







1 混合精度
主要思想是使用较低精度的浮点数(如FP16)来表示神经网络中的权重和激活值,从而减少内存使用和计算开销,进而加速训练过程。
精度数值范围
- FP16:半精度浮点数,使用16位二进制数表示,其中1位表示符号位,5位表示指数位,10位表示尾数位,能够表示的数值范围为±215。
- FP32:单精度浮点数,使用32位二进制数表示,其中1位表示符号位,8位表示指数位,23位表示尾数位,能够表示的数值范围为±3.4×1038。
- FP64:双精度浮点数,使用64位二进制数表示,其中1位表示符号位,11位表示指数位,52位表示尾数位,能够表示的数值范围为±1.8×10308。
- INT8:8位整数,能够表示的数值范围为-128到127。
- INT4:4位整数,能够表示的数值范围为-8到7。
流程
混合精度训练的流程如下:
- 将FP32的权重转换为FP16格式,然后进行前向计算,得到FP32的损失(loss)。
- 使用FP16计算梯度。
- 将梯度转换为FP32格式,并将其更新到权重上。
由于FP16精度较低,可能会导致精度损失,因此在混合精度训练中需要进行一些技巧来保持模型的准确性。例如,可以使用梯度缩放(GradScaler)来控制梯度的大小,以避免梯度下降过快而影响模型的准确性。
FP32保存权重的原因
- 梯度的更新值太小,FP16直接变为了0
- FP16表示权重,梯度的计算结果可能变成0
- 用FP16保存权重会造成80%的精度损失
使用 Huggingface Transformers:在 TrainingArguments 里声明 fp16=True
https://huggingface.co/docs/transformers/perf_train_gpu_one#fp16-training
CUDA Automatic Mixed Precision examples
https://pytorch.org/docs/stable/notes/amp_examples.html
使用apex
apex.parallel.DistributedDataParallel 与apex.amp 已被以下两个API取代
torch.nn.parallel.DistributedDataParallel和torch.amp
model = Net().cuda()
optimizer = optim.SGD(model.parameters(), ...)
# 创建scaler
scaler = GradScaler()
for epoch in epochs:
for inputs, target in data:
optimizer.zero_grad()
with autocast(device_type='cuda', dtype=torch.float16): # 自动进行转化
output = model(inputs)
loss = loss_fn(output, target)
scaler.scale(loss).backward() # 应用于损失函数
scaler.step(optimizer) # 应用于优化函数
scaler.update()
2 量化
量化是一种通过减少数字表示的位数来减小模型存储量和计算量的方法。在深度学习中,通常使用32位浮点数来表示权重和激活值。但是,这种精度可能会导致计算和存储的开销非常高。因此,量化使用更短的整数表示权重和激活值,从而减少内存和计算开销。
2.1 动态量化和静态量化
