






GPU加速子图同构算法
作者: 曾立 邹磊 M. Tamer Özsu 胡琳 张藩
论文链接:https://arxiv.org/abs/1906.03420

本次论文讲解的是曾立、邹磊、M. Tamer Özsu、胡琳、张藩等作者在 ICDE 2020上发表的论文 GSI: GPU-friendly SubgraphIsomorphism,主要是分享一些阅读论文的收获,希望能对正在学习GPU图计算的初学者带来一些启发。

本文将先对图模型和子图同构算法作基本的介绍,然后介绍相关的背景知识,如GPU的体系结构和GPU上做子图同构算法的最新研究等等。
接着,本文将主要介绍 GSI算法及其优化。
最后是实验和总结。
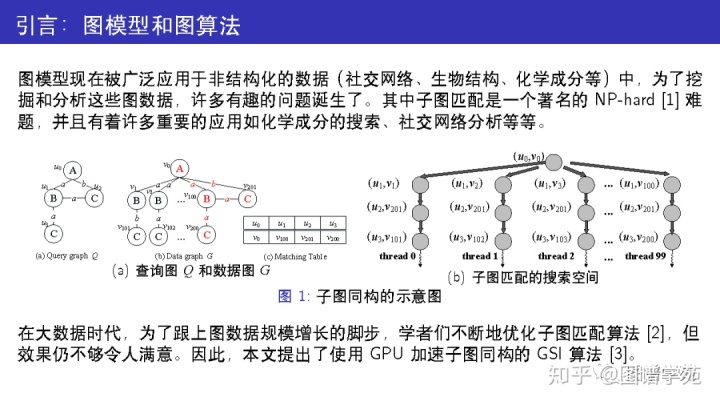
子图同构是互联网搜索与挖掘中常见的问题,给定查询图 Q 和数据图G(如图 1(a)),我们需要找出 Q 在G中所有的匹配。由于该问题的搜索空间是指数级别的(如图 1(b)),串行算法无法处理大图。在图 1(b) 中,不同搜索路径的求解是相互独立的,因此学者们尝试引入 GPU 的高并发特性来帮助解决这个难题。

这里给出了子图同构的严格定义。在本文中主要讨论的图是无向图,且同时带点标签和边标签。GSI算法也可以很自然地拓展到有向图上。
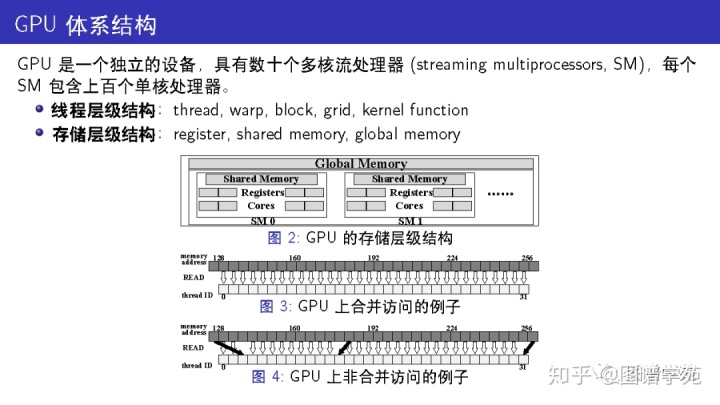
CUDA 编程模型提供了对这些处理器进行编程的方法,对应着一个线程层级结构。
每个核都被匹配到一个线程,而一个 warp包含 32 个连续的线程且这些线程以 SIMD 形式运行。当一个 warp 运行到一处分支 (if-else 或者是循环) 的时候,其他线程必须等待,即便只有一部分线程要运行一个特定的分支。这就是众所周知的 “线程发散”(warp divergence)。一个 block由一系列连续的 warp 组成,每个 block 只会驻留在一个 SM 上。GPU 上启动的每个进程被称为一个 “核函数” (kernel function) ,每个核函数会占据一个独立的网格 grid,每个网格包含若干个同等大小的 block。在一个 block 中的线程可以被显示同步,但 block 之间没有直接的同步 API 接口,除非等整个核函数完全结束。每个 SM 上可以有多个 SM 驻留,每个网格和 block 的具体大小由程序员自行决定。
其中全局显存 (global memory) 是最大也最慢的一层存储,也是 GPU 上直接与主存通信的部分。每个 SM 拥有一个私有的可编程的高速缓存,被称作 “共享内存” (shared memory),一个block内所有线程都可以访问这个 block 申请的共享内存。虽然共享内存的容量很有限 (比如 Titan XP 上每个 SM 只有 48KB 共享内存),但它几乎和线程私有的寄存器一样快。对全局显存的访问是通过 128B 大小的块传输来进行的,并且延迟是访问共享内存的数百倍。如果一个 warp 中的线程以一种连续对齐的方式访问全局显存,需要传输的块更少,因此吞吐量更高。
在图3中,因为是连续对齐的访问,所以只需要一次块传输即可完成。
而在图4中,因为访问没有对齐,一共需要三次块传输。

