







作者:Tom Hardy
Date:2020-4-15
来源:CVPR2020文章汇总 | 点云处理、三维重建、姿态估计、SLAM、3D数据集等(12篇)
欢迎加入国内最大的3D视觉交流社区,1700+的领域从业者正在共同进步~
1、PVN3D: A Deep Point-wise 3D Keypoints Voting Network for 6DoF Pose Estimation
文章链接:https://arxiv.org/abs/1911.04231
代码链接:https://github.com/ethnhe/PVN3D
在这项工作中,论文提出了一种新的数据驱动下的方法,可以从单一的RGB-D图像中进行鲁棒的6自由度物体姿态估计。与往前直接回归姿态参数的方法不同,本文使用基于关键点的方法来处理这一具有挑战性的任务。具体地说,提出了一个深度Hough投票网络来检测物体的三维关键点,并使用最小二乘拟合的方式估计6D姿态参数。论文的方法是二维关键点方法的自然扩展,成功地用于基于RGB的六自由度估计。它可以充分利用具有额外深度信息的刚性物体的几何约束,便于网络学习和优化。通过大量的实验验证了三维关键点检测在6D姿态估计任务中的有效性。实验结果还表明,论文的方法在多个基准上都比最新的方法有很大的性能提升。


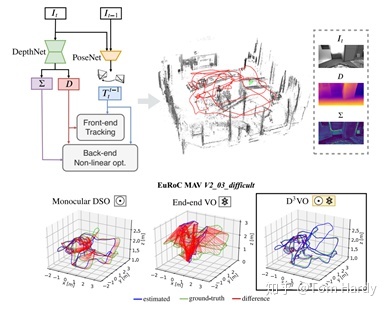
2、D3VO: Deep Depth, Deep Pose and Deep Uncertainty for Monocular Visual Odometry
论文链接:https://arxiv.org/abs/2003.01060
论文提出D3VO作为一个新的单目视觉里程测量框架,它利用深度、姿态和不确定性三个层次的深层网络。本文首先提出了一种新的无需外部监控的立体视频单目深度估计网络,它通过预测亮度变换参数将训练图像对对齐到相似的照明条件中。此外,还对输入图像上像素的光度不确定性进行了建模,提高了深度估计的精度,并为直接(无特征)视觉里程测量中的光度残差提供了学习的加权函数。评价结果表明,网络的性能优于现有的自监督深度估计网络。D3VO将预测的深度、姿态和不确定性紧密地结合到一种直接的视觉里程测量方法中,既提高了前端跟踪性能,又提高了后端非线性优化性能。论文在KITTI odometry基准和EuRoC MAV数据集上根据单目视觉里程计评估D3VO。结果表明,D3VO算法在很大程度上优于目前最先进的单目VO算法。它在仅使用一个摄像头下还获得了与KITTI上最先进的立体声/激光雷达里程表和EuRoC MAV上最先进的视觉惯性里程表相当的结果。

3、Total3DUnderstanding: Joint Layout, Object Pose and Mesh Reconstruction for Indoor Scenes from a Single Image
论文链接:http://arxiv.org/abs/2002.12212v1
室内场景的语义重建是指场景理解和物体重建。现有的工作要么解决这个问题的一部分,要么关注独立的对象。本文将理解与重建之间的鸿沟联系起来,提出了一种端到端的方法来从单个图像中联合重建房间布局、对象边界框和网格。本文的方法没有分别解决场景理解和对象重建问题,而是建立在整体场景上下文的基础上,提出了一个由粗到细的层次结构,该层
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4849
4849











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









