







一、解决的问题
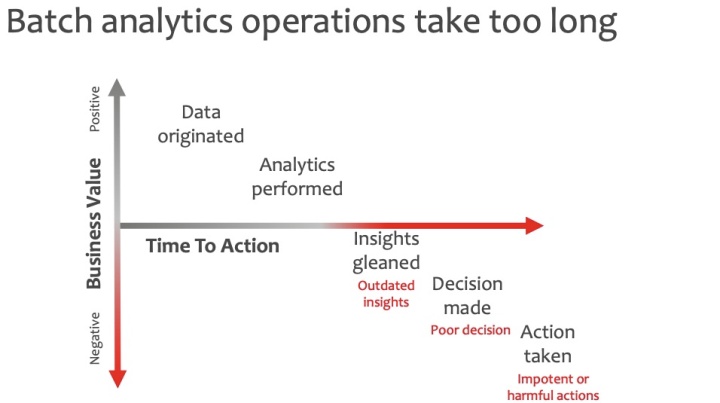
- 数据是实时产生的,对数据进行批处理所花费的成本太高了,数据产生的价值被低估
- 在高维数据下,如何能发现异常的维度?
If my time-series data with 30 features yields an unusually high anomaly score. How do I explain why this particular point in the time-series is unusual?
Ideally I'm looking for some way to visualize "feature importance" for a specific data point.
二、业内的解决方案
1、Numenta公司提出的HTM算法模型
- 背景:在大多数情况下,传感器流的数量很大,人类很少有机会,更不用说专家干预了。 因此,以无人监督的自动方式(例如,无需手动参数调整)操作通常是必要的。 底层系统通常是非平稳的,探测器必须不断学习和适应不断变化的统计数据,同时进行预测。 Hierarchical Temporal Memory (HTM)网络以有原则的方式在各种条件下稳健地检测异常。
- 生产系统应该是高效的,非常容忍噪声数据,不断使用数据统计的变化,并检测非常微妙的异常,同时最大限度地减少误报。该算法在实时金融异常检测中表现较好,切已经得到商业化部署。HTM与序列预测中的一些现有算法相比是有利的,特别是复杂的非马尔可夫序列,HTM不断学习系统,自动适应不断变化的统计数据,这是一种与流分析特别相关的属性。
- 该公司开发的Grok系统,目前服务在AWS,针对物理机器进行异常检测。The Leading AIOPS Platform For Intelligent Incident Prediction And Self-Healing Operations In IT Service Assurance
2、Amazon Kinesis
2.1 应用场景
- AWS Metering
- Amazon S3 events
- Amazon Cloud Watch Logs
- http://Amazon.com online catalog
- Amazon Go Video analysis
2.2 Kinesis - RRCF调用方式
-- creates a temporary stream.
CREATE OR REPLACE STREAM "TEMP_STREAM" (
"passengers" INTEGER,
"distance" DOUBLE,
"ANOMALY_SCORE" DOUBLE);
-- creates another stream for application output.
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" (
"passengers" INTEGER,
"distance" DOUBLE,
"ANOMALY_SCORE" DOUBLE);
-- Compute an anomaly score for each record in the input stream
-- using Random Cut Forest
CREATE OR REPLACE PUMP "STREAM_PUMP" AS
INSERT INTO "TEMP STREAM"
SELECT STREAM "passengers", "distance", ANOMALY_SCORE
FROM TABLE (RANDOM_CUT_FOREST (
CURSOR(SELECT STREAM * FROM "SOURCE_SQL_STREAM")))
-- Sort records b 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2373
2373











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