在量化过程中,可以使用两种方法:动态量化和静态量化。
动态量化在运行时收集数据,并根据数据动态地量化模型。
静态量化在训练过程中对模型进行量化,并在推理时应用量化。
量化会导致模型准确度下降,因为更低的精度可能会导致舍入误差。因此,在量化期间,需要进行一些技巧来保持模型的准确程度,例如:对权重进行缩放或使用动态范围量化。
Huggingface 在这篇文章中用动图解释了 quantization 的实现:
https://huggingface.co/blog/hf-bitsandbytes-integration
借助 Huggingface PEFT,使用 int8 训练 opt-6.5B 的完整流程:
https://github.com/huggingface/peft/blob/main/examples/int8_training/Finetune_opt_bnb_peft.ipynb
动态量化不是训练后量化。动态量化是指在模型训练完成后,仅对模型的权重进行量化,而激活在推理过程中进行量化;而训练后量化则涉及在训练模型之后对模型的参数(包括权重和激活)进行量化12。
动态量化主要应用于有损数据压缩中,目的是减少数据量。它根据市场实时数据和不断调整的模型来进行交易决策的一种量化交易方式,通过快速的数据分析和交易执行来获取短期波动中的利润机会45。
训练后量化则是一种更广泛的量化技术,旨在减小模型大小并加快推理速度。通过使用8位整数(int8)指令,训练后量化可以显著减少模型的大小,并提高推理速度。这种方法适用于在资源受限的设备上部署大型语言模型,尽管它会引入一定的精度损失
2.2 量化推理
量化推理
使用load_in_8bit方法可以实现模型的量化。该方法可以将模型权重和激活值量化为8位整数,从而减少内存和计算开销。具体实现方法如下:
需要注意的是,使用load_in_8bit方法量化模型可能会导致模型准确度下降。因此,在量化模型之前,需要对模型进行测试,确保准确度可以接受。另外,不是所有的模型都可以被量化,只有支持动态量化的模型才可以使用该方法进行量化。
import torch
from transformers import AutoModel
# 加载模型
model = AutoModel.from_pretrained('bert-base-uncased',load_in_8bit=True)
2.3 量化训练
量化训练
在深度学习中,量化是一种通过减少数字表示的位数来减小模型存储量和计算量的方法。在使用混合精度训练时,可以将模型权重和梯度从FP32转换为FP16,以节省内存和加速训练。同样的思路,量化训练可以将激活值转换为更短的整数,从而减少内存和计算开销。
2.3.1 量化感知训练
PyTorch中提供了一些量化训练的工具和API,例如QAT(量化感知训练),使用动态范围量化等。其中,使用Adam8bit进行量化训练是一种方法。
- 量化感知训练(Quantization Aware Training, QAT):在模型训练过程中加入伪量化算子,利用伪量化算子将量化带来的精度损失计入训练误差,使得优化器能在训练过程中尽量减少量化误差,得到更高的模型精度。通过训练时统计输入输出的数据范围可以提升量化后模型的精度,适用于对模型精度要求较高的场景;其量化目标无缝地集成到模型的训练过程中。这种方法使LLM在训练过程中适应低精度表示,增强其处理由量化引起的精度损失的能力。这种适应旨在量化过程之后保持更高性能。
量化感知训练的具体流程如下:
- 初始化:设置权重和激活值的范围qminq_{min}qmin和qmaxq_{max}qmax的初始值;
- 构建模拟量化网络:在需要量化的权重和激活值后插入伪量化算子;
- 量化训练:重复执行以下步骤直到网络收敛,计算量化网络层的权重和激活值的范围qmin和qmax,并根据该范围将量化损失带入到前向推理和后向参数更新的过程中;
- 导出量化网络:获取qmin和qmax,并计算量化参数s和z;将量化参数代入量化公式中,转换网络中的权重为量化整数值;删除伪量化算子,在量化网络层前后分别插入量化和反量化算子。
大模型量化感知训练方法
- LLM-QAT(论文:LLM-QAT: Data-Free Quantization Aware Training for Large Language Models)
2.3.2 量化感知微调
- 量化感知微调(Quantization-Aware Fine-tuning,QAF):在微调过程中对LLM进行量化。主要目标是确保经过微调的LLM在量化为较低位宽后仍保持性能。通过将量化感知整合到微调中,以在模型压缩和保持性能之间取得平衡。
大模型量化感知微调方法
- PEQA(论文:Memory-efficient fine-tuning of compressed large language models via sub-4-bit integer quantization)
- QLORA(论文: QLORA: Efficient Finetuning of Quantized LLMs)
2.3.3 示例代码
下面是使用Adam8bit、trainer进行量化训练的示例代码:
import torch
from torch.optim import Adam
from torch.optim.lr_scheduler import LambdaLR
from torch.utils.data import DataLoader
from torchvision.transforms import Compose, ToTensor, Normalize
from torch.cuda.amp import GradScaler, autocast
from torch.quantization import QuantWrapper, Adam8Bit
# 初始化模型
model = Net().cuda()
# 初始化Adam优化器
optimizer = Adam(model.parameters(), lr=0.001)
# 初始化Adam8Bit
optimizer = Adam8Bit(optimizer)
# 初始化学习率调度器
lr_scheduler = LambdaLR(optimizer, lr_lambda=lambda epoch: 0.1 ** (epoch // 20))
# 初始化GradScaler
scaler = GradScaler()
# 开始训练
for epoch in range(10):
for i, (inputs, labels) in enumerate(train_loader):
optimizer.zero_grad()
with autocast():
outputs = model(inputs.cuda())
loss = torch.nn.functional.cross_entropy(outputs, labels.cuda())
