






 提出一种新的卷积神经网络通道剪枝方法,通过训练性能预测网络并最大化子网络性能,有效解决损失度量不匹配问题。
提出一种新的卷积神经网络通道剪枝方法,通过训练性能预测网络并最大化子网络性能,有效解决损失度量不匹配问题。
【CVPR 2021】剪枝篇(一):Network Pruning via Performance Maximization
论文地址:
主要问题:
通道剪枝是一种比较通用而且效果较好的模型压缩方法,通过修剪权重和激活的通道来获得一个小的子网络
为了找到这样的子网络,许多现有的信道剪枝方法都使用分类损失作为指导
然而修剪过的子网络并不一定具有较高的精度和低分类损失,而这往往是由于损失度量不匹配造成的(作者在后面的实验中也证明了性能预测网络的梯度和分类损失有不同的方向)
因此在本文中,作者首先考虑了剪枝的损失度量不匹配问题,并提出了一种新的卷积神经网络的通道剪枝方法,用来直接最大化子网络的性能(即精度)
主要思路:
具体地说就是,我们训练一个独立的神经网络来预测子网络的性能,然后最大化网络的输出作为指导剪枝
并且在这个剪枝过程中,我们可以直接使用子网络和小批量精度作为样本来训练性能预测网络(是否想到了强化学习)
但是有效地训练这种性能预测网络往往是比较困难的,可能会面临灾难性遗忘和子网络分布不平衡的问题
为了解决这个问题,作者使用一个事件记忆模块来沿着剪枝轨迹收集样本
直接使用这些样本是有问题的,因为这些样本的准确性分布远不均匀,但是这个问题可以通过重新采样这些样本来解决(跟DQN里面经验池很像)
利用上述技术,性能预测网络在剪枝过程中进行了增量训练
在性能预测网络访问足够的样本并足够精确后,放到剪枝过程中,为通道剪枝提供额外的监督
由于性能预测网络的训练和剪枝工作同时进行,因此没有额外的成本
此外作者并没有放弃分类损失(通常是交叉熵损失),并且参考多目标学习的理念,在最终损失函数的定义中同时考虑了分类损失和性能最大化
这背后的基本原理是,分类损失和性能最大化都为修剪提供了有用但不同的信息,并且合并它们将会得到更好的结果
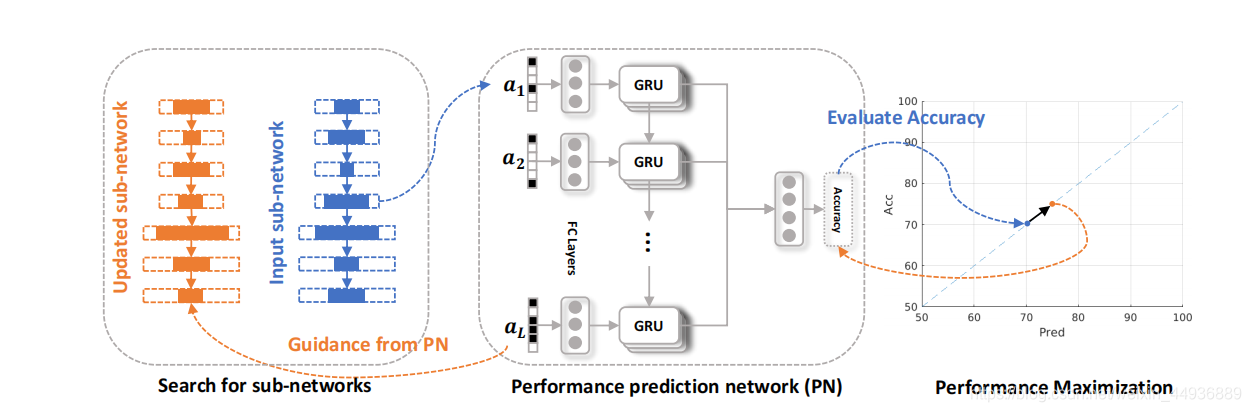
具体实现:
基本符号:
在CNN中,第 i i i 层的特征图可以表示为 F i ∈ R C i × W i × H i , i = 1 , . . . , L F_i\in R^{C_i×W_i×H_i},i=1,...,L Fi∈RCi×Wi×Hi,i=1,...,L,其中 C i C_i Ci 是通道数, L L L 是层数
用 1 ( ⋅ ) 1(\cdot) 1(⋅) 表示指标函数, ⊙ ⊙ ⊙ 表示点积
子网络生成:
正如我们前面所讨论的,直接采样子网络通常会产生琐碎的结果,特别是当剪枝率很高的时候
为了训练一个针对信道剪枝的性能预测网络,我们不需要遍历所有的子网络
假设原始模型的 FLOPs 为 T t o t a l T_{total} Ttotal,剪枝率为 p p p,我们对从 p T t o t a l pT_{total} pTtotal 到 T t o t a l T_{total} Ttotal 的子网络很感兴趣
我们首先丢弃 FLOPs 低于 p T t o t a l pT_{total} pTtotal 的子网络,因为它们不满足 FLOPs 约束
