






在centos中使用docker安装ubuntu18.04
安装docker容器引擎
- 安装docker参考网上教程
- 运行命令查看active 运行状态
systemctl status docker - 查看docker拥有的镜像
docker images - 查看docker版本
docker -v - 查看centos版本
cat /etc/redhat-release - 查看centos内核版本
uname -r
安装nvidia-docker
- 首先提示安装docker(里面讲的是docker CE 其实就是 dockers Engine-Community)
- 若主机已经安装好docker 那么就直接安装Nvidia Container Toolkit
- nvidia-docker 官方链接 :
https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html#docker
安装带有指定系统版本和cuda版本的镜像
- nvidia官方镜像
- devel适合源码开发
- https://hub.docker.com/r/nvidia/cuda
建立docker 容器
- i 为交互模式
- t 为终端交互
- d 为后台运行
- gpus all 将所有gpu导入容器中
- name 指定容器名
- -v [本地目录]:[容器目录] (本地目录没有会自动创建)
sudo docker run -i -t -d --name ubuntu_cuda10.2 --gpus all nvidia/cuda:10.2-cudnn7-devel-ubuntu18.04 /bin/bash - 进入容器(exec只是进入容器的方式,可以在退出容器时不关闭容器)
如果不使用d参数,使容器进入后台运行,run容器之后会直接进入容器无法使用exec命令
docker ps 可以查看正在运行容器的ID
docker exec -it [CONTAINER ID] /bin/bash - 很多朋友总是通过run方式进入容器,其实时重新创建一个容器,这导致之前的容器配好环境就不见了。
docker start [容器ID]
如果退出容器时导致容器关闭了,可以重新启动容器,使用exec方式进入容器
docker stop [容器ID]
关闭运行的容器
怎么解压.zip.gz文件
tar xf 文件.tar.gz -C 指定目录(目录必须存在)
怎么把本地文件上传到容器里
docker cp [本地文件] [容器ID]:[容器中目录]
tar命令详解-参考博客
将配好环境的容器生成新的镜像
如果总是在一个固定环境下进行运行代码可以将之前配好环境的容器生成一个新的镜像
- 将容器保存为一个镜像
docker commit [容器ID] colmap:cuda10.2-ubuntu18.04 - 将镜像保存到本地
docker save -o [文件名.tar] [镜像ID]
为centos升级GCC
- 安装centos-release-scl
sudo yum install -y http://mirror.centos.org/centos/7/extras/x86_64/Packages/centos-release-scl-rh-2-3.el7.centos.noarch.rpm
sudo yum install -y http://mirror.centos.org/centos/7/extras/x86_64/Packages/centos-release-scl-2-3.el7.centos.noarch.rpm
- 安装devtoolset 将数字改为指定版本
sudo yum install devtoolset-9-gcc-c++
- 激活对应版本 只在本次
进入到devtoolset的安装目录/opt/rh/devtoolset-9
执行source ./enble
参考博客
在mobaXterm终端启用进程后台运行
两种信号 sigup和sigint
- sigup 是捕获终端关闭的信号 终端关闭导致进程结束
忽略(sigup)终端关闭信号,在命令前面添加nohup
nohup ping baidu.com
- nohup 保存输出到指定文件
nohup ping baidu.com > train.log 2>&1
- sigint 是捕获ctrl+c信号,用来关闭进程
