







电商软件的“猜你喜欢”究竟是怎么猜出来的?视频软件为什么给我推荐“大长腿”的跳舞视频?背后的逻辑到底是什么?
今天我们采访了“大数据团队-算法组”一位10年+互联网搜推经验的技术专家,让他带领我们从技术的视角来理解下个性化推荐系统背后的原理,以及其对应的业务视角。
是什么?
推荐系统是连接用户和内容的工具,因为信息爆炸,用户检索需求内容的成本逐渐提高,故推荐系统应运而生。
能干什么?
- 信息过载:推荐系统像是个贴心小助手一样,能帮你从一大堆选择中筛选出你个人喜好和兴趣的内容。
- 个性化需求:推荐系统会根据你的历史行为和个人特点,让你体验到独特的服务。
- 发现新内容:推荐系统可以帮你发现那些可能你还没发现但超级适合你的东西。
- 提高用户体验:目标通常是提升用户留存或者是点赞、转发率。
- 提升收入:在电商的场景,根据用户的历史的购买行为,推荐相关的产品,提高GMV,从而提升收入。
怎么来的?
推荐系统用到的数据:用户数据、内容数据
- 用户数据:用户画像(性别、学历等)、兴趣爱好、在线时长等
- 内容数据:商品类目(护肤、面霜、酒等)、商品收藏比、品牌(欧莱雅、雅斯兰黛、MAC魅可等)、成分等
推荐系统一般会有若干个阶段:
- 索引&特征:会根据内容特性提前建立若干种类型的索引
- 过滤阶段:做业务上自定义逻辑,例如消重(内容重复、同类型内容重复),管控和用户主动屏蔽的「物品」标签与敏感词
- 召回阶段:用户请求时会从各种索引中取出百/千个「物品」
- 排序阶段:基于用户兴趣和平台策略对内容进行排序
- 粗排阶段: 针对召回回来的「物品」,进行第一遍打分,筛选出几百条或者千条。这个阶段的排序模型一般都比较简单,能够过滤掉一些与用户兴趣不相关的
- 精排阶段: 在得到数百个「物品」后,精排阶段将建立更精细的模型,结合用户画像、偏好、上下文以及业务目标进行排序。经过精排后的「物品」数量通常在50-100个之间
- 重排阶段:优化「物品」多样性、产品策略逻辑、热门、置顶以及其他「物品」(如广告、推广和政治任务等)的位置混合。重排后的「物品」数量保持在5-10个之间。
流程图
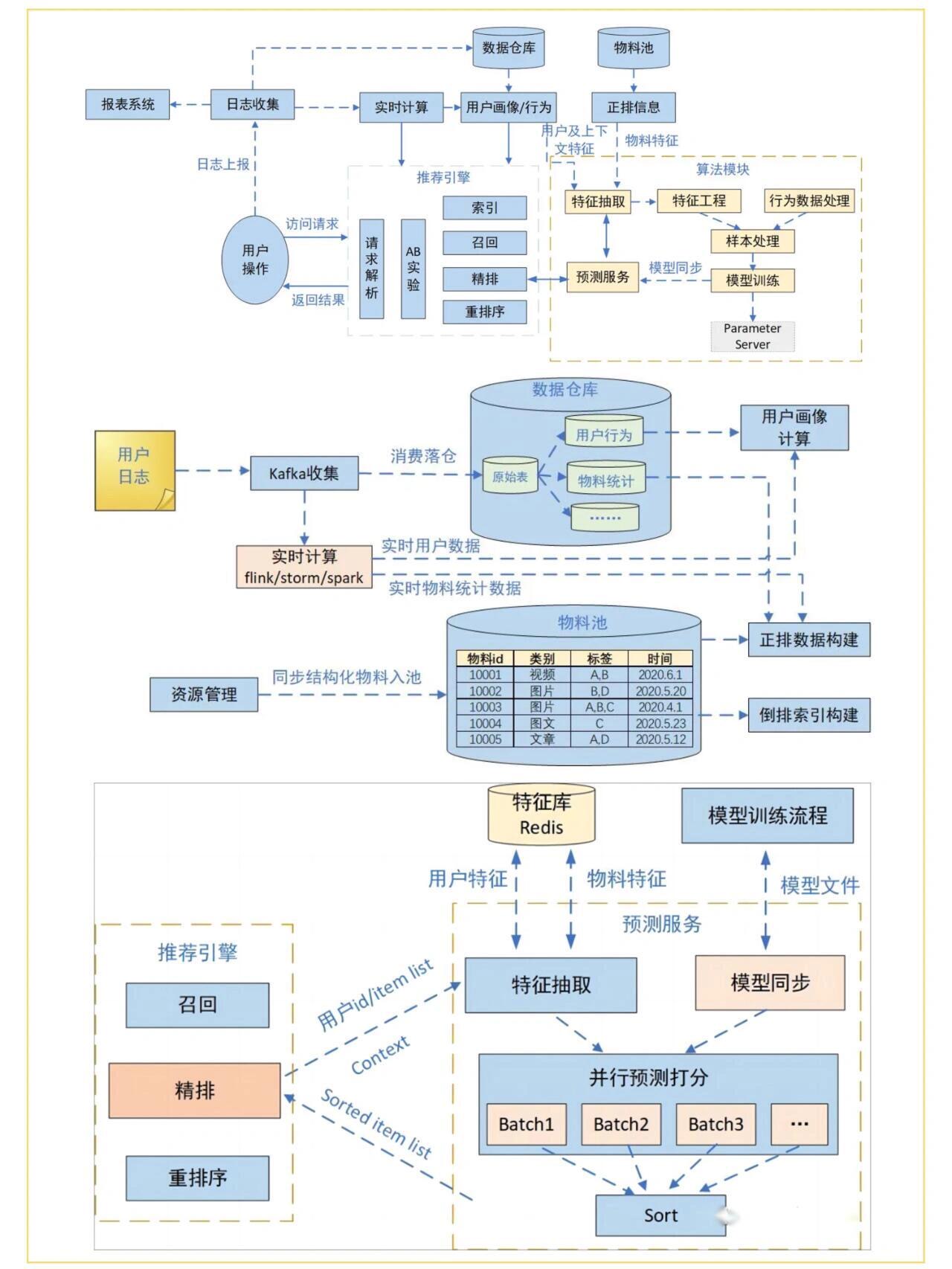
意义/目标
推荐系统的作用/意义:
- 用户角度:推荐系统解決在“信息过载”的情况下,用户如何从海量信息中高效获得感兴趣信息的问题。
- 推荐系统是在用户需求并不十分明确的情况下,进行信息的过滤。因此,与搜索系统(用户会输入明确的搜索词 query)相比,推荐系统更多地利用用户的各类历史信息“猜测”可能喜欢的内容。
