









目的:CVPR 2017论文pix2pix,在image2image的任务之中具有很好的效果。我们需要详细解析此论文,搞懂其中的原理。
项目地址:https://phillipi.github.io/pix2pix/
论文地址:https://arxiv.org/abs/1611.07004
目录
一、概览及基础
1.1 效果概览

labels map——photos
重建的图像——边缘图像
黑白图像——彩色图像
conditional adversarial networks(cGAN) 在image2image的任务之中表现出色
- 学到 从图像到图像 的map
- 学到loss函数用于训练map
1.2 传统GAN原理
cGAN是在传统GAN的基础上改进的,所以我们需要弄明白传统GAN的原理才能弄明白cGAN的作用。
https://blog.csdn.net/leviopku/article/details/81292192
https://www.jianshu.com/p/40feb1aa642a

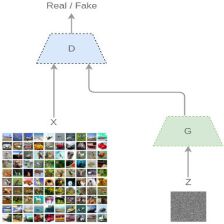
传统GAN有一个生成器Generator和判别器Descriminator,生成器G用于生成样本,判别起D用于判断这个样本是否为真样本。G用随机噪声生成假图,D根据真假图进行二分类的训练。D根据输入的图像生成score,这个score表示G生成的图像是否成功,进而进一步的训练G生成更好的图像。


- 判别器D的监督信息就是真实的数据和G生成的数据打成的标签。
- 判别器G的监督信息就是D(G(z)),也就是G生成图像再判别器中的score。
在训练过程中,生成网络G的目标就是尽量生成真实的图片去欺骗判别网络D。而D的目标就是尽量把G生成的图片和真实的图片分别开来。(此公式必须深入并且反复理解,需要时参考GAN原论文)在pix2pix论文之中,作者更加引入了conditional的内容,相应的公式是这个公式的变种。深入理解这个公式的基础上才能够理解pix2pix的公式。见本文的2.2目标函数。
![]()
- 整个式子由两项构成。x表示真实图片,z表示输入G网络的噪声,而G(z)表示G网络生成的图片。
- D(x)表示D网络判断真实图片是否真实的概率(因为x就是真实的,所以对于D来说,这个值越接近1越好)。而D(G(z))是D网络判断G生成的图片的是否真实的概率。
- G的目的:上面提到过,D(G(z))是D网络判断G生成的图片是否真实的概率,G应该希望自己生成的图片“越接近真实越好”。也就是说,G希望D(G(z))尽可能得大,这时V(D, G)会变小。因此我们看到式子的最前面的记号是min_G。
- D的目的:D的能力越强,D(x)应该越大,D(G(x))应该越小。这时V(D,G)会变大。因此式子对于D来说是求最大(max_D)
1.3 GAN分类
传统GAN 通过随机向量z生成图像y: z -> y
conditionalGAN(cGAN),pix2pix,通过随机向量z和图像x生成需要图像y :(z,x) -> y
cycleGAN,discoGAN与dualGAN
https://www.sohu.com/a/135098277_680233
DCGAN、WGAN、WGAN-GP、LSGAN、BEGAN
https://blog.csdn.net/qq_25737169/article/details/78857788
二、方法
2.1 conditional GAN(cGAN)
传统GAN 通过随机向量z生成图像y: z -> y
conditionalGAN(cGAN),pix2pix,通过随机向量z和图像x生成需要图像y :{z,x} -> y

G用于生成尽可能愚弄判别器的图像,判别器D尽可能判别G生成的假图和真实图像。
2.2 目标函数
cGAN的loss选取是与GAN不同的,再GAN的基础上做了一定的更改,即加了conditional的特性,并且多了一个L1 loss使源域和目标域的图像尽量的接近。

