







SKIP-GRAM

输入层:中心词的one hot表示,
looktable查表【Vd 表,每个词作为中心词的表示】
得到中心词的embedding 表示[1300]
隐藏层: [W 大小为30010000],Vd 大小,是每个词作为背景词的表示
输出层:经过softmax,得到每个词的概率。
训练数据: ( input word, output word ) 单词对
input word和output word都是one-hot编码的向量。
最终模型的输出是一个概率分布。
CBOW

1、输入层:上下文单词的onehot形式;
2、隐藏层:onehot乘以第一个权重矩阵W(所有的权重矩阵相同,即共享权重矩阵),然后相加求平均作为隐藏层向量,该向量的大小与输入层的每一个样本大小相同;
3、输出层:将隐藏层向量乘以第二权重矩阵W‘,得到一个V维的向量,然后再通过激活函数(softmax)得到每一维词的概率分布,概率最大的位置所指示的单词为预测出的中间词;
4、一般使用使用的损失函数为交叉熵损失函数,采用梯度下降的方式来更新W和W’;这实际上是一个假任务,即我们需要的只是第一个权重矩阵W。得到第一个矩阵W之后,我们就能得到每个单词的词向量了。
I drink coffee everyday
1、第一个batch:I为中心词,drink coffee为上下文,即使用单词drink coffee来预测单词I,即输入为X_drink和X_coffee,输出为X_I,然后训练上述网络;
2、第二个batch:drink为中心词,I和 coffee everyday为上下文,即使用单词I和coffee everyday,即输入为X_I和X_coffee、X_everyday,输出为X_drink,然后训练上述网络;
3、第三个batch:coffee为中心词,I coffee 和 everyday为上下文,同理训练网络;
4、第四个batch:everyday为中心词,drink coffee为上下文,同理训练网络。
然后重复上述过程(迭代)3-5次(epoehs)左右即得到最后的结果。
具体的第三个batch的过程可见word2vec是如何得到词向量的?。得到的结果为[0.23,0.03,0.62,0.12],此时结果是以coffee为中心词的词向量,每个位置表示的是对应单词的概率,例如该词向量coffee的概率为0.62。
需要注意的是每个batch中使用的权重矩阵都是一模一样的
WORD2VECTOR的优化
将常见的单词组合(word pairs)或者词组作为单个“words”来处理。
对高频次单词进行抽样来减少训练样本的个数。
对优化目标采用“negative sampling”方法,这样每个训练样本的训练只会更新一小部分的模型权重,从而降低计算负担。
事实证明,对常用词抽样并且对优化目标采用“negative sampling”不仅降低了训练过程中的计算负担,还提高了训练的词向量的质量。
基于Hierarchical Softmax的模型
计算量瓶颈:
词表大
softmax计算大
每次更新更新参数多,百万数量级的权重矩阵和亿万数量级的训练样本。
参考huffman编码的思想:一般对于一个霍夫曼树的节点(根节点除外),可以约定左子树编码为0,右子树编码为1.
在word2vec中,约定左子树编码为1,右子树编码为0,同时约定左子树的权重不小于右子树的权重。
在霍夫曼树中,隐藏层到输出层的softmax映射不是一下子完成的,而是沿着霍夫曼树一步步完成的,因此这种softmax取名为"Hierarchical Softmax"。
二元逻辑回归的方法,即规定沿着左子树走,那么就是负类(霍夫曼树编码1),沿着右子树走,那么就是正类(霍夫曼树编码0)。判别正类和负类的方法是使用sigmoid函数,即:
基于层次softmax的CBOW和SKIP_GRAM梯度推导以及训练过程
Hierarchical Softmax的缺点与改进
如果我们的训练样本里的中心词𝑤是一个很生僻的词,那么就得在霍夫曼树中辛苦的向下走很久.
负采样就是结局这个问题的
Negative Sampling就是这么一种求解word2vec模型的方法,它摒弃了霍夫曼树,采用了Negative Sampling(负采样)的方法来求解,下面我们就来看看Negative Sampling的求解思路
负采样
Negative Sampling由于没有采用霍夫曼树,每次只是通过采样neg个不同的中心词做负例,就可以训练模型,因此整个过程要比Hierarchical Softmax简单。
不过有两个问题还需要弄明白:1)如果通过一个正例和neg个负例进行二元逻辑回归呢? 2) 如何进行负采样呢?
基于负采样的CBOW和SKIP_GRAM梯度推导以及训练过程
负采样怎么做的
所有的参数都在训练中调整的话,巨大计算量
负采样每次让一个训练样本仅仅更新一小部分的权重
现在只更新预测词以及neg个负例词的权重
随机选择一小部分的negative words(比如选5个negative words)来更新对应的权重。我们也会对我们的“positive” word进行权重更新(在我们上面的例子中,这个单词指的是”quick“)。
在论文中,作者指出指出对于小规模数据集,选择5-20个negative words会比较好,对于大规模数据集可以仅选择2-5个negative words。
如何选择negative words
“一元模型分布(unigram distribution)”来选择“negative words”。出现频次越高的单词越容易被选作negative words。
每个单词被赋予一个权重,即f(wi), 它代表着单词出现的频次。
公式中开3/4的根号完全是基于经验的,论文中提到这个公式的效果要比其它公式更加出色。你可以在google的搜索栏中输入“plot y = x^(3/4) and y = x”,然后看到这两幅图(如下图),仔细观察x在[0,1]区间内时y的取值,有一小段弧形,取值在y=x函数之上。
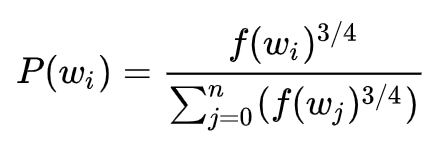

负采样的C语言实现非常的有趣。unigram table有一个包含了一亿个元素的数组,这个数组是由词汇表中每个单词的索引号填充的,并且这个数组中有重复,也就是说有些单词会出现多次。那么每个单词的索引在这个数组中出现的次数该如何决定呢,有公式P(wi)V,也就是说计算出的负采样概率1亿=单词在表中出现的次数。
有了这张表以后,每次去我们进行负采样时,只需要在0-1亿范围内生成一个随机数,然后选择表中索引号为这个随机数的那个单词作为我们的negative word即可。一个单词的负采样概率越大,那么它在这个表中出现的次数就越多,它被选中的概率就越大。
为什么需要做采样:
skip_gram 解决高频词训练样本太大的问题:
原始训练样本:
1.对于高频词。会产生大量的训练样本。
2.(“fox”, “the”) 这样的训练样本并不会给我们提供关于“fox”更多的语义信息,因为“the”在每个单词的上下文中几乎都会出现。
常用词出现概率很大,样本数量远远超过了我们学习“the”这个词向量所需的训练样本数。
Word2Vec通过“抽样”模式来解决这种高频词问题。它的基本思想如下:对于我们在训练原始文本中遇到的每一个单词,它们都有一定概率被我们从文本中删掉,而这个被删除的概率与单词的频率有关。
Z(wi)即单词wi在语料中出现频率


当Z(wi)<=0.0026时,P(wi)=1.0。当单词在语料中出现的频率小于0.0026时,它是100%被保留的,这意味着只有那些在语料中出现频率超过0.26%的单词才会被采样。
当Z(wi)<=0.00746时,P(wi)=0.5,意味着这一部分的单词有50%的概率被保留。
当Z(wi)<=1.0时,P(wi)=0.033,意味着这部分单词以3.3%的概率被保留。














 2543
2543











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









