







《Locate, Size and Count: Accurately Resolving People in Dense Crowds via Detection》(2020)
这是一篇利用检测的方法进行人群计数的文章。
贡献及创新点:
- 使用检测的方法进行人群计数;
- 设计了一个新颖的CNN框架,不同于传统的目标检测器,该方法可以在高分辨率图像上精确定位人头;
- 设计了一个与从上到下反馈结构相融合的方案,这使得网络可以联合处理多尺度信息,方便网络更好地定位人头;
- 在仅有点标注信息的情况下,可以预测每个人头的bounding box;
- 设计了一个新的winner-take-all的loss,有利于在高分辨率的图像上进行训练。
方法介绍
LST-CNN是一个端到端的单阶段的方法。LST-CNN可以同时处理多个多尺度信息并在多个分辨率图像上进行预测,多个分辨率图像上的输出构成最终的预测结果。LST-CNN的结构图如下,在训练时,LST-CNN对GWTA训练阶段生成的伪ground truth进行像素级分类以完成网络优化。
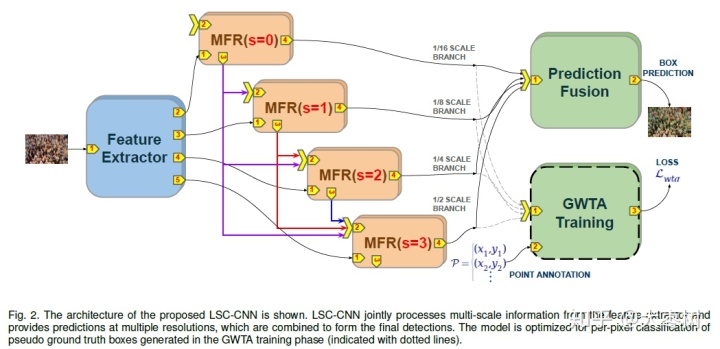
LST-CNN有三个功能模块。
- 首先,Feature Extractor在多个分辨率图像上提取特征;
- 然后,多尺度特征图被输入到一系列的Multi-scale Feedback Reasoning(MFR)单元中,之后经过提取的特征进行融合,并用于预测box。
- 最后,Non-Maximum Suppression(NMS)从多个分辨率图像上确定有效的预测结果,并结合生成最终结果。
为了训练模型,最后的一个阶段使用了GWTA模块。GWTA模块使用了winnners-take-all(WTA)loss,可以挑选合适的ground truth box。
-------------------------------------------
人头定位
Feature Extractor
这部分网络的输入是224×224大小的RGB图像,其结构采用了VGG-16的前五个卷积块,并做了相应的修改,其结构如下:
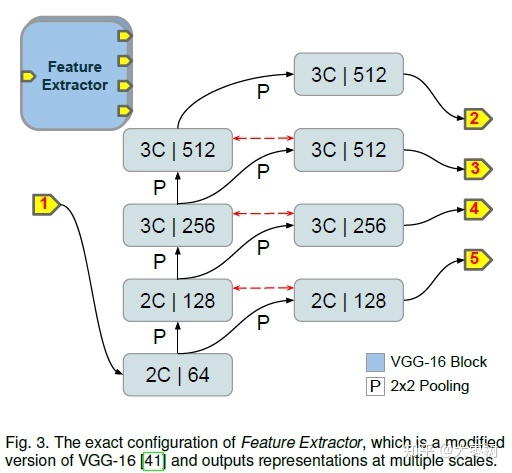
Feature extractor生成
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2531
2531











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









