







一 什么是扩散模型
1.1 现有生成模型
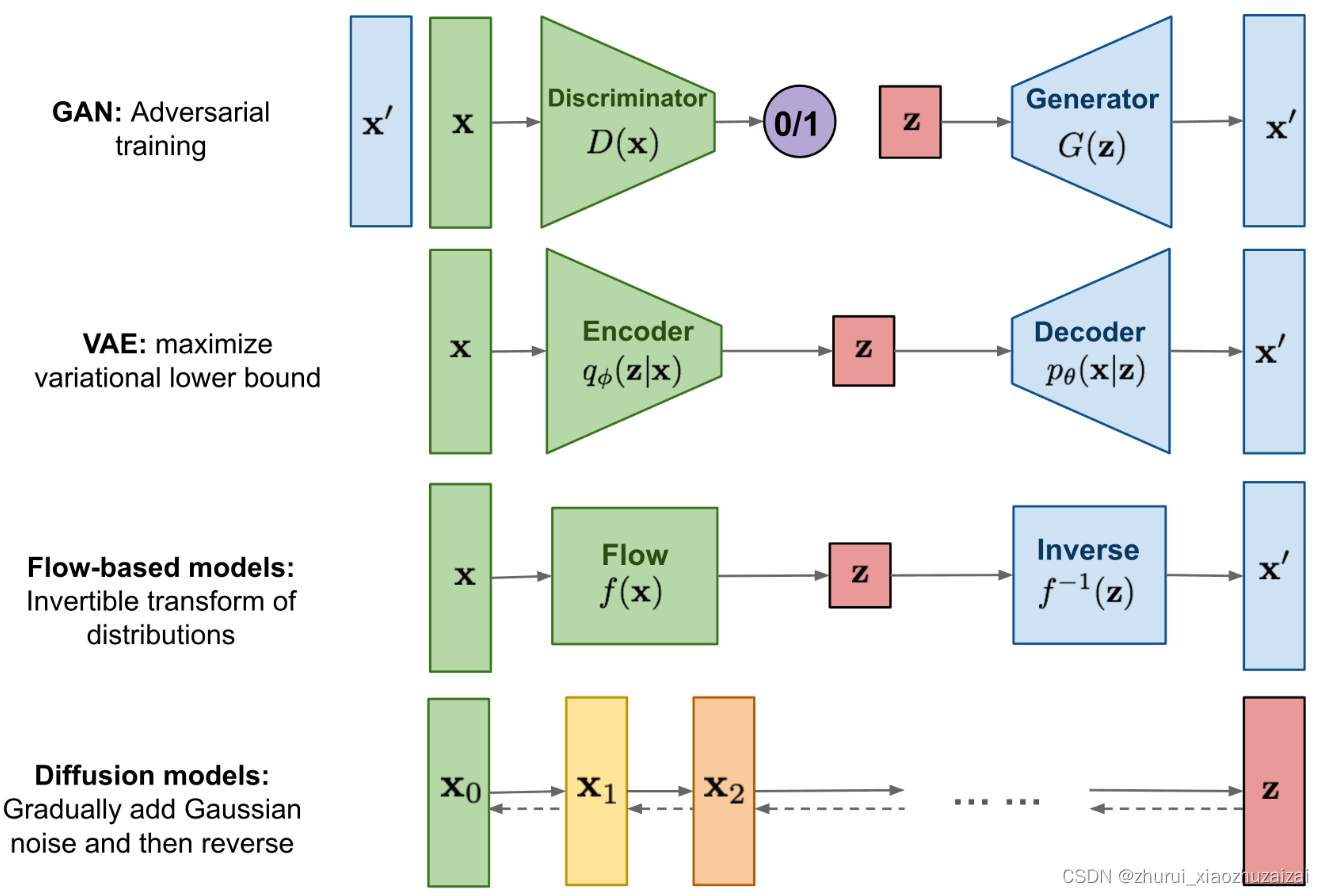
已经有大量的方法证明深度生成模型能够模拟人类的想象思维,生成人类难以分辨真伪的内容,主要方法如下:
1、GAN:用神经网络训练生成器和判别器
- GAN 的主要思想:
GAN 就是一个互搏的过程,要训练两个网络,一个是生成器,一个是判别器
生成器就是给定一个随机噪声,生成一些东西,我们希望其能生成一个比较逼真的图片,把生成的图片和真实的图片给到判别器,让判别器来看哪些是真图片和假图片,就是 0/1 的判断
通过两个网络互相学习,互相提高,最后能生成比较真实的图片- 缺点:
可解释性较差:GAN 不是概率模型,是通过网络完成的,是隐式的,所以不知道它到底学到了什么,不知道其遵循了什么分布
训练时不稳定:因为要同时训练两个网络,就有需要平衡的问题,训练不好的话容易模型坍塌
多样性较差- 优点:
GAN 的目标函数是用来以假乱真的,所以保真度和细节都非常好
2、AE、DAE、VAE、VQVAE:
Auto-Encoder (AE):
给定输入 x,经过编码器 encoder 就能得到特征,特征维度会变小,然后在使用解码器,得到一个图像,训练的目标函数是希望解码器的输出能尽可能的重建输入,也正是因为是自己重建自己,所以是自编码器Denoising Auto-Encoder (AE):先对原图输入进行扰乱,后续过程和 AE 一样,依然希望输入能够重建原始的未经过扰乱的输入,这个扰动很有用,会让训练出来的模型非常稳健,不容易过拟合。图片数据本来就是冗余的,所以添加一些扰动后,模型仍然能够学习到很好的特征。
AE 和 DAE 或者 MAE 其实都是为了学习中间那个 bottleneck 特征 z,学习好了后用于分类、检测等任务,并不是做生成的,其原因在于这里的 z 是专门用来重建的特征,并不是随机噪声,并不能用于采样来生成图像
所以就有了 VAE,也就是变分自编码器,VAE 和 AE 是很不同的,虽然结构看起来很像,但很重要的区别是,中间不再是学习一个 bottleneck 的特征,而是学习了一个分布,假设分布是高斯分布,可以用均值和方差来描述,就是从 encoder 得到特征后,加一些 FC 层,来预测均值和方差,得到后用公式采样一个 z 出来,VAE 就可以用来做生成了,因为在训练好后,可以扔掉 encoder,这里的 z 就是能随机抽样出的样本,然后就能生成图片了
VAE 这里生成的是一个分布,从贝叶斯角度来看,前面的过程是一个后验概率 p(z|x),就是给定 x 得到 z 的过程,学到的 z 就是一个先验分布,后面的过程是一个先验概率 p(x|z),就是给定 z 预测 x 的过程,其实就是最大似然,这里做的就是 maximize likelihood。
VAE 因为是学习的概率分布,是从分布中抽样的,生成的图片的多样性比 GAN 好的多,后面还有一些 VQVAE 和 DALLE 1 都是在 VAE 的基础上做的。
VAE 其实结构和扩散模型很像,且有较好的理论可解释性,但 Encoder 使用很大的步长来学习数据分布并进行加噪,Decoder 也使用很大的步长来去噪,导致学习的不够细致,很粗糙。
3.Flow-Based对概率密度函数的直接建模,这使得它们在数据生成和推断方面具有优势,并且在潜在空间中的操作更加直观。但是,它们可能在处理复杂数据分布时受限,因为需要设计适合数据分布的逆变换
- 与其他生成模型原理区别:
Flow-based模型:这种模型通过学习数据的概率密度函数来进行生成。它们学习了数据的分布,并利用这种分布来生成新的样本。
VAE:变分自编码器利用潜在变量的分布来建模数据。它通过编码器将输入数据映射到潜在空间中,并通过解码器从潜在空间中的采样重建输入数据。