因此,我们更喜欢生成具有特定 FLOPs 的有意义的子网络作为性能预测网络的训练样本
我们开始先通过将原始模型修剪到目标 FLOPs p T t o t a l pT_{total} pTtotal 来生成这些子网络
为了实现这一点,我们首先引入了基本的可微剪枝算法
我们使用可微门来描述一个通道,对于第 i i i 层,门的定义为:
o i = 1 / ( 1 + e − ( w i + s ) / τ ) o_i=1/(1+e^{-(w_i+s)/\tau}) oi=1/(1+e−(wi+s)/τ)
其中 1 / ( 1 + e − ( w i + s ) / τ ) 1/(1+e^{-(w_i+s)/\tau}) 1/(1+e−(wi+s)/τ) 就是 sigmoid 函数, o i ∈ R C i o_i\in R^{C_i} oi∈RCi 并且 o i ∈ [ 0 , 1 ] o_i\in [0,1] oi∈[0,1],
w i ∈ R C i w_i\in R^{C_i} wi∈RCi 是门控单元可学习的参数, s s s 是从 Gumbel 分布的采样, s ∈ G u m b e l ( 0 , 1 ) s\in Gumbel(0,1) s∈Gumbel(0,1), τ \tau τ 是来控制锐度的超参数
这里的 o i o_i oi 是连续的,用来精确地生成子网络
然后我们进一步将其规范到 0 0 0 或 1 1 1:
a i = 1 o i > 1 2 ( o i ) a_i=\mathbb{1}_{o_i>\frac{1}{2}}(o_i) ai=1oi>21(oi)
其中 a i ∈ { 0 , 1 } C i a_i\in \{0,1\}^{C_i} ai∈{0,1}Ci
由于指示函数 1 ( ⋅ ) 1(\cdot) 1(⋅) 不可微,作者使用了直通式估计器(straight-through estimator)来计算梯度
上述两个等式中的可微分门则使用 Gumbel-Solftmax 算法来近似伯努利分布(虽然有近似伯努利分布,但作者发现它们的差异也并不显著)
为了实现最终的剪枝,我们将门控单元应用到特征图上:
F i ^ = a i ⊙ F i \hat{F_i}=a_i⊙F_i Fi^=ai⊙Fi
其中 a i a_i ai 被扩充到了 F i F_i Fi 的大小
这样整个剪纸过程的优化目标就可以写作:
min w L ( f ( x ; a , Θ , y ) + R ( T ( a ) , p T t o t a l ) ) \min_wL(f(x;a,\Theta,y)+R(T(a),pT_{total})) minwL(f(x;a,Θ,y)+R(T(a),pTtotal))
其中 w w w 包括了所有门控单元的可学习参数, a a a 是用于表示 CNN 模型结构的向量, a = c a t ( a 1 , . . . , a i , . . . , a L ) a=cat(a_1,...,a_i,...,a_L) a=cat(a1,...,ai,...,aL), T ( a ) T(a) T(a) 是由 a a a 定义的子网络的 FLOPs , x , y x,y x,y 分别是输入图片及其标签, f ( ⋅ ; a , Θ ) f(\cdot;a,\Theta) f(⋅;a,Θ) 是由 Θ \Theta