







损失联合方式自监督:将CL的loss和其他loss混合,通过联合优化,使CL起到效果:CLEAR,DeCLUTER,SCCL。
非联合方法自监督:构造增强样本,fine-tune模型:Bert-CT,ConSERT,SimCSE。
1.CLEAR
背景:
作者认为,当前的预训练模型都是基于word-level的,没有基于sentence-level的目标,对sentence的效果不好。
方案:
word-level和sentence-level的loss联合。
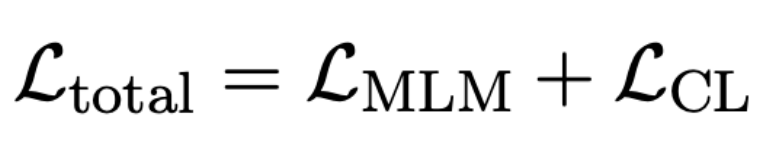
对比损失函数:

数据增强方法:

实验效果:


2.DeCLUTR
方案:
是一个不用训练数据的自监督的方法,是对pretrain过程的优化。

数据增强方法:
- 方案:选N个document组成一个batch,每个document取A个anchor,就有AN个,anchor取一个positive,也有AN个,共2AN个点。对于每一个点,除了和它组成正例的一对的2个,其他2AN-2都是负例
- 宗旨:认为距离anchor span越近的文本越相似,因此anchor span和它周边的span作为正例
- 用不同的Beta分布去限制anchor和positive span的长度,一般anchor比positive要长,而且anchor最长可以到512。
作者认为:
- 长anchor可以让embedding达到同时表征sentence级别和paragraph级别的作用
- 这样配置下游任务效果好 a)学到了global-to-local的信息 b)生成多个positive后可以获得diversity的信息
- 因为一个batch里有多个文档,不同文档的span组成的负例是easy负例,同文档的span组成的负例是hard负例。
实验效果:
- 对比学习过程中的ENCODER和MLM部分的Pretrained model是RoBerta和DistillRoBerta,pooling用的mean pooling。
- 评测数据集是SentEval,SentEval是一个用于评估句子表征的工具包,包含 17 个下游任务,其输入是句子表示,输出是预测结果
- 可以看到本文方案往往不是最优的那个,但是作者对比了 没用对比学习方法和用了对比学习方法(最后的Transformer-* VS DeCLUTER-*)的结果,说明了自己方案有效。


3.Supporting Clustering with Contrastive Learning
链接:
https://arxiv.org/abs/2103.12953(NAACL 2021)
背景:
在学习过程的开始阶段,不同的类别常常在表征空间中相互重叠,对如何实现不同类别之间的良好分离,带来了巨大的挑战。
方案:
利用对比学习,去做更好的分离。通过联合优化top-down聚类损失和bottom-up 实体级别的对比loss,来达到同时优化intra-cluster和inter-cluster的目的。

Instance-CL:
- 随机选M个样本组成一个batch,数据增强方法生成2M个样本,依然是从一个样本中生成的2个为一对正样本,和其他2M-2组成负样本
- 数据增强方法:
- 每个样本用InfoCNE去算loss, Instance-CL loss 为2M样本的平均值。
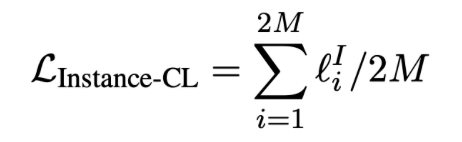
数据增强方法:
WordNet Augmenter:用wordNet中的同义词进行替换;
Contextual Augmenter:用pretrained model去找最合适的词去进行插入或替换;
Paraphrase via back translation:翻译成一种语言再翻译回来;
实验效果:

4.BERT-CT (ICLR2021)
背景:
从各种预训练模型的某层中取出的embedding,并不能很好表征句子,而且越接近目标的层,效果越不好。作者认为训练目标极为重要。
方案:
用两个超参不一样的模型来取sentence embedding,尽可能让正例对的点积更大,负例对的点积更小。
数据增强方法:
正例:同句子的不同embedding;
负例:随机选7个不同的句子;
实验效果:

2.SimCSE
论文: SimCSE: Simple Contrastive Learning of Sentence Embeddings
代码; simcse coding github
背景:
直接用BERT句向量做无监督语义相似度计算效果会很差,任意两个句子的BERT句向量的相似度都相当高,其中一个原因是向量分布的非线性和奇异性,正好,对比学习的目标之一就是学习到分布均匀的向量表示,因此我们可以借助对比学习间接达到规整表示空间的效果,这又回到了正样本构建的问题上来,而本文的创新点之一正是无监督条件下的正样本构建。
方案&数据增强方法:
本文作者提出可以通过随机采样dropout mask来生成xi+,回想一下,在标准的Transformer中,dropout mask被放置在全连接层和注意力求和操作上,其中z是随机生成的dropout mask,由于dropout mask是随机生成的,所以在训练阶段,将同一个样本分两次输入到同一个编码器中,我们会得到两个不同的表示向量z,z’,将z’作为正样本,则模型的训练目标为:

这种通过改变dropout mask生成正样本的方法可以看作是数据增强的最小形式,因为原样本和生成的正样本的语义是完全一致的(注意语义一致和语义相关的区别),只是生成的embedding不同而已。


引用自苏剑林simcse
经过调参,笔者发现中文任务上SimCSE的最优参数跟原论文中的不完全一致,具体区别如下:
1、原论文batch_size=512,这里是batch_size=64(实在跑不起这么壕的batch_size);
2、原论文的学习率是5e-5,这里是1e-5;
3、原论文的最优dropout比例是0.1,这里是0.3;
4、原论文的无监督SimCSE是在额外数据上训练的,这里直接随机选了1万条任务数据训练;
5、原文无监督训练的时候还带了个MLM任务,这里只有SimCSE训练。
最后一点再说明一下,原论文的无监督SimCSE是从维基百科上挑了100万个句子进行训练的,至于中文实验,为了实验上的方便以及对比上的公平,直接用任务数据训练(只用了句子,没有用标签,还是无监督的)。不过除了PAWSX之外,其他4个任务都不需要全部数据都拿来训练,经过测试,只需要随机选1万个训练样本训练一个epoch即可训练到最优效果(更多样本更少样本效果都变差)。
注意由于又有Dropout,训练时又是随机采样1万个样本,因此结果具有一定的随机性,重跑代码指标肯定会有波动,请读者知悉。一些结论 #
从实验结果可以看出,除了PAWSX这个“异类”外,SimCSE相比BERT-whitening确实有压倒性优势,有些任务还能好10个点以上,在BQ上SimCSE还比有监督训练过的SimBERT要好,而且像SimBERT这种已经经过监督训练的模型还能获得进一步的提升,这些都说明确实强大。(至于PAWSX为什么“异”,文章《无监督语义相似度哪家强?我们做了个比较全面的评测》已经做过简单分析。)
由于BERT-whiteing只是一个线性变换,所以笔者还实验了单靠SimCSE是否能复现这个线性变换的效果。具体来说,就是固定Encoder的权重,然后接一个不加激活函数的Dense层,然后以SimCSE为目标,只训练最后接的Dense层。结果发现这种情况下的SimCSE并不如BERT-whitening。那就意味着,SimCSE要有效必须要把Encoder微调才行,同时也说明BERT-whitening可能包含了SimCSE所没有东西的,也许两者以某种方式进行结合会取得更好的效果(构思中…)。
无监督训练时,除了用dropout生成语义相同的句子对,论文里还采用过:
Crop:随机删掉一段span
Word deletion:随机删除词
MLM:用BERT预训练任务之一,用一些随机token或【MASK】token代替原序列的某些token
最后发现dropout效果是最好
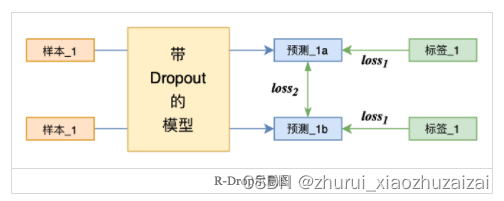
2.R-drop
链接:
https://github.com/dropreg/R-Drop
dropout 两次
















 1276
1276











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