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
lr_scheduler.step()
if i % 100 == 0:
print('Epoch:{}, Iteration:{}, Loss:{:.4f}'.format(epoch, i, loss.item()))
# 量化模型
quantized_model = QuantWrapper(model).to(torch.device('cuda'))
其中torch.quantization.default_qconfig是PyTorch中提供的一个默认的量化配置,包含了一些默认的量化参数。在一些简单的量化任务中,可以使用这个默认配置,而不需要自己手动指定每个参数的值。其中:
activation_8bit: 激活值的8位量化配置。默认值为torch.quantization.QConfig(activation=torch.quantization.default_observer.with_args(dtype=torch.qint8), weight=torch.quantization.default_per_channel_qconfig)。
weight_8bit: 权重的8位量化配置。默认值为torch.quantization.default_per_channel_qconfig.with_args(dtype=torch.qint8)。
这些默认值可以在使用**quantize()**函数时进行自定义,以满足特定的量化需求。
import torch
import transformers
# 加载已经训练好的BERT模型
model = transformers.BertForSequenceClassification.from_pretrained('bert-base-uncased')
# 定义训练参数
training_args = transformers.TrainingArguments(
output_dir='./results',
evaluation_strategy='steps',
eval_steps=1000,
save_total_limit=3,
learning_rate=1e-5,
num_train_epochs=3,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
warmup_steps=100,
weight_decay=0.01,
logging_dir='./logs',
logging_steps=1000,
load_best_model_at_end=True,
metric_for_best_model='eval_loss',
greater_is_better=False,
quantization_config={
'activations': torch.quantization.default_qconfig,
'weights': torch.quantization.default_qconfig
}
)
# 定义Trainer并进行量化训练
trainer = transformers.Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset
)
trainer.quantize()
trainer.train()
2.4 训练后量化
