






这篇文章的目的是分析BevFormer的架构图和公式,至于相关背景和实验结果,则不赘述。BevFormer的架构图如下:
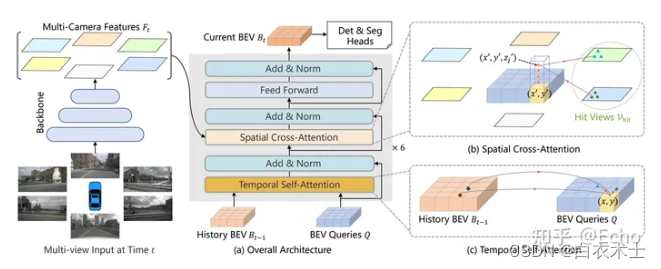
关注上图中间的第二部分,它由一个时间自注意力层(Temporal Self-Attention)、一个空间交叉注意力层(Spatial Cross-Attention)和一个前馈层构成,其输入来源有三:
1、环视摄像头提取的特征图
2、历史鸟瞰图特征
3、鸟瞰图查询
其中和
是TSA层的输入。它计算了
上每个点
相对于上一帧BEV特征
的上下文向量,它会捕捉到每个BEV上的特征点对上一帧中附近局部特征点的依赖性。

和
是SCA层的输入。对于BEV特征图中的每个点p,它采样N个不同高度的点,投影到环视特征图上,计算BEV视图上p点相对于这些投影点的加权上下文向量,再通过最上层的前馈残差网络得到
。它会捕捉到每个点对和它相关物体的依赖性。

上面公式中的可变形注意力(Deform Attention)定义如下面公式。可以把它理解为一个更高效的计算多头注意力的方法,它计算的结果仍然是一个在q点的上下文向量。和普通的多头注意力相比,它只加权了个不同的特征点,因此计算量更低。这导致BevFormer的注意力部分的计算复杂度比O(n^2)更小,其中n是BEV特征图的大小。另外一部分计算量是Backbone,它的计算复杂度是O(N^2*K^2*M),其中N^2是图像大小,K^2是卷积核大小,M是卷积核数量。比较起来,Backbone的复杂度似乎更大,那么BevFormer的整体复杂度应该和ResNet相当。
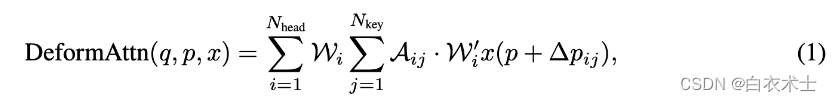















 795
795











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