虽然 GPU 支持大规模并行,对其粗浅的使用也可能带来比细致调优后的CPU 实现更差的结果。
将图算法移植到 GPU 上,会面临三个主要的挑战,接下来我们将简单讨论它们。
1. 如果有足够多的线程,那么图 1(b) 中所有路径都可以并行化。但这是不现实的,而且大量重复的工作会严重降低性能。
2. 大图只能放在全局存储中,其它层级的存储都放不下。在这种场景下,由于图结构的不规则性我们很难合并访存,因此会增加访存延迟。
3. 当每个处理单元的任务量都相同时,GPU表现最好。但是,在真实图中,不同节点的邻居数量非常不同,甚至有些是呈 “幂律分布”的。这会带来block间、warp间和线程间严重的负载不均衡。均衡负载才是更优的做法,因为总的时间开销始终是被最长的一个负载决定的。
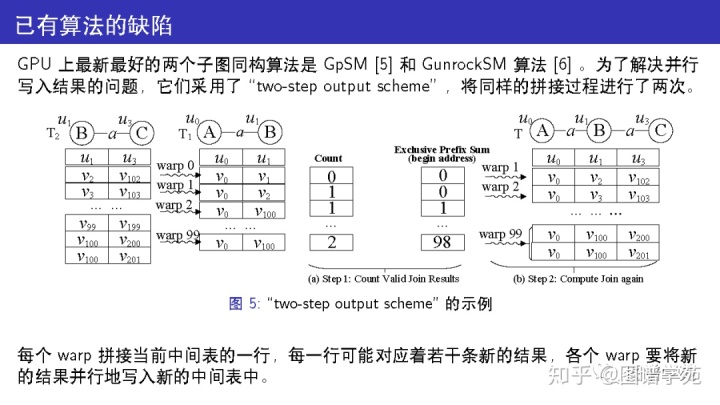
GpSM和GunrockSM也是我们的算法主要对比的算法,它们都使用了宽度优先的扩展模式,因此更适合并行。
对于图 1的样例,图 5 给出了two-step output scheme的具体流程。
中间表 T1和 T2 分别代表查询图 Q的边 (u0,u1) 和 (u1,u3) 在数据图 G 中的候选匹配。
为了获得由节点 u0、u1 和 u3导出的子图的匹配, GpSM 需要进行一次自然连接:T1和 T2。
每个warp拼接当前中间表的一行,每一行可能对应着若干条新的结果,各个warp要将新的结果并行地写入新的中间表中。
并行意味着它们不能像串行情况下那样将结果追加到末尾(如果要实现串行,那必须加锁,加锁的代价非常高),因此现有的策略是将拼接过程做两次:第一次找到每行的匹配数量,然后计算出每行结果在新的中间表中的写入地址(通过一个前缀和计算,prefix-sum);第二次根据之前计算好的地址将所有结果并行地写入新的中间表。
除了使用 two-step output scheme 这点外, GpSM 和 GunrockSM 都缺乏对 GPU 特性的利用,因此它们的负载不均衡(比如各warp的任务量很不一样)和访存延迟(GPU上的处理器访问GPU上global memory的延迟)都非常严重。这些缺陷使得这两个已有算法无法充分发挥GPU的性能,在大图上表现不佳。

