






\1. 值得关注的点
- 特征级:说来说去对齐就两点-最小化特征分布差异、通过对抗增加域混淆
- 图像级:大多是基于GAN的两域之间的域混淆的方式缩小域间差异
- 输出级:类似特征级
\2. 相关技术总结
2.1 伪标签与自训练(Pseudo-labelling and self-training)
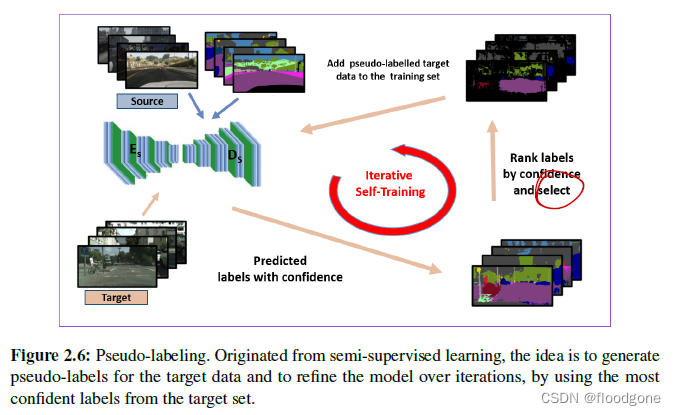
- 思想就是通过生成关于目标域图像的伪标签,并在迭代中不断的进行更新。
- 事实上,伪标签往往容易出错。重要的工作是选择最可靠的伪标签,并随着训练的进行逐步增加伪标签的集合。思想:假设预测值高于某一阈值的伪标签是可靠的;反之,低于阈值的值是不可信的。
- 依靠模型输出的**最大类概率(MCP)**来推断伪标签置信度,参考文献:
- softmax预测的熵(应该就是直接使用softmax进行概率比对)
其中一些具有代表性的工作:
- Zou等人(2018)为了避免占比较大的类在伪标签生成上逐渐占主导地位,提出一个类平衡的自训练框架,并引入空间先验来细化生成的标签。
- Kim等人(2020)两阶段方法:第一阶段进行纹理不变的预训练;第二阶段对伪标签进行优化。
- Shen等(2019)将不同判别器的输出与分割分类器的置信度相结合,以提高伪标签的可靠性。
- Corbière等人(2021)提出了一种辅助网络(ASPP,更好地处理图像中大小不等的语义区域)来估计语义分割的真实类概率图,并将其集成到一个对抗学习框架中,以应对预测的真类概率可能受到域偏移的影响。
- Mei等人(2020)提出了一个实例自适应框架,其中伪标签通过自适应选择器生成,即基于置信度的选择策略,该策略具有在整个训练过程中自适应更新的置信度阈值。其中使用的正则化技术分别对伪标记区域和非伪标记区域进行平滑和锐化处理。
- Zhang等人(2019)提出一种在交叉熵损失和类别距离损失中都使用伪标签的策略,其中使用类相关的质心将伪标签分配给训练样本
- Tranheden等人(2021)提出将两个领域的图像以及相应的标签和伪标签混合在一起。在训练模型时,他们在目标域和跨域混合图像的预测之间强制一致性。
- Guo等人(2021b)提出通过元校正框架提高伪标签的可靠性;他们通过引入一个编码类间噪声转换关系的噪声转换矩阵来模拟伪标签的噪声分布。通过元学习策略,在自训练过程中自适应地从所有样本中提取知识,进一步利用元校正损失来改进伪标签。
- Wang等人(2020g)通过考虑与Thing和Stuff相关的区域,使用伪标签来分离源和目标特征。
- Du等人(2019)根据下采样的伪标签使用单独的语义特征来构建需要重新权衡对抗损失的class-wise置信度图。渐进置信度策略用于获得可靠的伪标签,进而获得类的置信度映射。
- 总结:主要的方法集中于小组件对伪标签优化以及数据增强策略两个方面
2.2 目标预测的熵最小化(entropy minimization)
- 最初是为半监督学习设计的,熵最小化作为领域对齐的一种替代或补充技术得到了广泛的认可。不同的DASiS/UDA方法通过将其与对抗损失联合应用,扩展了目标数据上的简单熵最小化
- 一些方法:
- Huang等人(2020a)设计了一种基于熵的极大极小对抗学习方案,以跨域对齐局部上下文关系。其在标记的源域的特征空间中明确地强制执行原型局部上下文关系,同时使用梯度反转层通过基于反向传播的对抗学习将它们转移到未标记的目标域。
- Chen等人(2019a)表明,基于熵最小化的UDA方法往往存在概率不平衡问题。为了避免适应过程被最容易适应的样本所支配,他们提出了一个具有线性增长梯度的类平衡加权最大平方损失。此外,通过对网络不同层次的输出映射进行平均得到的伪标签,在低级特征上进行自训练。
- Toldo等人(2021)将这种图像类平衡熵最小化损失集成到基于特征聚类的正则化中。
- 广义形式的对抗熵最小化:Bijective Maximum Likelihood loss
2.3 课程学习(curriculum learning)
