







论文题目:
Dynamic R-CNN: Towards High Quality Object Detection via Dynamic Training
论文地址:
https://arxiv.org/pdf/2004.06002.pdf
论文代码:
https://github.com/hkzhang95/DynamicRCNN

本文将分享来自中科院计算所的硕士生张弘楷等人在ECCV的工作。他们提出了一种新的高质量目标检测算法——Dynamic R-CNN,以此来更好地利用训练样本并推动检测器适应更多高质量样本。
中科院计算所和图森未来的研究团队发现两阶段检测器中存在着固定的网络设定和动态的网络训练之间的不一致性问题。随着训练进行,检测器第二阶段的输入样本分布在不断改变,而固定的训练设定并不利于训练高质量检测器。所以研究人员提出了 Dynamic R-CNN,根据训练过程中候选窗口的统计量自动的调整标签设计策略以及回归损失函数的形状,以推动检测器适应更多高质量样本。COCO数据集的实验表明所提出的方法能够在不增加额外计算复杂度的前提下提升1.9 AP和5.5 AP90.
一、导读
目标检测是计算机视觉领域中一个经典而富有挑战性的问题,它的目的是定位到图像中所有物体的位置,并且决定它们的语义类别。
现代目标检测器的主要框架可以分为 One-stage 检测器和 Two-stage 检测器,它们分别在速度和精度上有各自的优势。经过近些年的发展,目标检测系统在很多方面 (例如多尺度、物体表示、一致性问题等) 都有了显著的改进。但是目前检测系统整体的训练过程还远不完美,尤其是针对高质量目标检测器而言 (高质量一般指在高 IoU 下的结果) 。
针对上述问题,我们,
1. 指出了两阶段检测器中存在着固定的网络设定和动态的网络训练之间的不一致性问题:随着训练的进行,第二阶段 R-CNN 的输入样本分布是一直在改变的,而训练相关设定一般是固定的,这种不一致性导致高质量样本在训练过程中无法得到很好的利用,所以不利于训练高质量目标检测系统。
2. 提出了 Dynamic R-CNN,根据训练过程中候选窗口的统计量来自动调整标签设计策略以及回归损失函数的形状,以此来更好地利用训练样本并推动检测器适应更多高质量样本。
二、问题分析