GSI 算法由过滤和拼接两部分组成,这两个阶段都是在GPU 上进行的,都针对 GPU的体系特点进行了优化。 其中过滤阶段会得到每个查询点的候选集,而拼接阶段会将这些候选集拼接成最终的结果表。
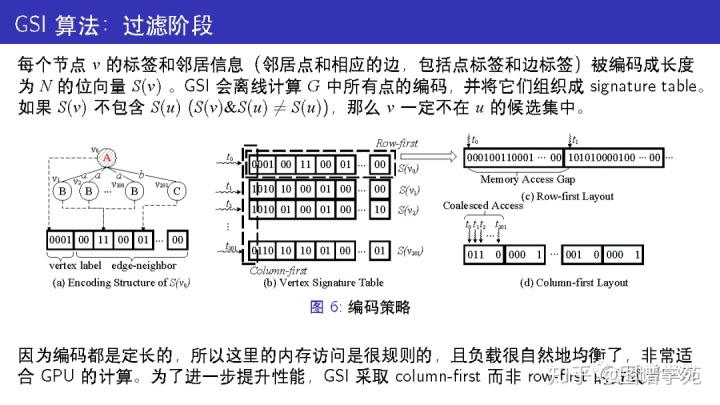
每个节点的编码分为两部分:节点的标签哈希到的区域,以及节点相连的边哈希到的区域。
第二个区域又被分为若干组,每组由 2bits组成。如果没有边哈希到这组,记为00;如果只有一条边哈希到这组,记为01;如果有两条及以上的边哈希到这组,记为 11。
在 row-first 的存储方式中,一个warp的32个线程的访存地址是不连续的,所以无法合并访存,需要更多的访存操作。
而在column-first的存储方式中,一个warp的32个线程的访存地址是连续的,因此每轮读取中只需要一次访存操作。
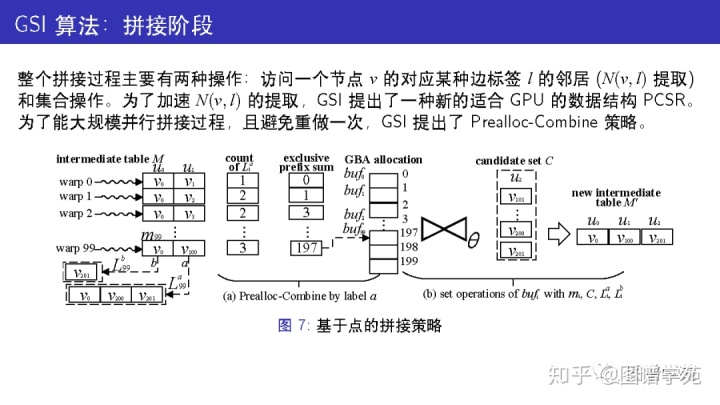
与 GpSM 和 GunrockSM 不同, GSI 使用的是基于点拼接的策略,而非基于边拼接的策略。
每轮会拼接当前的中间表以及一个新的查询点u的候选表,从而生成新的中间表。
每个 warp处理中间表的一行,需要提取这行元素的邻接表,并和候选表作交集运算。
因为各行都可能对应着若干条结果,各warp间是并发执行的,所以会有并行写入结果的问题。
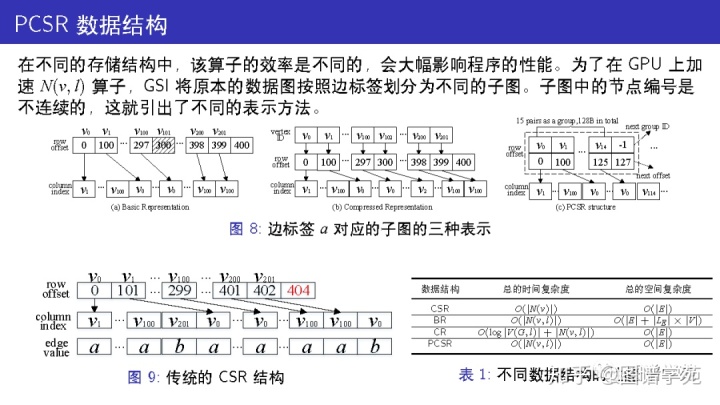
GPU上的图算法一般都使用 CSR作为数据结构,因为它比邻接表更紧凑。图 9给出了对应图1的CSR结构,在这个结构中提取N(v,l)必须先提取v的所有邻居然后逐一判断边标签是否为l,这毫无疑问是非常低效的。
GSI 将原本的数据图按照边标签划分为不同的子图,从而N(v,l) 是被紧密排在一起的。比如边标签a 对应的子图如图 8 所示,在这个子图中 v101 节点是不存在的。因为节点编号不连续,这就牵涉到一个定位问题。
图 8(a)中为每个子图维护了所有节点的大数组,因此可以在 O(1)时间获得邻接表的位置。但如果边标签数量很多,这种表示方法的空间代价是不可承受的。图 8(b)中为每个子图额外维护了一层节点的ID,从而可以作二分查找。这种表示方法的空间代价很小,但是查找代价较高。
因此,GSI提出了新的 PCSR 结构,如图 8(c) 所示。在PCSR结构中,节点的ID会先被哈希至某个 group。每个group的大小是按照GPU显存传输的单位来设置的,即128B。一个group最多可以存放15个点ID,如果有溢出,则可以另外找一个空的group来存放。在PCSR中,定位点的邻接表N(v,l)只需要一次访存,空间开销也较小,因此非常高效。表 1给出了这些结构的性能分析。