- Curriculum Learning会根据样本的难易程度,给不同难度的训练样本分配不同的权重。初始阶段,给简单样本的权重最⾼,随着训练过程的持续,较难样本的权重将会逐渐被调⾼。(类似渐进式的方法)
- 相关方法:
- Zhang等(2020b)提出使用图像级标签分布来指导像素级目标分割。
- Sakaridis等人(2019)提出了一种课程学习方法,其中模型从日到夜的学习,逐渐增加黑暗水平。他们利用在不同白天捕获的图像的对应关系来改进推理时间的像素预测。
- Lian等人(2019)采用易-难课程学习方法,首先在图像级,然后在区域级,最后在像素级(主要任务)预测标签。
- Pan等(2020)根据熵将目标数据分为简单样本和硬样本,并试图通过在相应的熵图上进行所谓的域内对抗训练来缩小这些预测之间的差距。
2.4 协同训练(Co-training)
- 思想:让两个不同的分类器强制不同,以便在预测相同标签的同时捕获数据的不同视图。根据学习参数使分类器多样化,同时最大限度地提高对其预测的共识,将鼓励模型为目标域输出更多的判别特征图。本质是靠近类边界的目标样本很可能被源分类器错误分类,利用两个分类器对目标样本预测的不一致可以隐式地检测到这种情况,从而改善类边界。
- 相关方法:
- Saito等人(2018b)提出了第一个最大化分类器差异(MCD)的UDA模型,其中对抗模型交替使用:1)在保持特征生成器固定的情况下,最大化目标样本上两个分类器之间的差异;2)在保持分类器固定的情况下,训练特征编码器以最小化差异。
- Lee等人(2019a)考虑切片Wasserstein差异来捕获预测概率度量之间的不相似性,这为检测远离源支持的目标样本提供了几何上有意义的指导。
2.5 自集成(Self-ensembling)
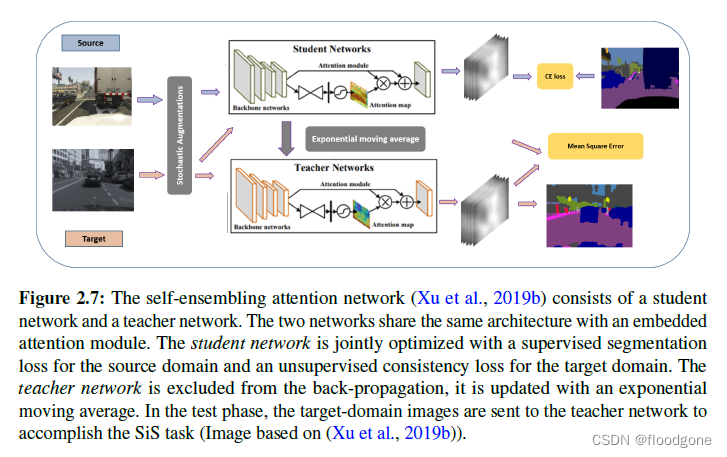
- 属于半监督学习的一种方法。 使用模型的集合,利用在不同扰动下预测的一致性。
- 相关方法1:
- EMA(移动指数平均)。Valpola(2017)用EMA取代平均预测。在后一种情况下,使用平均教师框架(由第二个不可训练的模型表示),其权重用基于实际可训练权重使用EMA进行更新。教师通常是一个综合模型,平均学生的权重,因此来自教师的预测可以被解释为学生模型的伪标签。
- French等人(2018)将Tarvainen和Valpola(2017)提出的模型扩展到UDA,考虑源和目标的单独路径,并对独立批次进行采样,使批量归一化(BN) (Ioffe和Szegedy, 2015)在训练过程中具有领域特异性。
- Xu等人(2019b)的自融合注意力网络旨在提取用于域适应的注意力感知特征(上图)。
- 相关方法2:
- 集成模型是有效的,但需要大量调优的手动数据增强才能成功地进行领域对齐,与上面提到的集成模型相反,提出了下列相关方法:
- Choi等人(2019)提出了一种自集成框架:光谱归一化下的基于GAN的目标引导的数据增强。为了对源样本和增强样本进行语义准确的预测,使用了语义一致性损失。
- Wang et al. (2021b)提出了一种依赖于AdaIN (Huang and Belongie; 2017))的方法将源图像的样式转换为目标图像的样式,风格转换(参考之前博士组会讲过的论文 2021CVPR)。在利用自我训练的训练管道中利用风格化的图像,其中通过使用自集成来改进伪标签。
2.6 模型蒸馏
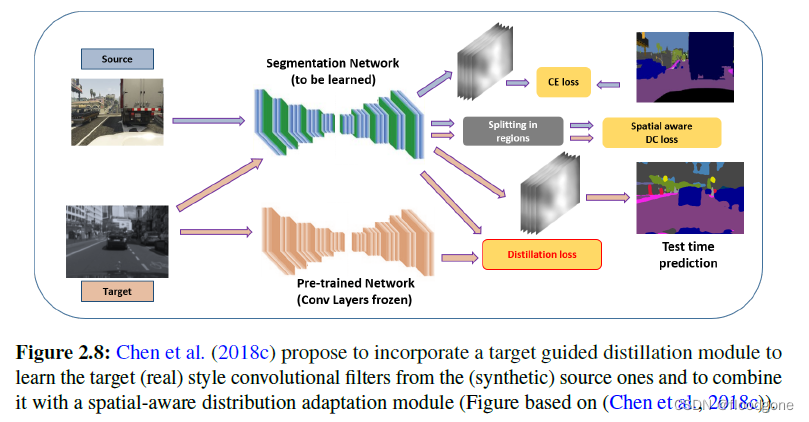
- 模型蒸馏(Hinton等人, 2015)已经被引入,作为一种将知识从一个大模型转移到一个小模型的方法。比方说将模型集合的判别能力压缩到一个更轻的模型中。在DASiS的背景下,它被用来指导目标域更强大的特征的学习,传递源域上获得的判别能力。
- 相关文献:
- Chen等人(2018c)提出通过使用蒸馏策略来学习目标风格的卷积滤波器来解决分布对齐问题(上图)
