







GitHub - Xianchao-Wu/peft: PEFT: State-of-the-art Parameter-Efficient Fine-Tuning.
PEFT
LoRA: LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
Prefix Tuning: Prefix-Tuning: Optimizing Continuous Prompts for Generation,
P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks
P-Tuning: GPT Understands, Too
Prompt Tuning: The Power of Scale for Parameter-Efficient Prompt Tuning
AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning
LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention
mapping.py
#peft模型的类型
from .peft_model import (
PeftModel,
PeftModelForCausalLM,
PeftModelForQuestionAnswering,
PeftModelForSeq2SeqLM,
PeftModelForSequenceClassification,
PeftModelForTokenClassification,
)
#peft支持的几种tuning
from .tuners import (
AdaLoraConfig,
AdaptionPromptConfig,
LoraConfig,
PrefixTuningConfig,
PromptEncoderConfig,
PromptTuningConfig,
)
from .utils import PromptLearningConfig
MODEL_TYPE_TO_PEFT_MODEL_MAPPING = {
"SEQ_CLS": PeftModelForSequenceClassification,
"SEQ_2_SEQ_LM": PeftModelForSeq2SeqLM,
"CAUSAL_LM": PeftModelForCausalLM,
"TOKEN_CLS": PeftModelForTokenClassification,
"QUESTION_ANS": PeftModelForQuestionAnswering,
}
PEFT_TYPE_TO_CONFIG_MAPPING = {
"ADAPTION_PROMPT": AdaptionPromptConfig,
"PROMPT_TUNING": PromptTuningConfig,
"PREFIX_TUNING": PrefixTuningConfig,
"P_TUNING": PromptEncoderConfig,
"LORA": LoraConfig,
"ADALORA": AdaLoraConfig,
}
1 prefix tuning
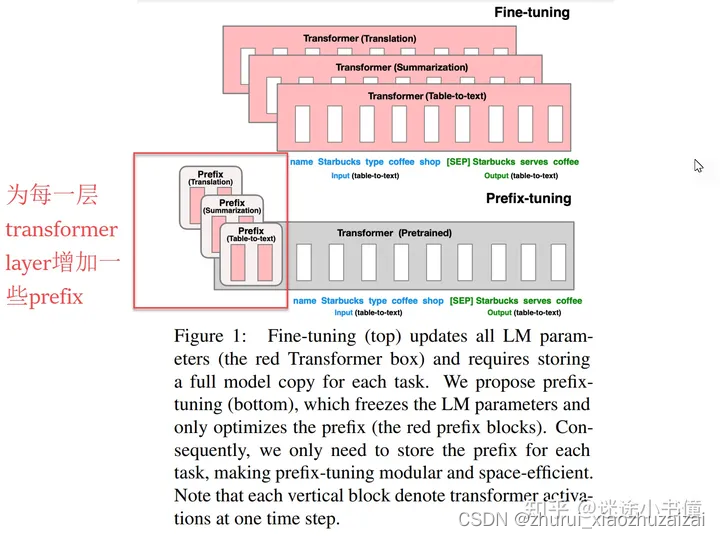
构造出num_virtual_tokens个虚拟tokens,并不会被追加到prompt里面!【加的话,就变成另外一个方法prompt-tuning了;我们现在讨论的是prefix-tuning】
虚拟tokens embedding包含参数:num_virtual_tokens, num_layers * 2 * token_dim个
使用时:调用模型原有的generate()方法。这些参数通过past_key_values参数传递进去.把30个虚拟tokens映射到(24, 2, 1024)这样的张量,为的是为transformer的每个layer,都构造出来key, value;作为后续prompt的memory
BloomAttention的key和value,在BloomAttention的每一层,作为past memory,供当前的prompt (=query)来使用。
peft/peft_model.py
其一,拿到prompt_encoder [batch_size, num_virtual_tokens, dim];
past_key_values = prompt_encoder(prompt_tokens)
其二,对num_virtual_tokens个virtual tokens,基于prompt_encoder里面的embedding,来构造出来拆分出来,num_layers层layer所需要的key和value:
past_key_values = past_key_values.view(
batch_size,
peft_config.num_virtual_tokens,
peft_config.num_layers * 2,
peft_config.num_attention_heads,
peft_config.token_dim // peft_config.num_attention_heads,
)
if peft_config.num_transformer_submodules == 2:
past_key_values = torch.cat([past_key_values, past_key_values], dim=2)
past_key_values = past_key_values.permute([2, 0, 3, 1, 4]).split(
peft_config.num_transformer_submodules * 2
)
past_key.shape = [128, 64, 30],其中128=batch size(训练阶段),64 = 维度,30=虚拟token的个数。
past_value.shape = [128, 30, 64],每个参数的含义和key一样,不过30和64的顺序是颠倒的。
然后,306行,是把past_key和当前的key_layer串到一起:本来key_layer.shape = [128, 64, 64],即prompt长度为64,和past_key组合之后,得到:[128, 64, 94=30+64],是为新的key。
同理,307行,是把past_value和当前的value_layer串到一起:本来value_layer.shape = [128, 64, 64],即prompt长度为64,和past_value组合之后,得到:[128, 94=30+64, 64],是为新的value。
如此,就可以让query = [128, 64, 64]来访问这个新增加了30个虚拟节点的key和value了。
2 prompt tuning,
则是在prompt的前面直接追加一定数量的virtual tokens,然后专门对这些新增加的虚拟tokens进行微调。模型的其他参数保持不变。
构造一定数量的虚拟tokens(标记,8个);
可学习的网络为一个(8, 1024)的word embedding;
在做训练和测试的时候,8个虚拟tokens被追加到当前的prompt中。长度被增加的prompt和label,按照往常的方法,被用于训练和推理。














 1450
1450











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