忽略sigint信号, 在命令后面添加&
ping baidu.com &
设置cudnn寻找最优算法 节约时间
torch.backends.cudnn.benchmark=True
true的含义为 cudnn自动寻找最优算法
torch.backends.cudnn.enabled = True
true的含义为使用非固定算法
vscode中python调试设置为当前文件目录
shift+ctrl+P 搜索 launch.json
将cwd改为如下
"configurations": [
{
"name": "Python: 当前文件",
"type": "python",
"request": "launch",
"program": "${file}",
"console": "integratedTerminal",
"justMyCode": true,
"cwd": "${fileDirname}"
}
]
tensorRT yolov3 demo
安装nvidia驱动支持cuda11.6
TensorRT目前支持cuda11.6 所以要升级nvidia驱动和cuda
TensorRT GA build
TensorRT v8.4.1.5
System Packages
CUDA
Recommended versions:
cuda-11.6.x + cuDNN-8.4
cuda-10.2 + cuDNN-8.4
首先安装nvidia驱动 预装条件
需要使用yum 重新安装和配置阿里云镜像源 请参考yum重装
统一kernel和kernel-devel kernel-heards
安装nvidia驱动需要kernel-devel和kernel-headers
#首先查看你安装的kernel
uname -r
#查看你安装的kernel-devel和kernel-headers
rpm -qa | grep kernel
# 也可以直接安装kernel-devel和kernel-headers
sudo yum install kernel-devel-$(uname -r) kernel-headers-$(uname -r)
#如果无法直接安装 那么就查看 可安装的kernel-devel和kernel-headers
yum info kernel-devel kernel-headers
# 查找可安装的kernel-devel和kernel-headers版本,再安装对应版本的kernel
sudo yum install kernel-$(uname -r) 版本号和发布号可以自己指定
#再安装kernel-devel和kernel-headers
#指定系统启动使用默认的kernel
yum list installed kernel 查看已安装的kernel
grub2-editenv list 显示当前默认启动内核
grub2-set-default 'CentOS Linux (3.10.0-1160.66.1.el7.x86_64) 7 (Core)' 括号中包含uname -r 显示的类似内容对应修改就可
grub2-mkconfig -o /boot/grub2/grub.cfg 使设置生效
grub2-editenv list 查看设置是否生效
#重启查看内核是否修改过来
# 删除不用的内核
yum remove kernel-3.10.0-1160.66.1.el7.x86_64
yum remove kernel-devel-3.10.0-1160.66.1.el7.x86_64
# nvida显卡安装时需要GCC 又因为模型需要高版本GCC 在centos上安装高版本GCC
安装gcc参考:
安装全局gcc
# 安装高版本gcc需要一些依赖和编译器 所以yum安装gcc
dnf install gcc gcc-c++ -y
# 下载高版本gcc
wget https://gcc.gnu.org/pub/gcc/releases/gcc-10.2.0/gcc-10.2.0.tar.gz
tar -zxf gcc-10.2.0.tar.gz
cd gcc-10.2.0/
#下载安装gcc的依赖包
./contrib/download_prerequisites
# 生成makefile
mkdir build
cd build