1. Two-stage 检测器的不一致性问题
为了更好的理解这种固定的网络设定和动态的网络训练之间的不一致性问题,我们先回忆一下标准的 Two-stage 检测器结构,这里我们以代表性的 Faster R-CNN [1] 为例进行分析。
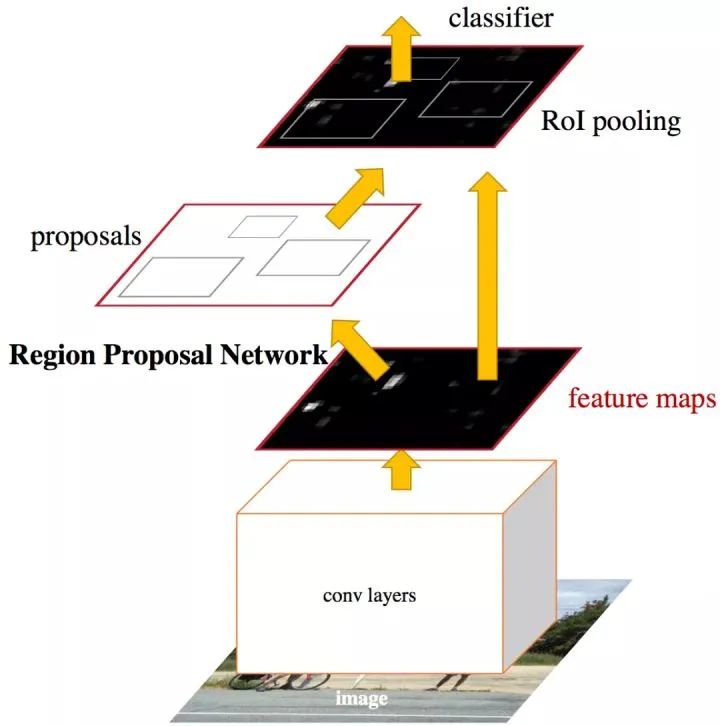
如上图所示,Faster R-CNN 使用了 coarse-to-fine 结构,在第一阶段将 anchors 精修得到 proposals,然后在第二阶段精修 proposals 得到最终的检测结果。
鉴于第二阶段 R-CNN 的输入是 proposals,随着训练的进行 RPN 部分的参数会不断地得到优化,所以我们猜测 proposals 的分布也应该会随之不断改变。
所以我们可视化了训练过程中的一些统计量,如下图所示。我们可以看出无论采用什么 IoU 阈值,正样本的数量都在随着训练进行而增多,同时回归标签的标准差也在减小,这说明正样本的质量其实在不断提升,同时也说明训练过程其实是动态的。
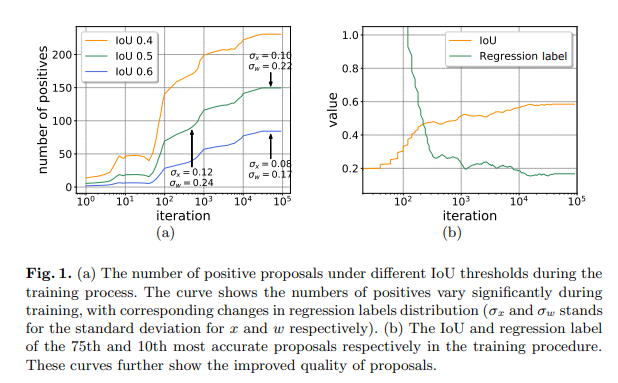
但是目前检测框架大多采用固定的网络设定,这并不利于高质量检测器的训练,弊端主要体现在分类和回归两个方面。
2. Proposal Classification
在目标检测任务中,如何决定正负样本一直是一个有趣的问题。如下图所示,和标注框完全一致的 proposals 应该是正样本,而完全没有 IoU 的应该是负样本,但是中间样本的标签就很难决定。
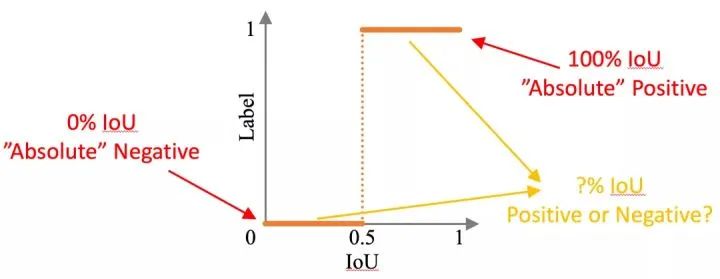
两阶段检测器的分类器一般会使用固定的 IoU 阈值 (例如0.5) 来区分正负样本,但是设定这个阈值是很困难的,因为分类器的学习目标是区分正负样本,所以设定不同阈值会导致分类器有不同的质量 (Cascade R-CNN[2] 将训练的 IoU 定义为质量)。
那么如果目标是高质量检测器,就需要提高 IoU 阈值。但是直接提高 IoU 阈值会造成正样本缺乏,从而导致过拟合[2],所以 Cascade R-CNN 使用了多个 stage 来不断提升 proposal 的质量。这样虽然有效,但是非常耗时,所以有没有更好的办法?