- 训练后量化(Post Training Quantization, PTQ):在LLM训练完成后对其参数进行量化,只需要少量校准数据,适用于追求高易用性和缺乏训练资源的场景。主要目标是减少LLM的存储和计算复杂性,而无需对LLM架构进行修改或进行重新训练。PTQ的主要优势在于其简单性和高效性。但PTQ可能会在量化过程中引入一定程度的精度损失。
大模型训练后量化方法
PTQ 的主要目标是减少 LLM 的存储和计算复杂性,而无需对 LLM 架构进行修改或重新训练。PTQ 的主要优势在于其简单和高效。然而,值得注意的是,PTQ可能会在量化过程中引入一定程度的精度损失。大模型的量化方法按照量化对象可分为权重量化和全量化(权重和激活量化)。
权重量化方法主要包括:
- LUT-GEMM(论文:nuqmm: Quantized matmul for efficient inference of large-scale generative language models)
- LLM.int8()(论文:LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale)
- ZeroQuant (论文:ZeroQuant: Efficient and Affordable Post-Training Quantization for Large-Scale Transformers)
- GPTQ (论文:GPTQ: ACCURATE POST-TRAINING QUANTIZATION FOR GENERATIVE PRE-TRAINED TRANSFORMERS)
- AWQ (论文:AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration)
- OWQ (论文:OWQ: Lessons learned from activation outliers for weight quantization in large language models)
- SpQR(论文:SpQR: A Sparse-Quantized Representation for Near-Lossless LLM Weight Compression)
全量化(权重和激活量化)方法主要包括:
- SmoothQuant(论文:SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models)
- RPTQ(论文:RPTQ: Reorder-based Post-training Quantization for Large Language Models)
- OliVe(论文:OliVe: Accelerating Large Language Models via Hardware-friendly Outlier-Victim Pair Quantization)
- Outlier Suppression+(论文:Outlier Suppression+: Accurate quantization of large language models by equivalent and optimal shifting and scaling)
- ZeroQuant-FP(论文:ZeroQuant-FP: A Leap Forward in LLMs Post-Training W4A8 Quantization Using Floating-Point Formats)
