏置,默认类内部生成
"""
# 通过正态分布初始化网络权值,初始化非常重要,不合适的初始化将导致网络不收敛
self.weights = weights if weights is not None else np.random.randn(n_input, n_neurons) * np.sqrt(1 / n_neurons)
self.bias = bias if bias is not None else np.random.rand(n_neurons) * 0.1
self.activation = activation # 激活函数类型,如’sigmoid’
self.last_activation = None # 激活函数的输出值o
self.error = None # 用于计算当前层的delta 变量的中间变量
self.delta = None # 记录当前层的delta 变量,用于计算梯度
实现网络层的前向传播如下:
# 网络层的前向传播函数实现如下,其中last_activation 变量用于保存当前层的输出值:
def activate(self, x):
# 前向传播函数
r = np.dot(x, self.weights) + self.bias # X@W+b
# 通过激活函数,得到全连接层的输出o
self.last_activation = self._apply_activation(r)
return self.last_activation
其中 self._apply_activation 实现了不同的激活函数的前向计算过程:
# 上述代码中的self._apply_activation 函数实现了不同类型的激活函数的前向计算过程,
# 尽管此处我们只使用Sigmoid 激活函数一种。代码如下:
def _apply_activation(self, r):
# 计算激活函数的输出
if self.activation is None:
return r # 无激活函数,直接返回
# ReLU 激活函数
elif self.activation == 'relu':
return np.maximum(r, 0)
# tanh 激活函数
elif self.activation == 'tanh':
return np.tanh(r)
# sigmoid 激活函数
elif self.activation == 'sigmoid':
return 1 / (1 + np.exp(-r))
return r
针对于不同的激活函数,它们的导数计算实现如下:
# 针对于不同类型的激活函数,它们的导数计算实现如下:
def apply_activation_derivative(self, r):
# 计算激活函数的导数
# 无激活函数,导数为1
if self.activation is None:
return np.ones_like(r)
# ReLU 函数的导数实现
elif self.activation == 'relu':
grad = np.array(r, copy=True)
grad[r > 0] = 1.
grad[r <= 0] = 0.
return grad
# tanh 函数的导数实现
elif self.activation == 'tanh':
return 1 - r ** 2
# Sigmoid 函数的导数实现
elif self.activation == 'sigmoid':
return r * (1 - r)
return r
可以看到,Sigmoid 函数的导数实现为𝑟 ∗ (1 − 𝑟),其中𝑟即为𝜎(𝑧)。
7.9.3 网络模型
实现单层网络类后,我们实现网络模型的类 NeuralNetwork,它内部维护各层的网络层Layer 类对象,可以通过 add_layer 函数追加网络层,实现如下:
# 神经网络模型
class NeuralNetwork:
def __init__(self):
self._layers = [] # 网络层对象列表
def add_layer(self, layer):
# 追加网络层
self._layers.append(layer)
网络的前向传播只需要循环调用各网络层对象的前向计算函数即可:
# 网络的前向传播只需要循环调各个网络层对象的前向计算函数即可,代码如下:
# 前向传播
def feed_forward(self, X):
for layer in self._layers:
# 依次通过各个网络层
X = layer.activate(X)
return X
实例化网络对象,添加 4 层全连接层:
nn = NeuralNetwork() # 实例化网络类
nn.add_layer(Layer(2, 25, 'sigmoid')) # 隐藏层 1, 2=>25
nn.add_layer(Layer(25, 50, 'sigmoid')) # 隐藏层 2, 25=>50
nn.add_layer(Layer(50, 25, 'sigmoid')) # 隐藏层 3, 50=>25
nn.add_layer(Layer(25, 2, 'sigmoid')) # 输出层, 25=>2
网络模型的反向传播实现稍复杂,需要从最末层开始,计算每层的𝛿变量,根据我们推导的梯度公式,将计算出的𝛿变量存储在 Layer 类的 delta 变量中。
def backpropagation(self, X, y, learning_rate):
# 反向传播算法实现
# 前向计算,得到输出值
output = self.feed_forward(X)
for i in reversed(range(len(self._layers))): # 反向循环
layer = self._layers[i] # 得到当前层对象
# 如果是输出层
if layer == self._layers[-1]: # 对于输出层
