






1 动机
- 跨域场景分类提出的背景:由于遥感场景分类缺乏高质量的标记数据导致监督模型泛化能力较差,为了更好地利用现有知识对未标记数据进行分类。
- 由于训练集(源域)和测试集(目标域)之间存在数据分布差异,因此提出了许多深度域自适应方法来减小这种分布差异。
- 现有域自适应的常用手段:使用差异度量函数对齐边缘分布,但忽略了域内每个样本对网络权重的影响。(本文切入点1)
- 现有域自适应方法不能很好地自适应平衡边缘分布和条件分布的相对重要性。(本文切入点2)
2 一句话概述
本文提出了一种新的基于注意的动态对齐和动态分布自适应方法,通过计算不同域内每个样本的动态权重,更好地对齐不同分布之间的边缘分布,动态平衡边缘分布和条件分布的相对重要性。
3 Introduction
- 提到了一系列迁移学习域自适应方法:如何减小边缘分布;同时考虑边缘分布和条件分布。
- 对于遥感跨场景分类任务,现有方法仍然存在以下挑战:
- **通常使用MMD损失函数约束边缘分布差异,没有考虑源域和目标域中每个样本的影响。**由于源域和目标域的每个样本都是不同的,需要改进传统域自适应特征提取模块(如ResNet和AlexNet),考虑每个样本对模型参数的影响,提取域不变特征。
- **知识的转移往往是盲目的。**对于训练图像,现有的特征提取网络很难增强关键区域的权重,削弱背景值的权重,这对于获得具有判别性的语义特征非常有用。