GAN:生成对抗网络通过生成器生成假样本,同时使用鉴别器来区分真实和假的样本。生成器和鉴别器相互竞争,以提高生成器生成逼真样本的能力。
1.2 扩散模型
前向扩散:在输入 x0 上逐步加噪声,一共加 T 次,最终变成一个真正的噪声,各向同性正态分布
逆向去噪:从最终的 xT 逐步恢复原图的过程,使用的是共享参数的 U-Net 结构
- 扩散模型发展历程:
DDPM → improved DDPM → Diffusion beats GAN → GLIDE → DALLE2 → Imagen
- 扩散模型的理论来源
扩散模型背后的直觉来源于物理学:
在物理学中,气体分子从高浓度区域扩散到低浓度区域
这与由于噪声的干扰而导致的信息丢失是相似的
通过引入噪声,然后尝试去噪来生成图像,模型每次在给定一些噪声输入的情况下学习生成新图像。
扩散模型(Diffusion Model)起源于非均衡热动力学(non-equilibrium thermodynamics),是一类基于概率似然(likelihood)的生成模型。
- 扩散模型的使用场景
扩散模型可以用到哪些任务上:
计算机视觉,语言模型,声音模型,AI for science- 扩散模型的应用场景:
图文生成,视频生成,分子结构生成,AI 绘画,AI 制药,…
- 扩散模型的基本结构
扩散模型的工作原理:
学习由于噪声引起的信息衰减,然后使用学习到的模式来生成图像
- 扩散模型的结构:
扩散模型定义了一个扩散步骤的马尔可夫链,慢慢地向数据中添加随机噪声,也就是熵增的过程,然后学习逆向扩散过程,从噪声中构建所需的数据样本
前向扩散过程 q:为输入图像 x0 引入一系列的随机噪声,也就是对样本点分 T 步添加高斯噪声,随着噪声的引入, x0 最终会失去区分特性
逆向恢复过程 p:从高斯先验出发,从有大量随机噪声的图中学习恢复原图
- 扩散模型相比 GAN 或 VAE 的缺点:
速度慢:扩散模型是基于马尔科夫过程来实现的,在训练和推理的时候都需要很多步骤
- 当前对扩散模型的研究主要围绕三种主流的实现:
去噪扩散概率模型(Denoising Diffusion Probabilistic Models / DDPMs)
基于分数的生成模型(Score-based Generative Models / SGMs)
随机微分方程(Stochastic Differential Equations / Score SDEs)- 随机微分方程(SDEs)
SDEs是描述扩散模型中噪声添加过程的数学工具。就像是一个详细的步骤图,展示了噪声是如何随着时间逐步添加到数据中的。这个框架非常重要,因为它赋予了扩散模型处理不同类型数据和应用的灵活性,使它们能够为各种生成任务量身定制:- 分数生成模型(SGMs)
该部分是模型学习理解和逆转噪声添加过程的地方。这个过程就像是让模型学会了一种特殊的逆向思维。举个简单的例子,如果一张图片被加了一堆乱七八糟的噪声,最后变得啥也看不清了,那我们怎么把它变回原来的样子呢?分数生成建模就是教模型怎么从这些乱七八糟的噪声中,一步步地把清晰的图像找回来。这就像是在一堆混乱中找到秩序,最后从一堆噪音里变出一张清晰的图片。这对于我们从一堆随机的噪声中创造出看起来真实的图像来说,是非常关键的。- 去噪扩散概率模型(DDPMs)
去噪扩散概率模型(DDPMs)就像是数据的清洁专家。在训练的时候,它们就像是在观察一个过程:数据是怎么一步步被噪声弄脏的,然后它们学会了怎么一步步地把这些噪声清理掉,让数据恢复到原来的样子。这个过程就像是在玩一个猜谜游戏,用概率来猜在噪声出现之前,数据本来长什么样。这样的方法让模型不仅能把噪声去掉,还能让数据看起来和原来几乎一模一样,这对于那些需要精确数据重建的任务来说特别重要。
- 当前最流行的扩散模型包括:

二 扩散模型介绍
2.1 符号和定义
1、State:状态
State 是能够描述整个扩散模型过程的一系列数据:
初始状态:starting state x0
prior state:离散时为 xT ,连续时为 x 1
中间状态:intermediate state xt
2、Process 和 Transition Kernel
Forward/Diffusion 过程 F:将初始状态转换到有噪声的状态
Reverse/Denoised 过程 R:和前向过程方向相反,从有噪声的图像中逐步复原原图的过程
Transition Kernel:在上面的两个过程中,每两个 state 的变换都是通过 transition kernel 来实现的,
Ft 和 Rt 分别是 t时刻从状态 t-1 转换成状态 xt 的前向 transition kernel 和逆向 transition kernel
σt 是噪声尺度
最常用的 transition kernel 是 Markov kernel,因为其具有较好的任意性和可控性
2.2 前向过程
推导过程来自:https://zhuanlan.zhihu.com/p/624617160
加噪过程:不断地往输入数据中加入噪声,直到其就变成纯高斯噪声,每个时刻都要给图像叠加一部分高斯噪声。其中后一时刻是前一时刻增加噪声得到的。

重参数化的技巧:简单来说就是,如果想要从一个任意的均值μ方差σ^2的高斯分布中采样。可以首先从一个标准高斯分布(均值0,方差1)中进行采样得到ε,然后μ + σ·ε就等价于从任意高斯分布中进行采样的结果。
推导过程:
根据DDPM的到公式
根据重参数化,得到xt和xt-1的关系
根据推导,得出xt和x0的关系

2.3 后向过程
去噪过程:由一个纯高斯噪声出发,逐步地去除噪声,得到一个满足训练数据分布的图片。
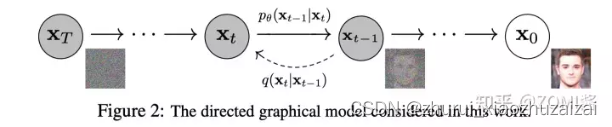
推导过程:
第一步:根据P(A|B)=P(AB)/P(B)
第二步:巧妙的将后向过程全部变成了前向过程
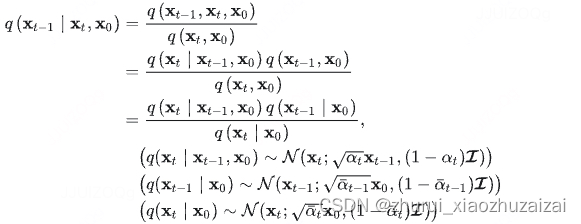


2.4 训练与采样
训练:
首先每个迭代就是从数据集中取真实图像x0,并从均匀分布中采样一个时间步t,然后从标准高斯分布中采样得到噪声ε,并根据公式计算得到xt。接着将xt和t输入到模型让其输出去拟合预测噪声ε,并通过梯度下降更新模型,一直循环直到模型收敛。而采用的深度学习模型是类似UNet的结构
采样(生成):
模型训练好之后,在真实的推理阶段就必须从时间步T开始往前逐步生成图片,算法描述如下:
一开始先生成一个从标准高斯分布生成噪声,
然后每个时间步t,将上一步生成的图片xt输入模型模型预测出噪声。
接着从标准高斯分布中采样一个噪声,根据重参数化技巧,后验概率的均值和方差公式,计算得到xt-1,直到时间步1为止。
训练损失





















 6534
6534

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