layer.error = y - output # 计算2 分类任务的均方差的导数
# 关键步骤:计算最后一层的delta,参考输出层的梯度公式
layer.delta = layer.error * layer.apply_activation_derivative(output)
else: # 如果是隐藏层
next_layer = self._layers[i + 1] # 得到下一层对象
layer.error = np.dot(next_layer.weights, next_layer.delta)
# 关键步骤:计算隐藏层的delta,参考隐藏层的梯度公式
layer.delta = layer.error * layer.apply_activation_derivative(layer.last_activation)
# 循环更新权值
for i in range(len(self._layers)):
layer = self._layers[i]
# o_i 为上一网络层的输出
o_i = np.atleast_2d(X if i == 0 else self._layers[i - 1].last_activation)
# 梯度下降算法,delta 是公式中的负数,故这里用加号
layer.weights += layer.delta * o_i.T * learning_rate
在反向计算完每层的𝛿变量后,只需要按着 ∂ L ∂ w i j \frac{\partial \mathcal{L}}{\partial w_{i j}} ∂wij∂L= O i δ j J O_{i} \delta_{j}^{J} OiδjJ公式计算每层的梯度,并更新网络参数即可。由于代码中的 delta 计算的是−𝛿,因此更新时使用了加号。
def backpropagation(self, X, y, learning_rate):
… # 代码接上面
# 循环更新权值
for i in range(len(self._layers)):
layer = self._layers[i]
# o_i 为上一网络层的输出
o_i = np.atleast_2d(X if i == 0 else self._layers[i -1].last_activation)
# 梯度下降算法,delta 是公式中的负数,故这里用加号
layer.weights += layer.delta * o_i.T * learning_rate
因此,在 backpropagation 函数中,反向计算每层的𝛿变量,并根据梯度公式计算每层参数的梯度值,按着梯度下降算法完成一次参数的更新。
7.9.4 网络训练
我们的二分类任务网络设计为 2 个输出节点,因此需要将真实标签 y 进行 one-hot 编码:
def train(self, X_train, X_test, y_train, y_test, learning_rate, max_epochs):
# 网络训练函数
# one-hot 编码
y_onehot = np.zeros((y_train.shape[0], 2))
y_onehot[np.arange(y_train.shape[0]), y_train] = 1
将 one-hot 编码后的真实标签与网络的输出计算均方差,并调用反向传播函数更新网络参数,循环迭代训练集 1000 遍:
# 将One-hot 编码后的真实标签与网络的输出计算均方误差,并调用反向传播函数更新网络参数,循环迭代训练集1000 遍即可
mses = []
accuracys = []
for i in range(max_epochs + 1): # 训练1000 个epoch
for j in range(len(X_train)): # 一次训练一个样本
self.backpropagation(X_train[j], y_onehot[j], learning_rate)
if i % 10 == 0:
# 打印出MSE Loss
mse = np.mean(np.square(y_onehot - self.feed_forward(X_train)))
mses.append(mse)
accuracy = self.accuracy(self.predict(X_test), y_test.flatten())
accuracys.append(accuracy)
print('Epoch: #%s, MSE: %f' % (i, float(mse)))
# 统计并打印准确率
print('Accuracy: %.2f%%' % (accuracy * 100))
return mses, accuracys
7.9.5 网络性能
我们将每个 epoch 的损失ℒ记录下,并绘制为曲线,如图 7.15 所示。

在训练完 1000 个 epoch 后,在测试集 600 个样本上得到的准确率为
Epoch: #990, MSE: 0.024335
Accuracy: 97.67%
可以看到,通过手动计算梯度公式并手动更新网络参数的方式,我们在简单的二分类任务上也能获得了较低的错误率。通过精调网络超参数,还可以获得更好的网络性能。
在每个 epoch,我们在测试集上完成一次准确度测试,并绘制成曲线,如图 7.16 所示。

所有代码:
#!/usr/bin/env python
# encoding: utf-8
"""
@author: HuRuiFeng
@file: 7.9-backward-prop.py
@time: 2020/2/24 17:32
@desc: 7.9 反向传播算法实战的代码
"""
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
plt.rcParams['font.size'] = 16
plt.rcParams['font.family'] = ['STKaiti']
plt.rcParams['axes.unicode_minus'] = False