- 平衡边际分布和条件分布的相对重要性并不容易。在现有的研究中,条件分布会被认为和边际分布一样重要,但这种观点已经被实验证明是有缺陷的。尽管Zhu等人将边际分布和条件分布考虑在内,但他们手动调整两个分布之间的平衡参数,这将导致平衡参数进入局部最优状态。
4 Related Work
域自适应和注意力机制的相关工作
5 Method
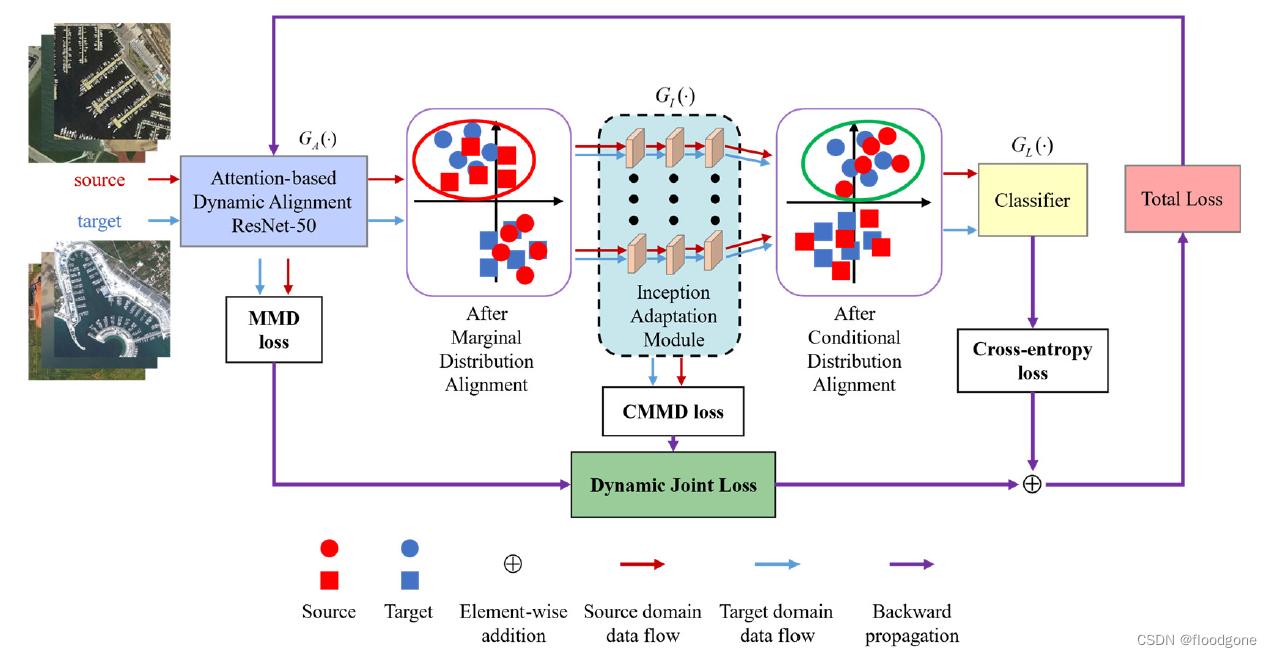
Framework中:
- ADA结构和IAM学习域不变特征和类鉴别体征,通过对齐边缘分布和条件分布最小化目标函数。
- DDF用来平衡边缘分布和条件分布的相对重要性。
5.1 基于注意力的动态对齐(ADA)
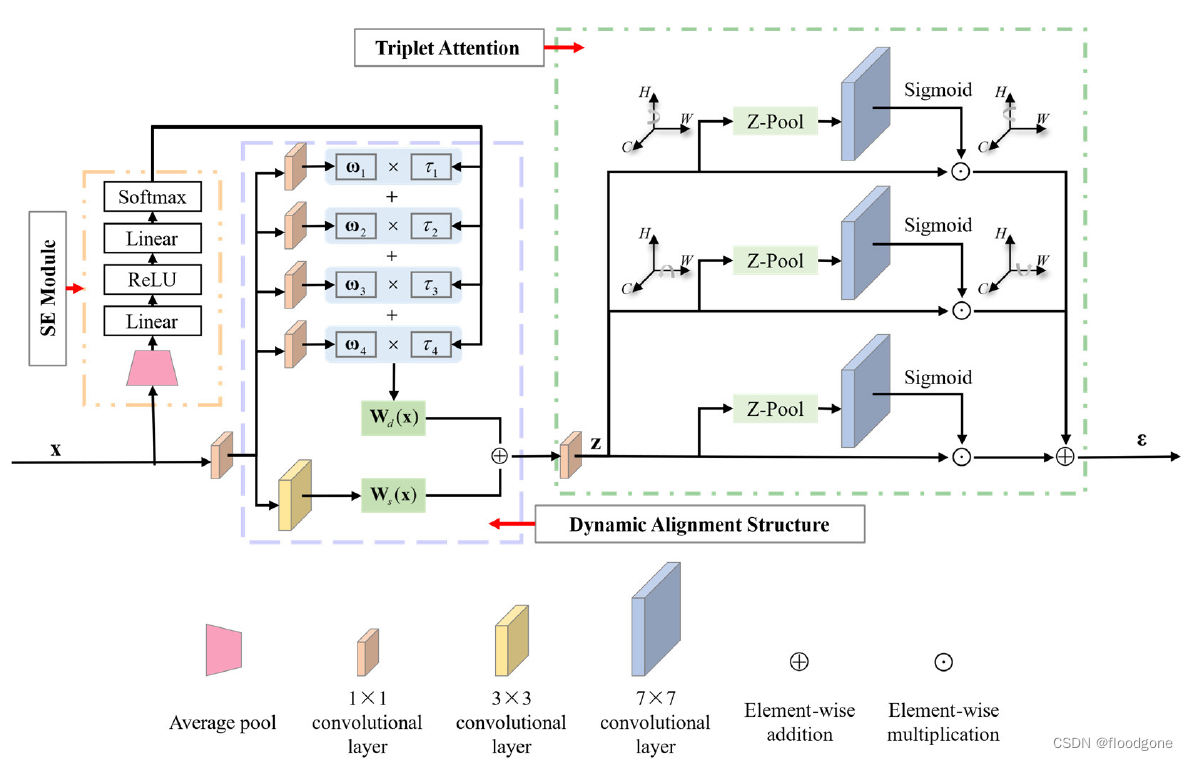
两个结构:动态对齐和注意力三联
动态对齐(Dynamic Alignment Structure)
网络的实现很简单,两个疑问:
- 4个动态权重矩阵都是通过SE模块出来的,所以权重不是一样的吗,该权重作用在4个相同的1×1卷积后的特征上,好像只实现了简单的特征累加。
- 文章中提到:“通过以输入依赖的方式选择这些投影,网络选择不同的特征子空间来引导不同的样本。”所以输入样本的重要性看上去更大一些。另外该结构的“对齐”好像并没有对齐源域和目标域数据的特征分布,所以是不是和数据分布中的“对齐”混淆?