其中较为常用的量化方法主要有:
- GPTQ
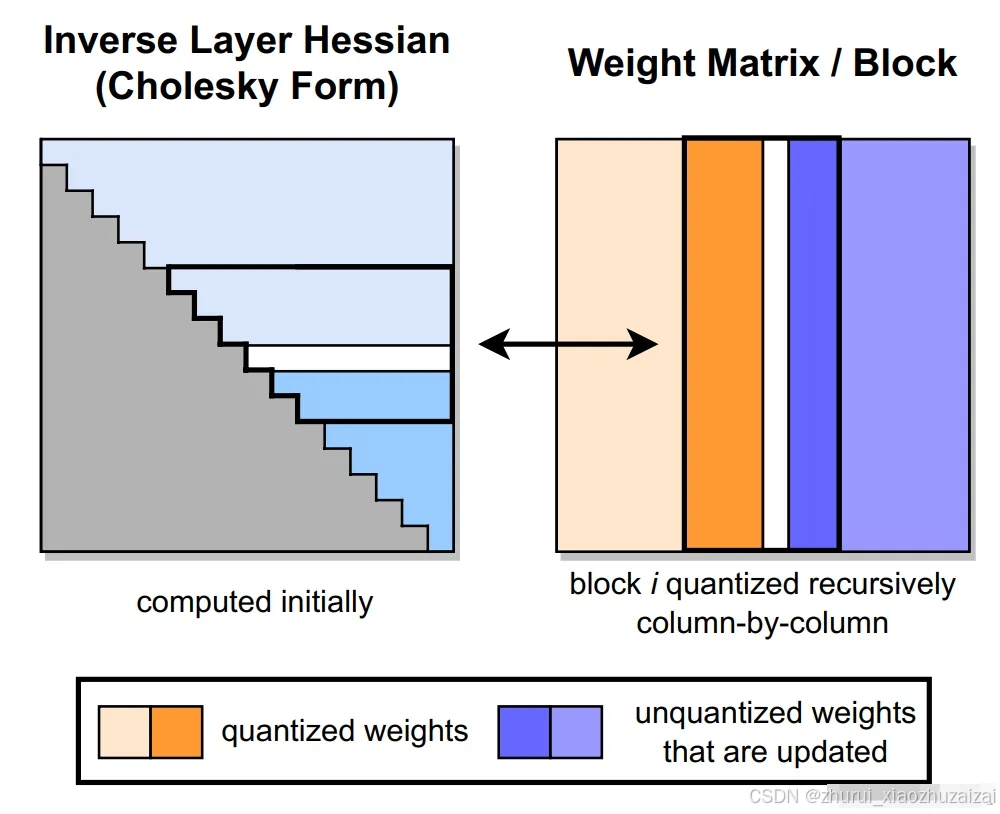
GPTQ(论文:GPTQ: ACCURATE POST-TRAINING QUANTIZATION FOR GENERATIVE PR E-TRAINED TRANSFORMERS)采用 int4/fp16 (W4A16) 的混合量化方案,其中模型权重被量化为 int4 数值类型,而激活值则保留在 float16,是一种仅权重量化方法。同 OBQ 一样,GPTQ也是从单层量化的角度考虑,希望找到一个量化过的权重,使得新的权重和老的权重之间输出的结果差别最小。
GPTQ 将权重分组(如:128列为一组)为多个子矩阵(block)。对某个 block 内的所有参数逐个量化,每个参数量化后,需要适当调整这个 block 内其他未量化的参数,以弥补量化造成的精度损失。
- AWQ
AWQ (论文:AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration)发现对于LLM的性能,权重并不是同等重要的,通过保留1%的显著权重可以大大减少量化误差。在此基础上,AWQ采用了激活感知方法,考虑与较大激活幅度对应的权重通道的重要性,这在处理重要特征时起着关键作用。该方法采用逐通道缩放技术来确定最佳的scale值,从而在量化所有权重的同时最小化量化误差。

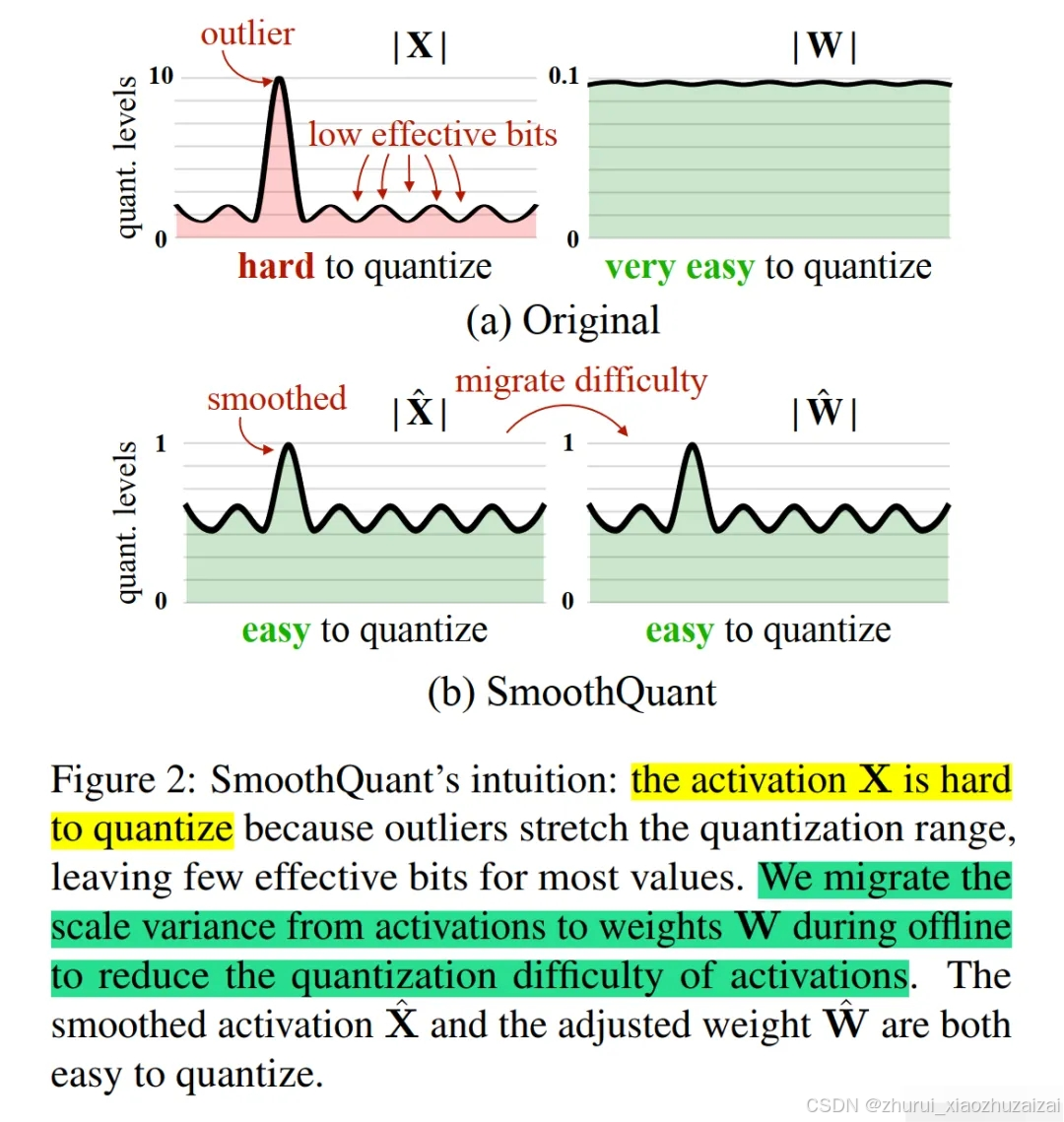
- SmoothQuant
SmoothQuant (论文:SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models)是一种同时确保准确率且推理高效的训练后量化 (PTQ) 方法,可实现 8 比特权重、8 比特激活 (W8A8) 量化。由于权重很容易量化,而激活则较难量化,因此,SmoothQuant 引入平滑因子s来平滑激活异常值,通过数学上等效的变换将量化难度从激活转移到权重上。
3 剪枝(Pruning)
剪枝通过识别和去除在训练过程中对模型性能影响较小的参数或连接,从而实现模型的精简和加速。
通常,模型剪枝可以分为两种类型:
- 结构化剪枝(Structured Pruning)
- 非结构化剪枝(Unstructured Pruning)
结构化剪枝和非结构化剪枝的主要区别在于剪枝目标和由此产生的网络结构。结构化剪枝根据特定规则删除连接或层结构,同时保留整体网络结构。
而非结构化剪枝会剪枝各个参数,从而产生不规则的稀疏结构。
模型剪枝的一般步骤包括:
- 训练初始模型:首先,需要训练一个初始的大模型,通常是为了达到足够的性能水平。
- 评估参数重要性:使用某种评估方法(如:权重的绝对值、梯度信息等)来确定模型中各个参数的重要性。
- 剪枝:根据评估结果,剪枝掉不重要的参数或连接,可以是结构化的或非结构化的。
- 修正和微调:进行剪枝后,需要进行一定的修正和微调,以确保模型的性能不会显著下降。
模型剪枝可以带来多方面的好处,包括减少模型的存储需求、加速推理速度、减少模型在边缘设备上的资源消耗等。然而,剪枝可能会带来一定的性能损失,因此需要在剪枝前后进行适当的评估和调整。
大模型的非结构化剪枝方法主要有:
- SparseGPT(论文:SparseGPT: Massive Language Models Can be Accurately Pruned in One-Shot)