- 公司角度:推荐系统解决产品能够最大限度地吸引用户、留存用户、增加用户黏性、提高用户转化率的问题,从而达到公司商业目标连续增长(增加公司收益)的目的。
推荐系统的终极优化目标:包括以下两个维度:
- 一个维度是用户体验的优化
- 另一个维度是满足公司的商业利益
对一个健康的商业模式来说,以上两个维度应该是和谐统一的
业务角色架构
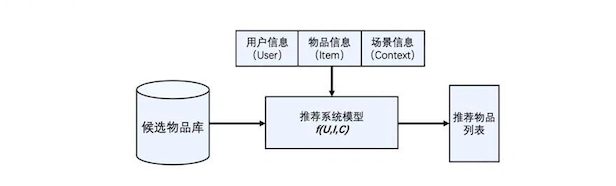
- 物品信息:商品推荐中的商品信息,视频推荐中的视频信息,新闻推荐中的新闻信息
- 用户信息:与人相关的信息,包括历史行为、人口属性、关系网络等,可以用来更可靠地 推测出人的兴趣点
- 场景信息/上下文信息:指具体推荐场景中的时间、地点、用户的状态等一系列环境信息
业务场景架构
推荐系统要处理的问题的定义:
- 对于用户U(user),在特定场景 C (context)下,针对海量的物品信息,构建一个函数
f(U,I,C),预测用户对特定候选物品 I (item)的喜好程度,再根据喜好程度对所有物品进行排序,生成推荐列表
技术设计架构
实际的推荐系统需要解决两类问题:
- 数据和信息相关的问题:即用户信息、物品信息、场景信息分别是什么?如何存储、更新和处理?
- 推荐系统算法和模型相关的问题:即推荐模型如何训练、如何预测、如何达到更好的推荐效果?
因此,推荐系统的技术架构也分为两个部分:
-
数据部分:数据离线批处理、实时流处理
- 负责“用户”“物品”“场景” 的信息收集与处理
- 原始数据加工后有3个主要出口:
- 生成推荐模型所需的样本数据,用于算法模型的训练和评估
- 生成推荐模型服务(model serving)所需的“特征”,用于推荐系统的线上推断
- 生成监控系统、商业智能系统所需的统计型数据
-
模型部分:
训练、评估、部署、线上推断
- 模型结构/模型服务过程:输入是所有候选物品集,输出是推荐列表
- 召回层:一般由高效的召回规则、算法或简单的模型组成,这让推荐系统能快速从海量的候选集中召回用户可能感兴趣的物品
- 深度学习中的 Embedding 技术
- 排序层(精排层):利用排序模型对初筛的候选集进行精排序。是推荐系统产生效果的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 321
321

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