![]()
与GAN的目标类似,见上面1.2.但是GAN是根据随机噪声z生成图像,而cGAN是根据随机噪声z和输入图像x去生成。因此公式意义有一定的调整,与上面大同小异:
- 整个式子由两项构成。x表示源域图像,y表示真实图片,z表示输入G网络的噪声,而G(x,z)表示G网络根据源域图像和随机噪声生成的目标域图片。
- D(x,y)表示D网络判断真实图片是否真实的概率(因为y就是真实的,所以对于D来说,这个值越接近1越好)。而D(x,G(x,z))是D网络判断G生成的图片的是否真实的概率。
- G的目的:上面提到过,D(x,G(x,z))是D网络判断G生成的图片是否真实的概率,G应该希望自己生成的图片“越接近真实越好”。也就是说,G希望D(x,G(x,z))尽可能得大,这时1-D(x,G(x,z))会变小。因此我们看到式子的最前面的记号是min_G。
- D的目的:D的能力越强,D(x,y)应该越大,D(x,G(x,z))应该越小。这时1-D(x,G(x,z))会变大。因此式子对于D来说是求最大(max_D)
cGAN与GAN的不同之处在于,cGAN的G作用除了生成可以愚弄D的图像之外,还需要尽量接近目标域的图像y,
![]()
关于loss的选取,选用L1 loss而不用L2 loss从而保证更少的模糊。(对于一维的数据,最小化L2 loss居然是获得算术平均数;最小化L1值得到的是中位数。)(具体论证论文中没有给出为什么能够保证更少的模糊,只给了个相关工作D. Pathak, P. Krahenbuhl, J. Donahue, T. Darrell, and A. A. Efros. Context encoders: Feature learning by inpainting. In CVPR, 2016)
最终的loss函数为:
![]()
三、网络结构
3.1 生成器G
G的结构采用的是U-Net
image2image需要从一个高分辨率图像到另一个高分辨率图像,即输入输出虽然在表面细节不同,但是具有相同的底层大致的结构,所以输入与输出需要粗略的对齐。对于图像的任务而言,作者需要输入输出之间除了共享高层语义信息之外,还需要能够共享底层的语义信息。这样,U-Net就可以被运用起来。
特别的,为了更好的传递信息,作者加了skip connections, 直接从i层传输到n-i层,n是总得网络层数,i是与n-i层之间有相应的通道。具体参考U-Net的论文:
O. Ronneberger, P. Fischer, and T. Brox. U-net: Convolutional networks for biomedical image segmentation. In MICCAI, 2015
3.2 马尔可夫判别器(PatchGAN)
采用L2 loss与L1 loss会导致相对模糊的图像,比如下面的采用L1 loss生成的图像之中,明显模糊 (实验得出的结论,具体推导并没有).

对于低频信息的话,选取L1 loss可以达到很好的重建。但是对于高频信息,作者重新设计了一个新结构,PatchGAN,它只判断一个N*N的patch是真是假,所以能更好的判别高频信息。即使N远小于原图的大小,patchGAN依然可以产生较好的结果。并且,它具有更少的参数,运行更快,并且可以运用于任意大的图像。
3.3 optimization与inference
作者采用原GAN论文的训练网络方法,先对D进行一次梯度下降,然后对G进行一次梯度下降。再训练G的过程中,作者没有采用最小化 log(1 -D(x,G(x, z)),而是采用的是最大化log D(x,G(x,z)). In addition, we divide the objective by 2 while optimizing D, which slows down the rate at which D learns relative to G.作者运用了minibatch SGD与adam solver。
在inference过程之中,生成器与训练过程中的生成器一样。但是多了两点,一点是drop out,另一点是BN:
apply dropout at test time, and we apply batch normalization using the statistics of the test batch, rather than aggregated statistics of the training batch.
四、实验
4.1 数据集
数据集方面论文给的很详细并且有链接,需要则查阅原论文,我们不详述。
4.2 评判标准
评判生成图像的质量是个较难的问题。传统的评判方法是对每个像素点进行mean-squared error,我们运用两种策略进行我们的评判标准:
- 首先,我们运行“real vs. fake” on Amazon Mechanical Turk (AMT)数据集上。对于图像上色以及照片生成这种,人的观感是最终目标。AMT perceptual studies:将真图与假图暴露给被试,实验中每张图片暴露给被试一秒,被试可以用任意的时间反应。
- 其次,成型目标识别系统是否能很好的识别目标。FCN-score,运用FCN-8s 模型进行实验。
4.3 关于目标函数的分析
cGAN的loss选取是与GAN不同的,再GAN的基础上做了一定的更改,即加了conditional的特性,并且多了一个L1 loss使源域和目标域的图像尽量的接近。下面公式前面即cGAN的公式,参见前面2.2,后面L1 loss是尽可能的保证源域与目标域接近。
![]()

我们看到选取不同种类loss的情况下,作者的方法明显最优。
4.4 生成器结构分析
Unet与自编码器的对比。


4.5 patch的选取
FromPixelGANs to PatchGANs to ImageGANs
PatchGAN,它只判断一个N*N的patch是真是假,所以能更好的判别高频信息。即使N远小于原图的大小,patchGAN依然可以产生较好的结果。并且,它具有更少的参数,运行更快,并且可以运用于任意大的图像。
- 当patchsize为1*1时,则为pixelGAN
- 70*70 PatchGAN
- 286*286 ImageGAN

4.6 具体验证
作者在许多数据集上进行了验证,对我们没有太大作用,则不细看了,涉及多种image2image任务,需要则查阅原论文。
五、结论及个人总结
pix2pix在image2image的任务之中表现很好。其中唯一的创新点就是引入了conditionalGAN
conditionalGAN的改进一是GAN loss层面,加入了输入图像的条件。另外引入L1 loss使源域目标域图像尽量接近。


















 5895
5895

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