- LoRAPrune(论文:LoRAPrune: Pruning Meets Low-Rank Parameter-Efficient Fine-Tuning)
大模型的结构化剪枝方法主要有:- LLM-Pruner(论文:LLM-Pruner: On the Structural Pruning of Large Language Models)
4 知识蒸馏(Knowledge Distillation)
知识蒸馏(KD),它通过将知识从复杂的模型(称为教师模型)转移到更简单的模型(称为学生模型)来实现这一点。
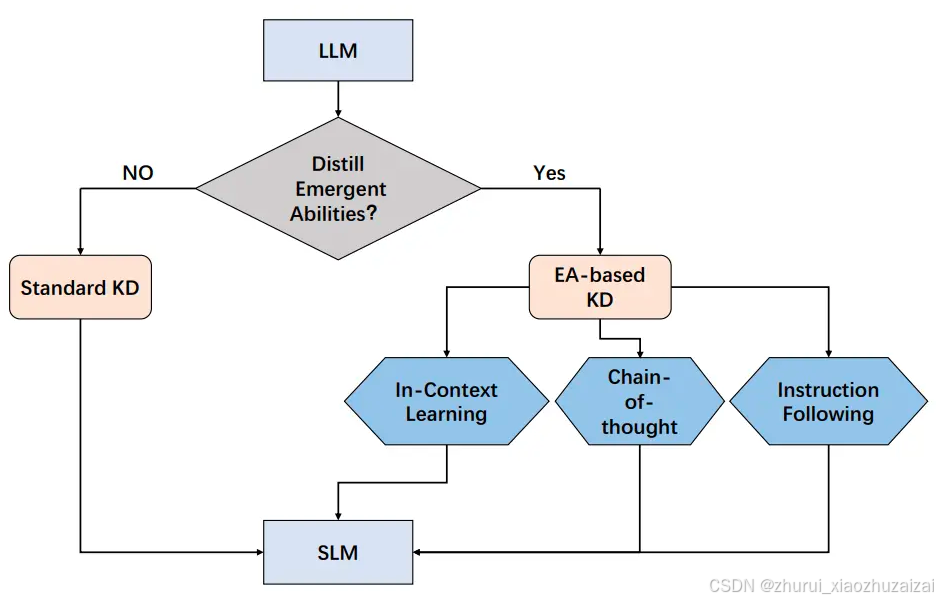
根据这些方法是否将LLM的涌现能力(EA)提炼成小语言模型(SLM)来对这些方法进行分类。 因此,我们将这些方法分为两个不同的类别:标准 KD 和基于 EA 的 KD。 为了直观地表示,下图提供了LLM知识蒸馏的简要分类。
标准知识蒸馏
- MINILLM (论文:Knowledge Distillation of Large Language Models)
- GKD(论文:GKD: Generalized Knowledge Distillation for Auto-regressive Sequence Models)
基于涌现能力的知识蒸馏
基于 EA 的 KD 不仅仅迁移 LLM 的常识,还包括蒸馏他们的涌现能力。
与 BERT(330M)和 GPT-2(1.5B)等较小模型相比,GPT-3(175B)和 PaLM(540B)等 LLM 展示了独特的行为。 这些LLM在处理复杂的任务时表现出令人惊讶的能力,称为“涌现能力”。 涌现能力包含三个方面,包括上下文学习 (ICL)、思维链 (CoT) 和指令遵循 (IF)。 如图所示,它提供了基于EA的知识蒸馏概念的简明表示。
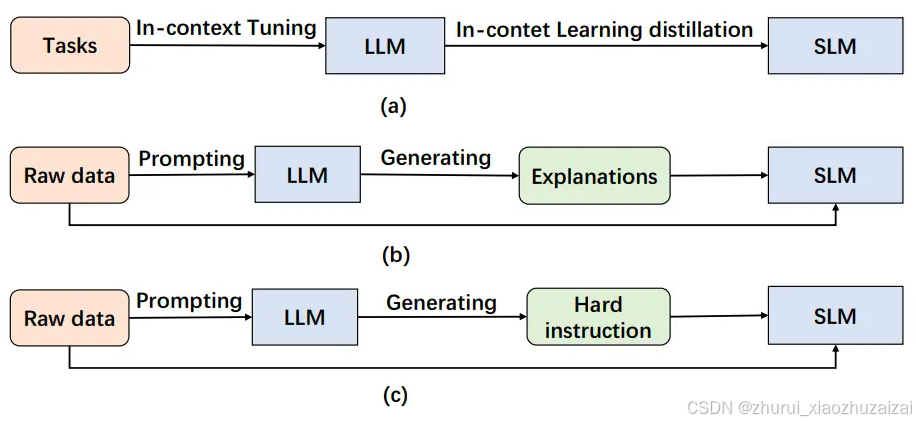
上下文学习蒸馏
- 元上下文调优 (Meta-ICT)
- 多任务上下文调优 (Multitask-ICT)
思维链蒸馏- MT-COT (论文:Explanations from Large Language Models Make Small Reasoners Better)
- Fine-tune CoT (论文:Large language models are reasoning teachers)
- SOCRATIC CoT(论文:Distilling Reasoning Capabilities into Smaller Language Models)
- DISCO(论文:DISCO: Distilling Counterfactuals with Large Language Models)
- SCOTT(论文:SCOTT: Self-Consistent Chain-of-Thought Distillation)
指令遵循蒸馏- Lion (论文:Lion: Adversarial Distillation of Closed-Source Large Language Model)
3 CPU offload
在深度学习训练过程中,GPU需要大量的数据进行计算,但是如果数据没有及时传输到GPU就会导致GPU处于等待状态,浪费GPU的计算能力。因此,CPU卸载技术就应运而生,通过让CPU负责将数据传输到GPU,可以让GPU专心计算,提高训练速度。
卸载分为多种类型,包括数据卸载、模型卸载、梯度卸载等。数据卸载是指将数据卸载到存储设备(例如硬盘)中,用的时候传输到GPU中,其他的类似。