- Kothandaraman等人(2021)提出的领域自适应知识蒸馏模型包含一个多层次的策略,使用KL散度和MSE损失的组合以有效地提取不同层次(特征空间和输出空间)的知识。
- Chen等人(2022)将自我训练形式化为知识蒸馏,通过从源教师模型中提取知识蒸馏来学习目标网络。分析了将基于Swin Transformer的分割模型应用于新域时的限制,并认为这些问题是由于目标域的伪标签构建和特征对齐过程中产生的严重高频成分造成的。作为解决方案,他们引入了一种集成在动量网络中的低通滤波机制,该机制平滑了目标域特征及其伪标签的学习动态。然后使用动态对抗训练策略来对齐分布,其中使用动态权重来评估样本的重要性。
- DAFormer:基于知识提炼的自我训练框架中利用了Transformer的优势。提出的DAFormer架构基于Transformer编码器和上下文感知融合解码器。为了克服自适应不稳定性和对源域的过拟合,他们提出(这里不是propose提出,应该是使用utilize)了Rare类采样,它考虑了源域的长尾分布。他们通过Thing-进一步提炼ImageNet知识类ImageNet特征距离。
- 自集成和模型蒸馏在这里面说的比较像,个人认为DAFromer作者提出的系列更像是集成学习而不是模型蒸馏。
2.7 对抗攻击(Adversarial attacks)
- 对抗性攻击的目的(Szegedy等人,2014)是以一种使深度神经网络在处理失败的方式来扰乱示例,以对抗的方式训练干净和扰动样本的模型。
2.8 自监督学习(Self-supervised learning)
- 使用伪标签或者在优化伪标签就是在进行自监督学习。
\3. 有价值参考文献
3.1 特征级
- 最早MMD:https://arxiv.org/abs/1502.02791
- Flat or Pool 激活图:https://openaccess.thecvf.com/content_ECCV_2018/papers/Haoshuo_Huang_Domain_transfer_through_ECCV_2018_paper.pdf
- 像素级:https://arxiv.org/abs/1612.02649
- 块级:https://arxiv.org/abs/1704.08509
- 区域级:https://arxiv.org/abs/2006.06570v1
- 不同类的单独训练:https://openaccess.thecvf.com/content_CVPR_2020/papers/Lv_Cross-Domain_Semantic_Segmentation_via_Domain-Invariant_Interactive_Relation_Transfer_CVPR_2020_paper.pdf
3.2 图像级
- 循环一致性损失和语义一致性损失的提出:https://arxiv.org/abs/1711.03213
- 保守损失(惩罚过好过差结果):https://arxiv.org/abs/1809.00903
- 语义感知的Grad-GAN(为不同语义传递个性化风格):https://arxiv.org/abs/1801.01726
- 基于KL散度的双向跨域一致性损失:https://arxiv.org/abs/2001.03182
- 感知损失:https://arxiv.org/abs/2003.04614
- 傅里叶变换:https://arxiv.org/abs/2004.05498,https://arxiv.org/abs/2004.04923
失:https://arxiv.org/abs/2003.04614
- 傅里叶变换:https://arxiv.org/abs/2004.05498,https://arxiv.org/abs/2004.04923















 1773
1773











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