我们前面提到正样本的质量会随着训练进行而不断提升,那么完全可以采用一种渐进的训练方法:
训练初期,网络无法产生足够高质量的 proposals,那么我们采用较低的 IoU 阈值来适应这些不完美的样本;
训练后期,proposals 的质量得到了提升,我们逐渐有了足够的高质量样本,就可以采用较高的 IoU 阈值来训练高质量分类器;
这样我们就做到了鱼与熊掌兼得。
3. Bounding Box Regression
目标检测的回归任务一般是预测一组从 proposals 到目标框的偏移量。类似分类过程,我们同样也可视化了回归标签的分布随着训练进行的变化情况。如下图所示,从 500 次迭代到 50000 次迭代,相同 IoU 阈值下回归标签分布的标准差在不断减少,说明样本质量在不断提高。而且,在相同的 50000 次迭代次数下,如果提升 IoU 阈值,样本质量会得到进一步提高。
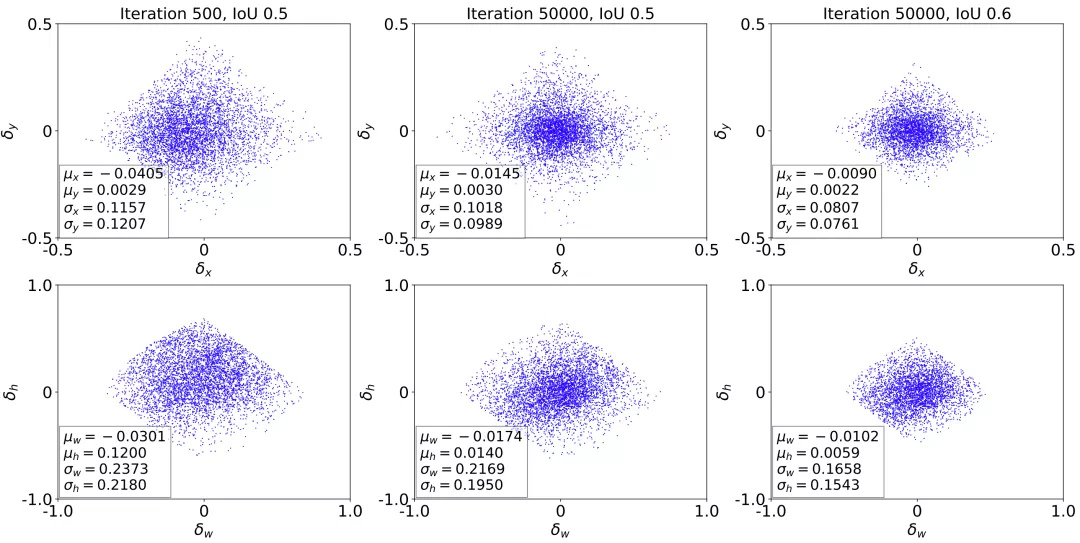
那么这些样本是如何对训练产生贡献的呢?
在检测任务中常见的回归损失函数是 SmoothL1 Loss,它是一个分段函数,而且分段的位置是由 β控制的,默认值为 1。如下左图所示,我们在这里绘制出了多种β取值下的 SmoothL1 Loss 以及 L1 Loss。
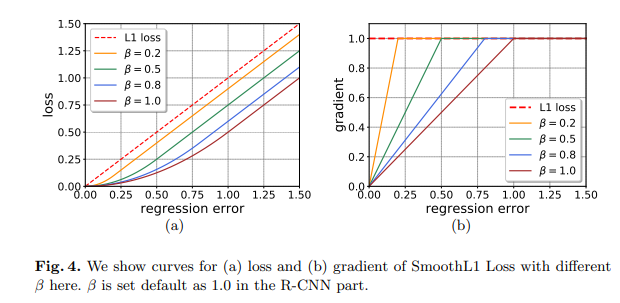
如果我们将左图换一种方式展示,就变成了右图的形式,主要是将纵坐标从 loss 换成了 gradient。从右图我们可以看出,高质量样本 (回归误差小) 对于训练的整体贡献被降低了,这并不利于我们训练高质量回归器,尤其是训练后期高质量样本更多的情况下。
所以我们应该调整回归损失函数的形状,来补偿高质量样本对于训练的贡献。
三、方法细节
经过前面对于问题的详细分析,解决方法 Dynamic R-CNN 基本上已经呼之欲出了。我们的 key insight 在于调整第二阶段的分类器和回归器,以适应 proposals 分布的改变。整体的框架如下图所示。
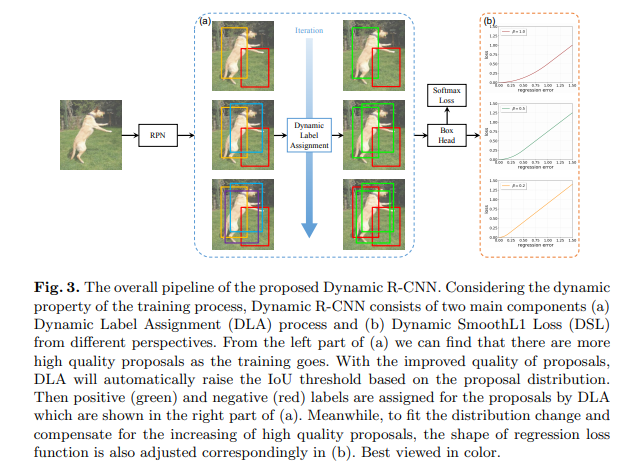
Dynamic R-CNN 主要由两个部分组成,这两个部分分别针对前面分析过的分类任务和回归任务:
动态标签设计策略 (Dynamic Label Assignment, DLA):通过调整训练使用的 IoU 阈值来适应更高质量的样本,从而提高分类器对于高质量样本的判别能力
动态回归损失函数 (Dynamic SmoothL1 Loss, DSL):通过调整回归损失函数的形状 (SmoothL1 Loss 的β ) 来补偿高质量样本对于整体训练的贡献
那么我们应该如何去调整呢?