def load_dataset():
# 采样点数
N_SAMPLES = 2000
# 测试数量比率
TEST_SIZE = 0.3
# 利用工具函数直接生成数据集
X, y = make_moons(n_samples=N_SAMPLES, noise=0.2, random_state=100)
# 将 2000 个点按着 7:3 分割为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=TEST_SIZE, random_state=42)
return X, y, X_train, X_test, y_train, y_test
def make_plot(X, y, plot_name, XX=None, YY=None, preds=None, dark=False):
# 绘制数据集的分布, X 为 2D 坐标, y 为数据点的标签
if (dark):
plt.style.use('dark_background')
else:
sns.set_style("whitegrid")
plt.figure(figsize=(16, 12))
axes = plt.gca()
axes.set(xlabel="$x_1$", ylabel="$x_2$")
plt.title(plot_name, fontsize=30)
plt.subplots_adjust(left=0.20)
plt.subplots_adjust(right=0.80)
if XX is not None and YY is not None and preds is not None:
plt.contourf(XX, YY, preds.reshape(XX.shape), 25, alpha=1, cmap=plt.cm.Spectral)
plt.contour(XX, YY, preds.reshape(XX.shape), levels=[.5], cmap="Greys", vmin=0, vmax=.6)
# 绘制散点图,根据标签区分颜色
plt.scatter(X[:, 0], X[:, 1], c=y.ravel(), s=40, cmap=plt.cm.Spectral, edgecolors='none')
plt.savefig('数据集分布.svg')
plt.close()
class Layer:
# 全连接网络层
def __init__(self, n_input, n_neurons, activation=None, weights=None,
bias=None):
"""
:param int n_input: 输入节点数
:param int n_neurons: 输出节点数
:param str activation: 激活函数类型
:param weights: 权值张量,默认类内部生成
:param bias: 偏置,默认类内部生成
"""
# 通过正态分布初始化网络权值,初始化非常重要,不合适的初始化将导致网络不收敛
self.weights = weights if weights is not None else np.random.randn(n_input, n_neurons) * np.sqrt(1 / n_neurons)
self.bias = bias if bias is not None else np.random.rand(n_neurons) * 0.1
self.activation = activation # 激活函数类型,如’sigmoid’
self.last_activation = None # 激活函数的输出值o
self.error = None # 用于计算当前层的delta 变量的中间变量
self.delta = None # 记录当前层的delta 变量,用于计算梯度
# 网络层的前向传播函数实现如下,其中last_activation 变量用于保存当前层的输出值:
def activate(self, x):
# 前向传播函数
r = np.dot(x, self.weights) + self.bias # X@W+b
# 通过激活函数,得到全连接层的输出o
self.last_activation = self._apply_activation(r)
return self.last_activation
# 上述代码中的self._apply_activation 函数实现了不同类型的激活函数的前向计算过程,
# 尽管此处我们只使用Sigmoid 激活函数一种。代码如下:
def _apply_activation(self, r):
# 计算激活函数的输出
if self.activation is None:
return r # 无激活函数,直接返回
# ReLU 激活函数
elif self.activation == 'relu':
return np.maximum(r, 0)
# tanh 激活函数
elif self.activation == 'tanh':
return np.tanh(r)
# sigmoid 激活函数
elif self.activation == 'sigmoid':
return 1 / (1 + np.exp(-r))
return r
# 针对于不同类型的激活函数,它们的导数计算实现如下:
def apply_activation_derivative(self, r):
# 计算激活函数的导数
# 无激活函数,导数为1
if self.activation is None:
return np.ones_like(r)
# ReLU 函数的导数实现
elif self.activation == 'relu':
grad = np.array(r, copy=True)
grad[r > 0] = 1.
grad[r <= 0] = 0.