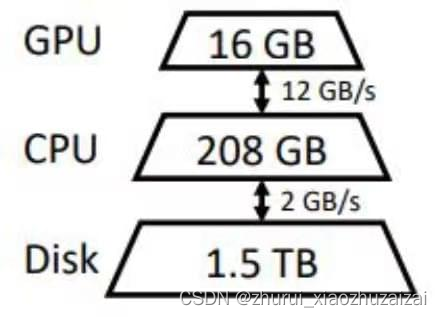
CPU
深度学习的训练需要用到GPU,因为它的计算速度比较快,但是如果GPU没有及时得到数据,就会处于等待状态,浪费了它的计算能力。CPU卸载技术就是让CPU来负责把数据传输到GPU,这样GPU就可以专心计算,提高训练速度。CPU卸载还可以帮助减少GPU内存的使用,降低训练过程中的内存压力。
nvme
使用 NVMe 固态硬盘扩展 GPU 是一种有效的 CPU 卸载技术。NVMe 固态硬盘具有高速的数据传输速度和低延迟,可以大大提高数据传输效率。此外,NVMe 固态硬盘还支持多通道和多队列,可以实现并行传输和处理,进一步提高数据传输速度。在使用 NVMe 固态硬盘时,可以通过在 CPU 和 GPU 之间使用高带宽 PCIe 总线,进一步优化数据传输速度,提高训练效率和速度。
FSDP
Fully Sharded Data Paralle(FSDP)和 DeepSpeed 类似,均通过 ZeRO 等分布优化算法,减少内存的占用量。其将模型参数,梯度和优化器状态分布至多个 GPU 上,而非像 DDP 一样,在每个 GPU 上保留完整副本。
Huggingface 这篇博文解释了 ZeRO 的大致实现方法:
https://huggingface.co/blog/zero-deepspeed-fairscale
借助 torch 实现 FSDP,只需要将 model 用 FSDPwarp 一下;同样,cpu_offload 也只需要一行代码:
https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/
在这个可以查看 FSDP 支持的模型:
https://pytorch.org/docs/stable/fsdp.html
在 Huggingface Transformers 中使用 Torch FSDP:
https://huggingface.co/docs/transformers/v4.27.2/en/main_classes/trainer#transformers.Trainin
根据某些 issue,shard_grad_op(只分布保存 optimizer states 和 gradients)模式可能比 fully_shard 更稳定:
https://github.com/tatsu-lab/stanford_alpaca/issues/32
4 Gradient Checkpointing
在 torch 中使用 - 把 model 用一个 customize 的 function 包装一下即可,详见:
Explore Gradient-Checkpointing in PyTorch
https://qywu.github.io/2019/05/22/explore-gradient-checkpointing.html
在 Huggingface Transformers 中使用:
https://huggingface.co/docs/transformers/v4.27.2/en/perf_train_gpu_one#gradient-checkpointing

















 1202
1202

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