../configure --prefix=/usr/local/gcc-10.2.0/ --enable-checking=release --enable-languages=c,c++ --disable-multilib
# 如果出现无法使用c编译器编译 查看一下config.log 提示ccl找不到
# 可以把原来gcc的全部删掉 重装一下gcc /usr/lib/gcc/x86_64-redhat-linux/4.8.5 出现 ccl
rpm -q gcc cpp
rpm -e cpp-4.8.5-36.el7.x86_64
rpm -e gcc-4.8.5-44.el7.x86_64
#make执行
make
make install
#删除yum下载的旧版本gcc
yum remove gcc
# 建立链接
ln -s /usr/local/gcc-10.2.0/bin/gcc /usr/bin/gcc
ln -s /usr/local/gcc-10.2.0/bin/g++ /usr/bin/g++
安装当前命令行有效的gcc版本
参考链接:centos7升级gcc版本
# Centos 7默认gcc版本为4.8,有时需要更高版本的,这里以升级至8.3.1版本为例,分别执行下面三条命令即可,无需手动下载源码编译
# 1、安装centos-release-scl
sudo yum install centos-release-scl
# 2、安装devtoolset,注意,如果想安装7.*版本的,就改成devtoolset-7-gcc*,以此类推
sudo yum install devtoolset-8-gcc*
# 3、激活对应的devtoolset,所以你可以一次安装多个版本的devtoolset,需要的时候用下面这条命令切换到对应的版本
scl enable devtoolset-8 bash
# 补充:这条激活命令只对本次会话有效,重启会话后还是会变回原来的4.8.5版本,
# 每个版本的目录下面都有个 enable 文件,如果需要启用某个版本,只需要执行
source /opt/rh/devtoolset-8/enable
安装nvidia-driver cuda cudnn
Tselav100 nvidia驱动安装官方文档
nvidia驱动安装官方文档
cuda官方安装文档
cuda配置环境变量
Disabling Nouveau操作手册
cudnn安装手册
# 安装cuda和cudnn 按照官方文档进行安装
# 查看cudnn版本
cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2
新建虚拟环境
conda create -n infer_trt python=3.6
conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cudatoolkit=10.2 -c pytorch
conda install cudatoolkit=10.2
conda install cudnn=7.6.5
#删除虚拟环境
conda remove -n infer_trt --all
tensorRT demo 历程
TensorRT安装过程 tar方式安装
TensorRT demo
network_api_pytorch_mnist
这个例子相当于用tensorRT自己的network API重新定义了网络结构,并且把原有网络的参数和定义好的网路结构做结合。
关键代码讲解
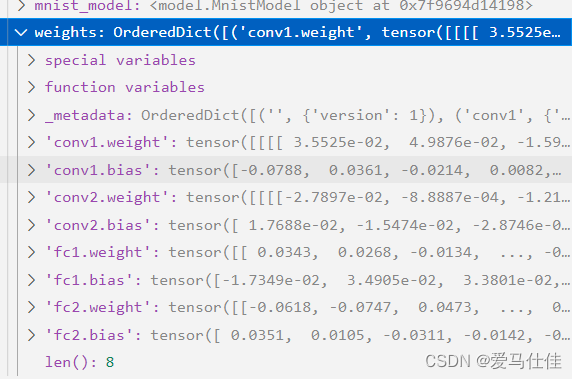
# mnist_model为原来用pytorch定义的模型并且完成了训练
# 使用gei_weight()方法中的state_dict()获取模型的参数字典
# weights是一个字典 key为网络每一层的参数名称
weights = mnist_model.get_weights()
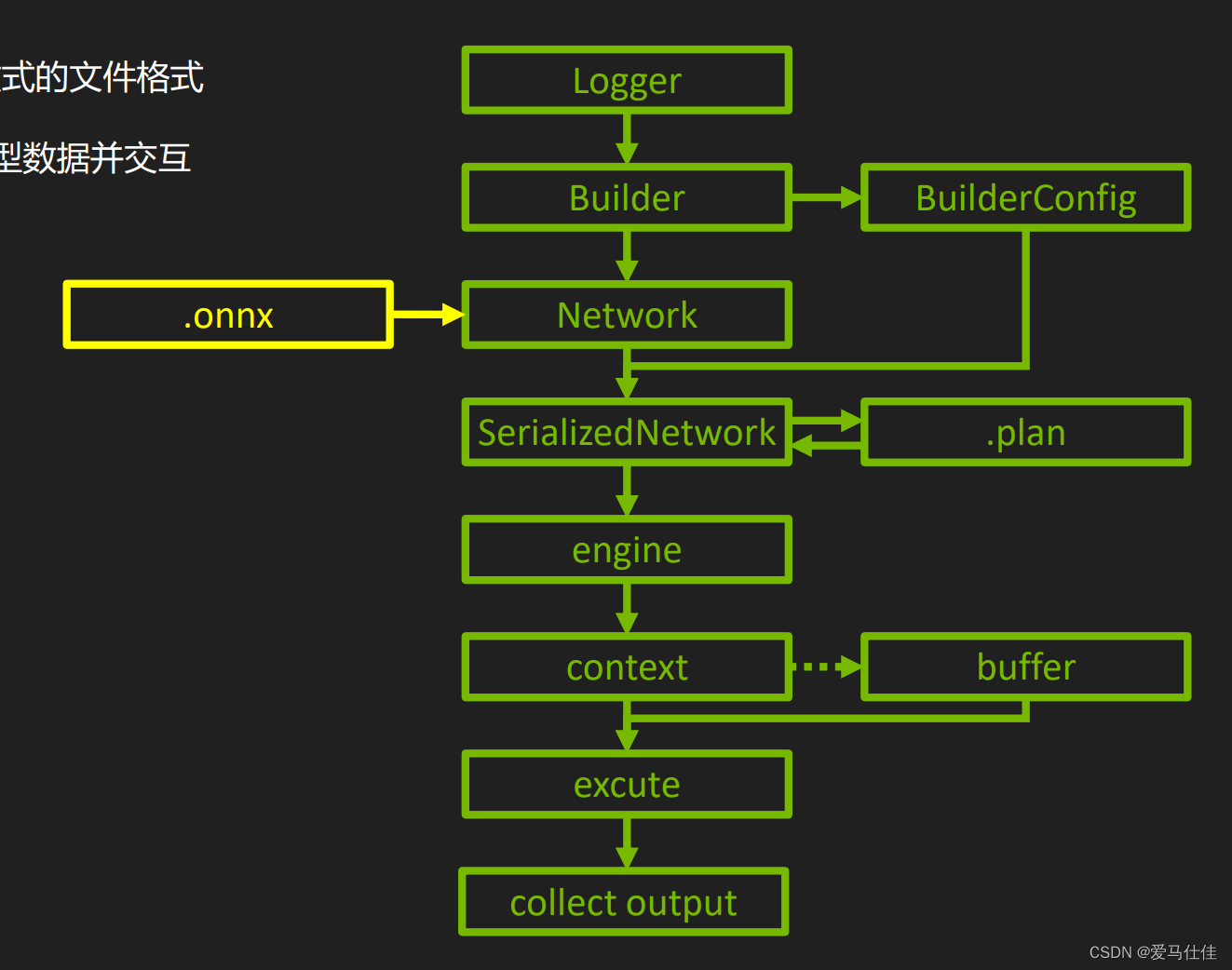
# 使用build_engine(weights)方法重新定义tensrRT网络并将参数导入tensorRT网络
engine = build_engine(weights)
# build_engine(weights)的定义与实现
# 创建一个日志对象 只打印警告信息
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
def build_engine(weights):