为了能并行地写入新的结果,GSI 提出了一种新的拼接方法。
先估算每行的新结果数量的上界,然后按照这个上界给它们在显存分配缓冲区。
拼接过程中,新结果可以先写入缓冲区中保存起来,等新的中间表分配好后,再把这些新结果写入到新的中间表中。
通过这种方式,无需重做拼接过程,因此节省了大量的工作量。

第8行的差集运算主要是为了满足同构的要求,匹配中不能有重复的节点。
在第8-11行中,可能存在大量的无效的元素,所以对显存的写操作是比较低效的。
比如32个线程读取了32个元素,其中只有一个元素是有效的,那么一次显存传输 (128B) 只用到了 4B。
因此,GSI 借由 shared memory 为每个warp实现了写缓存 (128B),只有写缓存满了,才会一次性刷到显存中。
负载均衡策略:根据邻接表的大小分别考虑。特别大的邻接表,单独启动一个新的核函数去处理;较大的邻接表,用整个block去处理;规模一般的邻接表,用多个warp协同处理;较小的邻接表,直接用整个warp来处理。
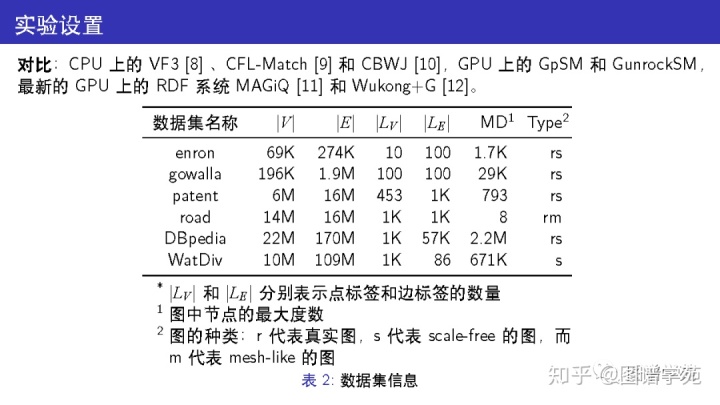
本文在实验中对比了 CPU 上的三个算法和 GPU 上的四个算法,所用的数据集除了 WatDiv 之外都是真实数据集,涵盖了社交网络和道路网络等多个领域。 其中,WatDiv 和 DBpedia两个数据集的边数已经达到了亿级。
GSI算法分为两个版本,一个是基础实现 GSI,另一个是加上优化(负载均衡和共享输入缓冲区)后的实现 GSI-opt。
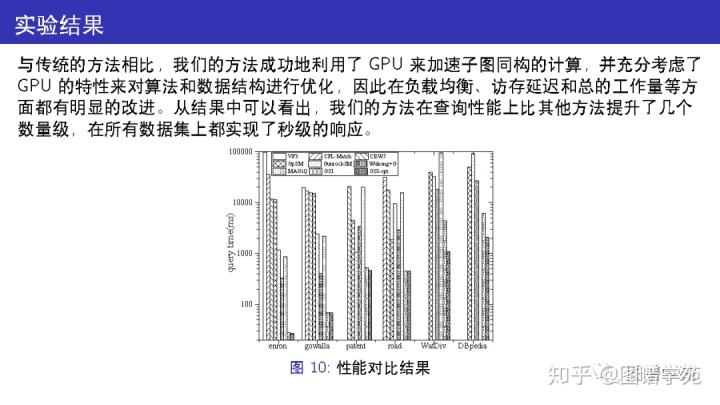
与已有的方法相比,我们的方法成功地利用了GPU 来加速子图同构的计算,并充分考虑了GPU 的特性来对算法和数据结构进行优化,因此在负载均衡、访存延迟和总的工作量等方面都有明显的改进。
从结果中可以看出,GSI在查询性能上比其他方法提升了几个数量级,在所有数据集上都实现了秒级的响应。
References
[1] M. R. Garey and David S. Johnson.Computers and Intractability: A Guide to the Theory of NP-Completeness.W. H. Freeman, 1979.
[2] Donatello Conte, Pasquale Foggia, Carlo Sansone, and Mario Vento.Thirty years of graph matching in pattern recognition.IJPRAI, 18(3):265–298, 2004.
[3] Li Zeng, Lei Zou, M. Tamer Özsu, Lin Hu, and Fan Zhang.Gsi: Gpu-friendly subgraph isomorphism.ICDE, 2020.
[4] Martin Burtscher, Rupesh Nasre, and Keshav Pingali.A quantitative study of irregular programs on http://gpus.In IISWC, 2012.