通常而言,我们更希望整体的调整过程是自动的,所以我们使用了一种基于统计量的方法:考虑到在每次迭代中,所有训练样本中位于固定分位点上的样本质量其实可以衡量整体样本的质量,所以我们会使用位于某个分位点上样本的统计量来调整其网络设定。
具体来说:
对于分类任务而言,我们会使用第KI精确的样本的 IoU 阈值去更新训练的 IoU 阈值
对于回归任务而言,我们会使用第Kβ精确的样本的回归标签去更新回归损失函数的β值
当然,考虑到训练的稳定性,我们会使用 C 次迭代统计量的均值或者中值来更新相应的网络设定
整体的算法流程如下图所示:

值得注意的是,算法的整体计算量主要集中在 IoU 以及回归标签的计算,但是这些是原始方法已经计算过了的。换句话说,我们增加的额外计算复杂度只是计算 C 次 (默认为100) 迭代统计量的均值或者中值,所以相当于基本不增加训练计算复杂度。而且因为我们只调整了训练过程,所以我们也不会增加测试额外开销。
四、实验结果
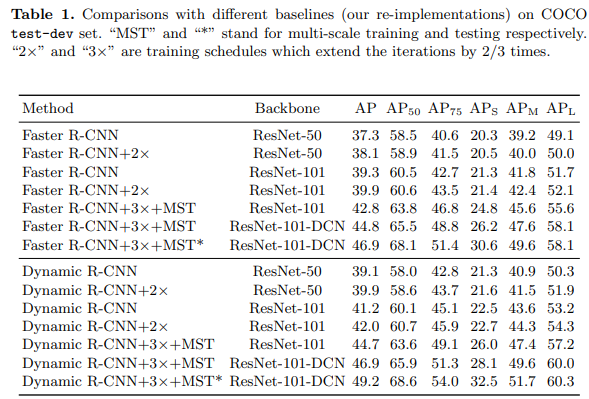
我们做了详细的实验来验证方法的有效性。首先,我们提供了在多种设定下和 baseline 的对比实验。如下图所示,我们尝试了多种主干网络、更长的训练时间以及其他训练和测试设定。实验结果表明我们的方法在不同设定下均能够有两个点左右的稳定提升,证明了我们的方法可以和上述不同设定兼容。值得注意的是,我们的方法在更强的 baseline 下涨点不仅不衰减反而更加明显,这也说明我们的方法的上限很高。
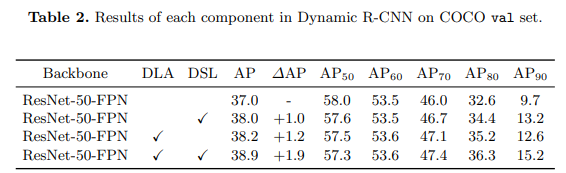
其次,我们分析了不同部分对于最终结果的影响。如下图所示,DLA 和 DSL 都能够独立的带来一个点左右的提升,而且集中在高质量指标 (例如 AP90) 上。不仅如此,考虑到 DLA 会提高训练正样本的质量,DSL 在此基础上也能够进一步改进整体的结果,最终相比于 baseline 能够提升 1.9 AP 和 5.5 AP90。