return grad
# tanh 函数的导数实现
elif self.activation == 'tanh':
return 1 - r ** 2
# Sigmoid 函数的导数实现
elif self.activation == 'sigmoid':
return r * (1 - r)
return r
# 神经网络模型
class NeuralNetwork:
def __init__(self):
self._layers = [] # 网络层对象列表
def add_layer(self, layer):
# 追加网络层
self._layers.append(layer)
# 网络的前向传播只需要循环调各个网络层对象的前向计算函数即可,代码如下:
# 前向传播
def feed_forward(self, X):
for layer in self._layers:
# 依次通过各个网络层
X = layer.activate(X)
return X
def backpropagation(self, X, y, learning_rate):
# 反向传播算法实现
# 前向计算,得到输出值
output = self.feed_forward(X)
for i in reversed(range(len(self._layers))): # 反向循环
layer = self._layers[i] # 得到当前层对象
# 如果是输出层
if layer == self._layers[-1]: # 对于输出层
layer.error = y - output # 计算2 分类任务的均方差的导数
# 关键步骤:计算最后一层的delta,参考输出层的梯度公式
layer.delta = layer.error * layer.apply_activation_derivative(output)
else: # 如果是隐藏层
next_layer = self._layers[i + 1] # 得到下一层对象
layer.error = np.dot(next_layer.weights, next_layer.delta)
# 关键步骤:计算隐藏层的delta,参考隐藏层的梯度公式
layer.delta = layer.error * layer.apply_activation_derivative(layer.last_activation)
# 循环更新权值
for i in range(len(self._layers)):
layer = self._layers[i]
# o_i 为上一网络层的输出
o_i = np.atleast_2d(X if i == 0 else self._layers[i - 1].last_activation)
# 梯度下降算法,delta 是公式中的负数,故这里用加号
layer.weights += layer.delta * o_i.T * learning_rate
def train(self, X_train, X_test, y_train, y_test, learning_rate, max_epochs):
# 网络训练函数
# one-hot 编码
y_onehot = np.zeros((y_train.shape[0], 2))
y_onehot[np.arange(y_train.shape[0]), y_train] = 1
# 将One-hot 编码后的真实标签与网络的输出计算均方误差,并调用反向传播函数更新网络参数,循环迭代训练集1000 遍即可
mses = []
accuracys = []
for i in range(max_epochs + 1): # 训练1000 个epoch
for j in range(len(X_train)): # 一次训练一个样本
self.backpropagation(X_train[j], y_onehot[j], learning_rate)
if i % 10 == 0:
# 打印出MSE Loss
mse = np.mean(np.square(y_onehot - self.feed_forward(X_train)))
mses.append(mse)
accuracy = self.accuracy(self.predict(X_test), y_test.flatten())
accuracys.append(accuracy)
print('Epoch: #%s, MSE: %f' % (i, float(mse)))
# 统计并打印准确率
print('Accuracy: %.2f%%' % (accuracy * 100))
return mses, accuracys
def predict(self, X):
return self.feed_forward(X)
def accuracy(self, X, y):
return np.sum(np.equal(np.argmax(X, axis=1), y)) / y.shape[0]
def main():
X, y, X_train, X_test, y_train, y_test = load_dataset()
# 调用 make_plot 函数绘制数据的分布,其中 X 为 2D 坐标, y 为标签
make_plot(X, y, "Classification Dataset Visualization ")
plt.show()
nn = NeuralNetwork() # 实例化网络类
nn.add_layer(Layer(2, 25, 'sigmoid')) # 隐藏层 1, 2=>25
nn.add_layer(Layer(25, 50, 'sigmoid')) # 隐藏层 2, 25=>50
nn.add_layer(Layer(50, 25, 'sigmoid')) # 隐藏层 3, 50=>25
nn.add_layer(Layer(25, 2, 'sigmoid')) # 输出层, 25=>2
mses, accuracys = nn.train(X_train, X_test, y_train, y_test, 0.01, 1000)
x = [i for i in range(0, 101, 10)]
# 绘制MES曲线
plt.title("MES Loss")
plt.plot(x, mses[:11], color='blue')
plt.xlabel('Epoch')
plt.ylabel('MSE')
plt.savefig('训练误差曲线.svg')
plt.close()
# 绘制Accuracy曲线
plt.title("Accuracy")
plt.plot(x, accuracys[:11], color='blue')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.savefig('网络测试准确率.svg')
plt.close()
if __name__ == '__main__':
main()
通过这个手动实现的二分类全连接网络,相信读者朋友们能够更加深刻地体会到深度学习框架在算法实现中的角色。没有诸如 TensorFlow 这些框架,我们同样能够实现复杂的神经网络,但是灵活性、稳定性、开发效率和计算效率都较差,基于这些深度学习框架进行算法设计与训练,将大大提升算法开发人员的工作效率。同时我们也能意识到,框架只是一个工具,更重要的是,我们对算法本身的理解,这才是算法开发者最重要的能力。
















 1351
1351











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