# For more information on TRT basics, refer to the introductory samples.
# 创建一个引擎构建器
builder = trt.Builder(TRT_LOGGER)
# 创建一个tensorRT网络定义
# EXPLICIT_BATCH = 1 << (int)(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)
# 1代表的是显式批处理模式,[N,3,H,W]相当于指定了存在batchsize这个维度
network = builder.create_network(common.EXPLICIT_BATCH)
# 下一步是创建一个构建配置,指定配置的属性,例如最大工作空间大小。
# 层实现通常需要一个临时工作区,这个参数限制了网络中任何层可以使用的最大大小。如果提供的工作空间不足,可能TensorRT将无法找到一个层的实现
config = builder.create_builder_config()
# 要执行推断,使用Runtime接口反序列化引擎。与构建器一样,运行时也需要日志对象。
runtime = trt.Runtime(TRT_LOGGER)
# 指定最大工作区间为1GB
config.max_workspace_size = common.GiB(1)
# Populate the network using weights from the PyTorch model.
# 把pytorch网络的参数输入进tensorRT网络
populate_network(network, weights)
# Build and return an engine.
# 构建引擎和序列化
plan = builder.build_serialized_network(network, config)
# 运行时在工作区把网络反序列化
return runtime.deserialize_cuda_engine(plan)
# 序列化就是将engine压缩到内存存储,反序列化就是解压缩成engine放到显存
# 为输入输出分配一个锁页内存和显存空间 并且创建一个流
inputs, outputs, bindings, stream = common.allocate_buffers(engine)
def allocate_buffers(engine):
inputs = []
outputs = []
bindings = []
stream = cuda.Stream()
for binding in engine:
# 遍历egine只有input和output两大类 可能有多个input和多个output
# 获取输入的尺寸和类型,方便分配内存大小
# a为shape (NCHW)
a=engine.get_binding_shape(binding)
# size= N×C×H×W
size = trt.volume(engine.get_binding_shape(binding)) * engine.max_batch_size
# 获取类型 FP32还是FP16或者INT8
dtype = trt.nptype(engine.get_binding_dtype(binding))
# Allocate host and device buffers
# 分配锁页内存大小 单位为字节 在主机内存中开辟一段固定物理地址的内存空间,方便GPU直接读取
host_mem = cuda.pagelocked_empty(size, dtype)
# 分配(显卡)设备内存 单位为字节 为了方便GPU将主机内存的数据直接拷贝到显存中来
device_mem = cuda.mem_alloc(host_mem.nbytes)