为了更直观的展示我们的方法对于网络设定的调整情况,我们绘制了不同迭代次数下 IoU 和 SmoothL1 β的动态调整情况。如下图所示,我们发现具体的分位点取值并不会影响整体的变化趋势。随着训练的进行,IoU 倾向于升高而 SmoothL1 β倾向于降低,这也和我们观察到的训练样本质量提升表现一致。
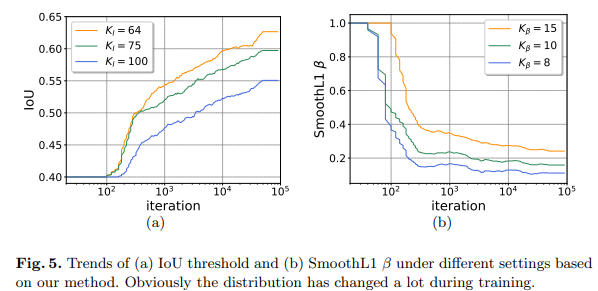
我们同时也验证了一下不同超参数的设定对于结果的影响情况。如下图所示,实验结果对于这些超参数都比较鲁棒,改变这些超参数带来的差别主要体现在不同质量指标下的结果,例如采用更小的KI会让更高质量下的指标提升。
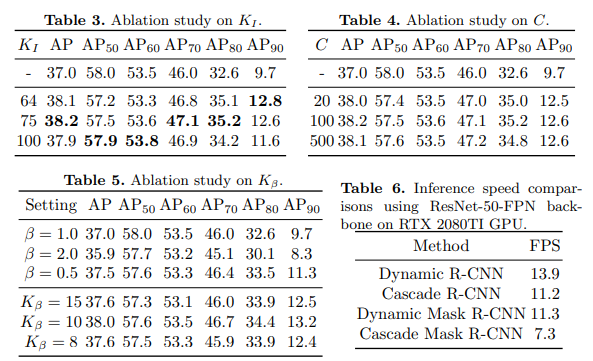
顺带一提,我们其实并不是增加了三个超参数,因为KI和Kβ是用来替换 IoU 和 SmoothL1 β 的,所以我们只添加了一个超参数 C,而且结果对于这个超参数也非常棒。
计算复杂度以及速度方面,我们相比于之前的高质量检测器还是有很大优势的。这里我们对比了经典的 Cascade R-CNN[2]。首先,我们基本上不增加训练时间。其次,我们的测试速度快很多。我们在 ResNet-50 基础上如果使用检测头部大概速度是 1.25 倍,如果使用分割头部则速度为 1.5 倍。考虑到主干网络对于速度也有影响,如果替换为 ResNet-18 我们方法大概速度是相同设定下Cascade Mask R-CNN的 1.74 倍。
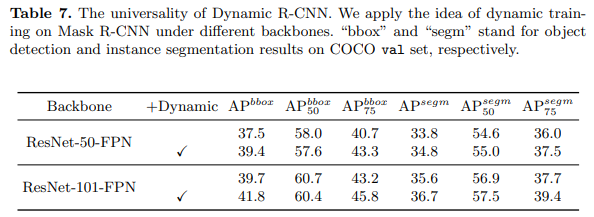
考虑到这种动态观点其实是很通用的,我们也在其他任务上验证了方法的通用性。如下图所示,我们在实例分割任务上基于 Mask R-CNN 进行了实验,结果表明我们的动态设计在不同主干网络上都有着一致的提升。值得注意的是,我们这里只使用了论文所提到的 DLA 和 DSL,并没有针对实例分割这个任务进行特殊的设计,所以在分割结果上的提升更能体现我们方法的通用性。
最后,我们也在COCO test-dev上提供了和其他方法的整体对比。如下图所示,我们最终能够达到 50.1 的平均精度,超过了其他对比的方法。