[5] Ha Nguyen Tran, Jung-jae Kim, and Bingsheng He.Fast subgraph matching on large graphs using graphics http://processors.In DASFAA, 2015.
[6] Leyuan Wang, Yangzihao Wang, and John D. Owens.Fast parallel subgraph matching on the gpu.HPDC, 2016.
[7] Hung Q. Ngo, Ely Porat, Christopher Ré, and Atri Rudra.Worst-case optimal join algorithms: [extended abstract].In PODS, 2012.
[8] Vincenzo Carletti, Pasquale Foggia, Alessia Saggese, and Mario Vento. Challenging the time complexity of exact subgraph isomorphism forhuge and dense graphs with VF3.
IEEE Trans. Pattern Anal. Mach. Intell., 40(4):804–818, 2018.
[9] Fei Bi, Lijun Chang, Xuemin Lin, Lu Qin, and Wenjie Zhang.Efficient subgraph matching by postponing cartesian http://products.In Proceedings of the 2016 International Conference on Management of Data, SIGMOD Conference 2016, SanFrancisco, CA, USA, June 26 - July 01, 2016, pages 1199–1214, 2016.
[10] Amine Mhedhbi and Semih Salihoglu.Optimizing subgraph queries by combining binary and worst-case optimal joins.VLDB, 2019.
[11] Fuad Jamour et al.Matrix algebra framework for portable, scalable and efficient query engines for rdf http://graphs.In EuroSys, 2019.
[12] Siyuan Wang et al.Fast and concurrent rdf queries using rdma-assisted gpu graph http://exploration.In USENIX ATC, 2018.
作者:北京大学 曾立
非授权不可转载
微信公众号、知乎号“图谱学苑”每周发布最新知识图谱动态,专业知识图谱相关论文导读,欢迎关注投稿。














 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