Θ 参数化的 CNN 模型(其结构由 a a a 定义), R ( T ( a ) , p T t o t a l ) = l o g ( m a x ( T ( a ) , p T t o t a l ) / p T t o t a l ) R(T(a),pT_{total})=log(max(T(a),pT_{total})/pT_{total}) R(T(a),pTtotal)=log(max(T(a),pTtotal)/pTtotal) 是推动子网络到达目标 FLOPs 的正则化项
在上述等式的优化过程中会生成许多具有不同结构 a a a 的子网络
假设精度 q q q 是基于给定的小批量计算的,我们就可以得到一对代表一个子网络及其精度的样本 ( a , q ) (a,q) (a,q)
性能预测网络:
一旦我们获得了样本 ( a , q ) (a,q) (a,q),我们就可以训练一个神经网络来预测给定子网络结构的性能
我们首先定义了性能预测网络: q p r e d = P N ( a ) q_{pred}=PN(a) qpred=PN(a)
P N ( ⋅ ) PN(·) PN(⋅) 就是所提出的性能预测网络
然后使用 sigmoid 函数作为输出激活,因此 q p r e d q_{pred} qpred 在 0 0 0 到 1 1 1 的范围之间
性能预测网络由全连接层和 GRU 组成。简而言之,全连接的层将每个层的结构向量转换为一个紧凑的向量表示形式,并使用GRU来连接不同的层
作者使用GRU,是考虑到 a i − 1 a_{i−1} ai−1 和 a i a_i ai 有隐式的依赖性,因此 GRU 可能会使得性能预测网络有可能捕获子网络中复杂的交互
PN优化是一个回归问题,作者采用平均绝对误差损失(MAE)进行优化:
m i n w p L p = ∣ q − P N ( a ) ∣ min_{w_p}L_p=|q-PN(a)| minwpLp=∣q−PN(a)∣
其中 w p w_p wp 是性能预测网络的参数
事件记忆模块:
作者做的这项工作的早期版本直接利用当前迭代的子网络来训练性能预测网络
然而,作者发现它只会恶化剪枝过程,这是因为性能预测网络很难预测早期子网络,这种现象被称为灾难性遗忘(catastrophic forgetting)
为了克服这个问题,我们需要定期回放以前的子网络
因此作者进一步提出了一个事件记忆模块(Episodic Memory Module)来记忆早期的子网络
事件记忆定义为 E M = ( A , Q ) EM=(A,Q) EM=(A,Q),其中 A ∈ R m × K , Q ∈ R K A\in R^{m×K},Q\in R^K A∈Rm×K,Q∈RK, m m m 是向量 a a a 的长度, K K K 是当前 EM 的大小
当我们向 EM 添加一个子网络时, K K K 自动加 1 1 1,并且 K K K 小于预先定义的最大 EM 容量 K m a x K_{max} Kmax
但是正如前面提到的,小批量精度不是一个很好的估计精度;而另一方面,如果我们使用整个训练数据集来计算精度,计算成本就太过昂贵
为了利用效率和精度,我们每 c c c 次迭代收集子网络和相应的小批量精度的均值,以构建一个增强的子网络表示:
a ‾ = 1 a > 1 2 ( 1 c ∑ i = 1 c a i ) , q ‾ = 1 c ∑ i = 1 c q i \overline{a}=1_{a>\frac{1}{2}}(\frac{1}{c}\sum^c_{i=1}a_i),\overline{q}=\frac{1}{c}\sum^c_{i=1}q_i a=1a>21(c1∑i=1cai),q=c1∑i=1cqi
注意如果 c c c 太大,那么上面的参数是无效的,导致增强的表示是无用的
此外在收集子网络时,我们不比计算梯度
假设我们在 EM 模块中已经有 K K K 个子网,那么 EM 就可以通过以下方式更新:
P r − j = { A i = a ‾ , i = arg min i ∣ Q i − q ‾ ∣ i f K = K m a x , A K + 1 = a ‾ o t h e r w i s e P_{r-j}= \begin{cases} A_i=\overline{a},i=\argmin_i |Q_i-\overline{q}|& if K=K_{max},\\ A_{K+1}=\overline{a} & otherwise \end{cases} Pr−j=⎩⎨⎧Ai=a,i=iargmin∣Qi−q∣AK+1=aifK=Kmax,otherwise
也就是说当 K = K m a x K=K_{max} K=Kmax 时,我们将替换掉跟当前样本精度最相近的样本
事实上,在修剪过程中,大多数子网络在满足目标 FLOPS 后都具有相似的性能
因此,我们将使用 K m a x K_{max} Kmax 来鼓励子网络的多样性
精度分布不平衡:
在剪枝过程中,作者绘制了子网络精度的经验分布,发现精度集中在84左右:
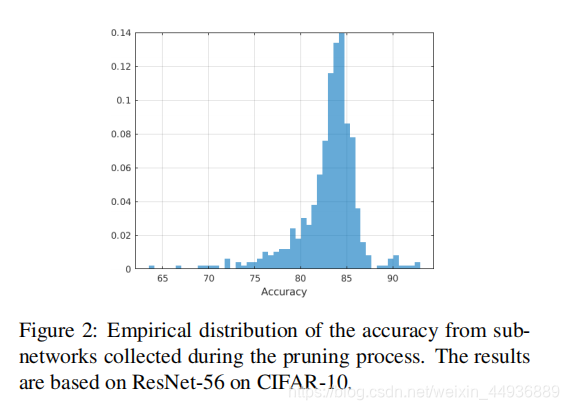
为了防止性能预测网络提供没有价值的解决方案,并使其收敛速度更快,作者提出可以根据子网络的准确性进行重新采样
即将所有的子网络按照 Q Q Q 的等差 1 N − 1 ( m a x ( Q ) − m i n ( Q ) ) \frac{1}{N-1}(max(Q)-min(Q)) N−11(max(Q)−min(Q)) 分为 N N N 个组
然后我们对每一组的子网络进行计数,并根据其计数的倒数对其进行重新抽样
这就相当于创建 N N N 个伪类并进行重新采样
性能最大化算法:
在拥有了一个相对靠谱的性能预测网络后,我们开始最大限度地提高搜索更好的子网络的性能
子网络的性能可以表示为 P N ( a ) PN(a) PN(a),因此我们可以最大化 P N ( a ) PN(a) PN(a) 作为精度的估值
max w P N ( a ) \max_wPN(a) maxwPN(a) 跟 min w 1 P N ( a ) \min_w\frac{1}{PN(a)} minwPN(a)1 是等价的,因此为了使得训练更稳定,我们优化目标就可以写作: min w l o g ( 1 P N ( a ) ) \min_wlog(\frac{1}{PN(a)}) minwlog(PN(a)1)
这样总的优化目标就可以表示为:
min w J ( w ) = L ( f ( x ; a , Θ ) , y ) + γ ( K , L P ) ⋅ l o g ( 1 P N ( a ) ) + λ R ( T ( a ) , p T t o t a l ) \begin{aligned} \min_wJ(w)=&L(f(x;a,\Theta),y)+\gamma(K,L_P)\cdot log(\frac{1}{PN(a)})\\ &+\lambda R(T(a),pT_{total}) \end{aligned} wminJ(w)=L(f(x;a,Θ),y)+γ(K,LP)⋅log(PN(a)1)+λR(T(a),pTtotal)
其中 γ ( K , L P ) \gamma(K,L_P) γ(K,LP) 是一个反映性能预测网络置信度的函数,被用来自动控制 l o g ( 1 P N ( a ) ) log(\frac{1}{PN(a)}) log(PN(a)1) 的量级, λ \lambda λ 被用来控制正则化的量级
γ ( K , L P ) \gamma(K,L_P) γ(K,LP) 定义为: γ ( K , L P ) = 1 K ≥ K m a x 4 ( K ) ⋅ ( 1 − L p ) 2 \gamma(K,L_P) =1_{K\geq\frac{K_{max}}{4}}(K)\cdot(1-L_p)^2 γ(K,LP)=1K≥4Kmax(K)⋅(1−Lp)2,范围为 [ 0 , 1 ] [0,1] [0,1]
通常来说更低的 L p L_p Lp 表示 P N ( ⋅ ) PN(\cdot) PN(⋅) 具有更高的置信度,但是 P N PN PN 的训练是一项增量学习任务,在 P N PN PN 能够访问足够的样本之前, L p L_p Lp 可能不是很可靠
虽然存在损失-度量不匹配的问题,但来自损失函数和性能最大化的信息仍有一些重叠
由于我们已经使用了分类损失,因此希望从性能最大化中获得独特的信息
为了实现这一点,我们使梯度彼此正交
假设 g L i = ∂ L ∂ w i g^i_L=\frac{\partial L}{\partial w_i} gLi=∂wi∂L 表示第 i i i 层的分类损失的梯度, g p i = ∂ l o g ( 1 P N ( a ) ) ∂ w i g^i_p=\frac{\partial log(\frac{1}{PN(a)})}{\partial w_i} gpi=∂wi∂log(PN(a)1) 是性能最大化损失的梯度
这两个项的修正梯度为:
g i = g L i + g ^ p i g^i=g^i_L+\hat{g}^i_p gi=gLi+g^pi
其中 g p i g_p^i gpi 可以分解成两部分: g p i = g ^ p i + g ‾ p i g_p^i=\hat{g}_p^i+\overline{g}_p^i gpi=g^pi+gpi,其中 g ^ p i ⊥ g L i \hat{g}_p^i\bot{g}_L^i g^pi⊥gLi 并且 g ‾ p i \overline{g}_p^i gpi 跟 g L i g^i_L gLi 方向相同
作者也给出了整个算法的伪代码:

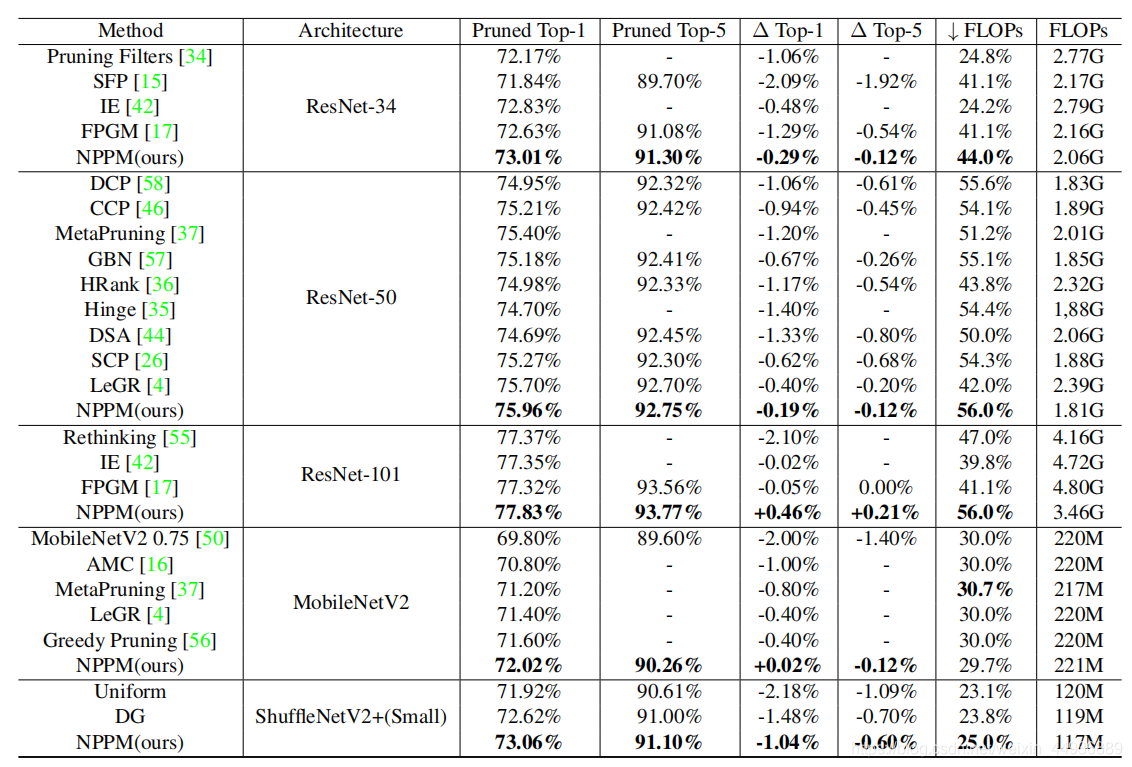
实验结果:


















 1408
1408

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