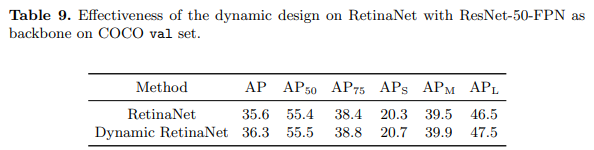
如表9所示,我们的动态设计使盒式AP比RetinaNet基线高出0.7点。应该注意的是,RetinaNet已经将SmoothL1损失的β更改为较小的值(0.11),因此在我们的实验中,将β调整为较小的值(DSL使用0.05)效果不大。此外,由于RetinaNet的输入是预定义的锚,因此输入的分布相对固定。因此DLA的影响可以视为使用更合理的IoU阈值(例如0.55)进行训练。
为了进一步证明我们方法的有效性,我们在PASCAL VOC [10]数据集上进行了与MS COCO数据集相同的超参数实验。我们使用VOC2007和VOC2012训练量的并集作为训练集,并在VOC2007测试集上报告结果。如表10所示,动态R-CNN将Faster R-CNN基线提高了1.5点AP和3.5分的AP90。 因此,我们得出了与COCO数据集上的结果相似的结论,这证明了动态R-CNN的有效性和普遍性。
五、总结
在本文中,我们首先指出了固定的网络设定和动态的网络训练之间的不一致性,并且分析了这个问题对于检测所要解决的分类和回归任务的影响。然后我们提出了 Dynamic R-CNN,通过动态调整标签设计策略和回归损失函数的方式让网络适应质量逐渐提高的输入样本。
我们的方法可以在不增加复杂度的情况下带来稳定的提升,对于高质量目标检测相当于一顿free lunch~
而且值得一提的是,我们提出的这种动态观点是通用的,毕竟很多任务中都存在像这种固定的网络设定和动态训练之间的不一致性问题,所以我们也希望我们的工作可以启发更深远的研究。
申明:论文原文来源网络,由《计算机视觉社区》公众号整理分享大家,仅供参考学习使用,不得用于商用,引用或转载请注明出处!如有侵权请联系删除!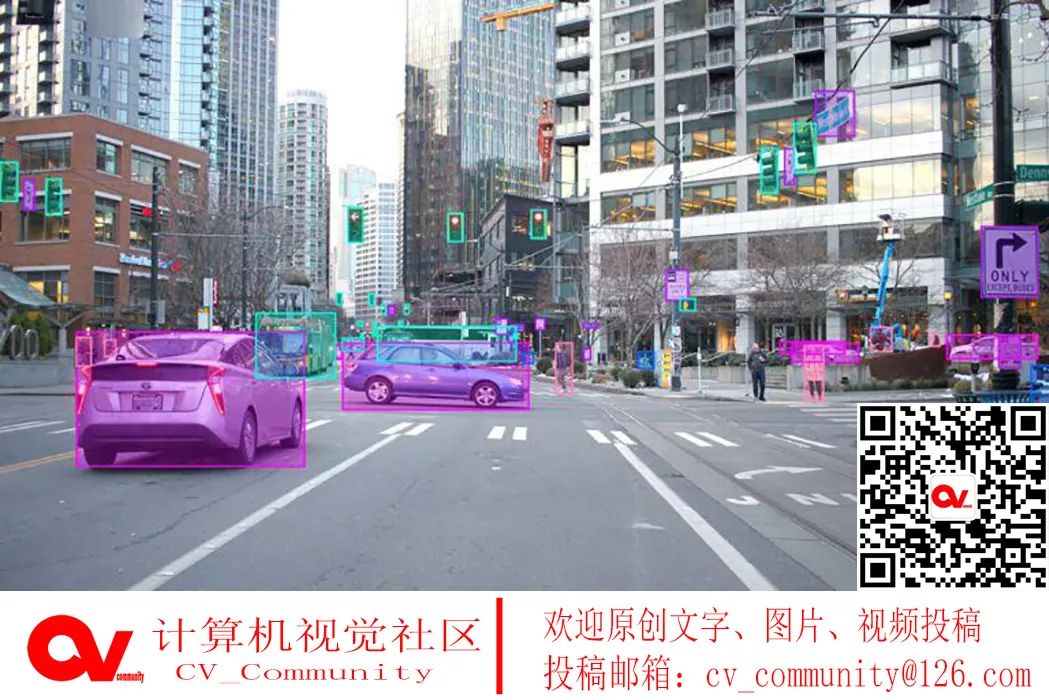
点一下 在看 会更好看哦
















 389
389











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