# Append the device buffer to device bindings.
# bindings list中存放input和output设备(显卡)所占内存
bindings.append(int(device_mem))
# Append to the appropriate list.
if engine.binding_is_input(binding):
# 如果是输入就把输入对应的主机锁页内存和显存放进列表
inputs.append(HostDeviceMem(host_mem, device_mem))
else:
# 如果是输出就把输出对应的主机锁页内存和显存放进列表
outputs.append(HostDeviceMem(host_mem, device_mem))
return inputs, outputs, bindings, stream
# context相当于一个中间件 在执行推理的时候将显存、引擎(包含模型)、cuda.stream囊括起来的一个中间件
context = engine.create_execution_context()
# 将随机选取的测试数据拷贝到input对应的锁页内存中
case_num = load_random_test_case(mnist_model, pagelocked_buffer=inputs[0].host)
# do_inference_v2主要是将锁页内存的数据拷贝到显存中,然后利用context 在stream(input的显存地址,output显存地址,引擎(包含模型))中执行推理 异步执行
[output] = common.do_inference_v2(context, bindings=bindings, inputs=inputs, outputs=outputs, stream=stream)
def do_inference_v2(context, bindings, inputs, outputs, stream):
# Transfer input data to the GPU.
# 从锁页内存拷贝数据到显存
[cuda.memcpy_htod_async(inp.device, inp.host, stream) for inp in inputs]
# Run inference.
# 异步执行推理
context.execute_async_v2(bindings=bindings, stream_handle=stream.handle)
# Transfer predictions back from the GPU.
# 将执行的结果从显存中拷贝到主机的锁页内存
[cuda.memcpy_dtoh_async(out.host, out.device, stream) for out in outputs]
# Synchronize the stream
# 使用同步机制确保推理全部完成
stream.synchronize()
# Return only the host outputs.
return [out.host for out in outputs]
进入到yolov3_onnx目录下 执行安装命令
python3 -m pip install -r requirements.txt
期间报错 src/cpp/cuda.hpp:14:18: fatal error: cuda.h: No such file or directory
这是安装pycuda时没有配置cuda的环境变量
export PATH=/usr/local/cuda/bin:$PATH vim .bashrc source .bashrc
还有需要注意的一点是 安装cuda版本和python版本对应的pycuda版本 参考版本说明
动态batch demo
# 使用日志对象创建一个推理引擎构建器
builder = trt.Builder(logger)
# 创建tensorRT网络对象
network = builder.create_network(1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))
# 创建tensorRT网络的动态张量的配置文件
profile = builder.create_optimization_profile()
# 创建网络属性配置对象
config = builder.create_builder_config()
# 指定构建期可用显存 单位为字节
config.set_memory_pool_limit(trt.MemoryPoolType.WORKSPACE, 3 << 30)
# 设置网络的精度
if isFP16Mode:
config.flags = 1 << int(trt.BuilderFlag.FP16)
if isINT8Mode:
config.flags = 1 << int(trt.BuilderFlag.INT8)
config.int8_calibrator = calibrator.MyCalibrator(calibrationDataPath, nCalibration, (1, 1, nHeight, nWidth), cacheFile)
# 创建parser对象将onnx网络解析到network
parser = trt.OnnxParser(network, logger)
if not os.path.exists(onnxFile):
print("Failed finding onnx file!")
exit()
print("Succeeded finding onnx file!")
with open(onnxFile, "rb") as model:
if not parser.parse(model.read()):
print("Failed parsing .onnx file!")
for error in range(parser.num_errors):
print(parser.get_error(error))
exit()
print("Succeeded parsing .onnx file!")
inputTensor = network.get_input(0)
# 设置网络输入的动态尺寸
profile.set_shape(inputTensor.name, (1, 1, nHeight, nWidth), (4, 1, nHeight, nWidth), (8, 1, nHeight, nWidth))
# 将设置的 profile 传递给 config 以创建网络
config.add_optimization_profile(profile)
output2 = network.get_output(1)
network.unmark_output(network.get_output(0)) # 去掉输出张量 "y"
# 生成 TRT 内部表示
engineString = builder.build_serialized_network(network, config)
if engineString == None:
print("Failed building engine!")
exit()
print("Succeeded building engine!")
with open(trtFile, "wb") as f:
f.write(engineString)
# 反序列化生成GPU执行引擎
engine = trt.Runtime(logger).deserialize_cuda_engine(engineString)
使用日志对象创建一个推理引擎构建器
创建tensorRT网络对象
创建tensorRT网络的动态张量的配置文件
创建网络属性配置对象
指定构建期可用显存 单位为字节
设置网络的精度
创建parser对象将onnx网络解析到network
设置网络输入的动态尺寸
将设置的 profile 传递给 config 以创建网络
序列化生成 TRT 内部表示
反序列化生成GPU执行引擎














 453
453











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