注意力三联(Triplet Attention)
- 应该是直接引用triplet attention过来
- 该结构有三个并行的注意力分支构成,其中两个分支分别捕捉通道维和两个空间维之间的跨维相关性,剩余一个分支提取空间注意力特征。
- 通道维和其余两个维度交互的原理:premute的想保留的两个带交互的维度,然后分别做maxpool和avgpool
参考论文:Rotate to Attend: Convolutional Triplet Attention Module
# 代码实现,地址:https://github.com/LandskapeAI/triplet-attention
import torch
import torch.nn as nn
class BasicConv(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, stride=1, padding=0, dilation=1, groups=1, relu=True, bn=True, bias=False):
super(BasicConv, self).__init__()
self.out_channels = out_planes
self.conv = nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=bias)
self.bn = (
nn.BatchNorm2d(out_planes, eps=1e-5, momentum=0.01, affine=True)
if bn
else None
)
self.relu = nn.ReLU() if relu else None
def forward(self, x):
x = self.conv(x)
if self.bn is not None:
x = self.bn(x)
if self.relu is not None:
x = self.relu(x)
return x
class ZPool(nn.Module):
def forward(self, x):
return torch.cat(
(torch.max(x, 1)[0].unsqueeze(1), torch.mean(x, 1).unsqueeze(1)), dim=1
)
class AttentionGate(nn.Module):
def __init__(self):
super(AttentionGate, self).__init__()
kernel_size = 7
self.compress = ZPool()
self.conv = BasicConv(
2, 1, kernel_size, stride=1, padding=(kernel_size - 1) // 2, relu=False
)
def forward(self, x):
x_compress = self.compress(x)
x_out = self.conv(x_compress)
scale = torch.sigmoid_(x_out)
return x * scale
class TripletAttention(nn.Module):
def __init__(self, no_spatial=False):
super(TripletAttention, self).__init__()
self.cw = AttentionGate()
self.hc = AttentionGate()
self.no_spatial = no_spatial
if not no_spatial:
self.hw = AttentionGate()
def forward(self, x):
x_perm1 = x.permute(0, 2, 1, 3).contiguous()
x_out1 = self.cw(x_perm1)
x_out11 = x_out1.permute(0, 2, 1, 3).contiguous()
x_perm2 = x.permute(0, 3, 2, 1).contiguous()
x_out2 = self.hc(x_perm2)
x_out21 = x_out2.permute(0, 3, 2, 1).contiguous()
if not self.no_spatial:
x_out = self.hw(x)
x_out = 1 / 3 * (x_out + x_out11 + x_out21)
else:
x_out = 1 / 2 * (x_out11 + x_out21)
return
5.2 差异度量指标:MMD和CMMD
- MMD通过最小化源域数据和目标域数据的RKHS映射差异来对齐边缘分布
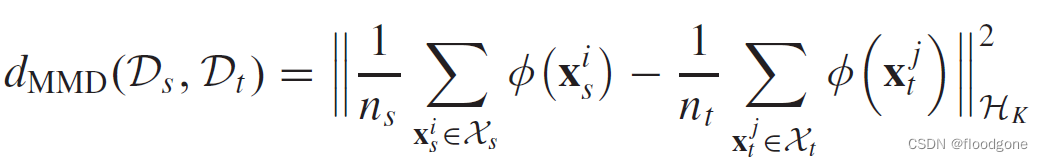
- CMMD中,由于目标域没有标签,所以目标域中的条件分布是很难估计的。可以通过对目标数据的预测作为伪标签老来计算后验概率分布
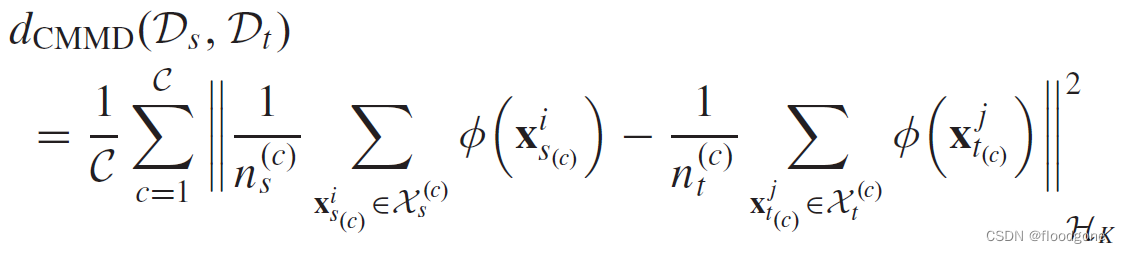
5.3 动态分布因子(DDF)
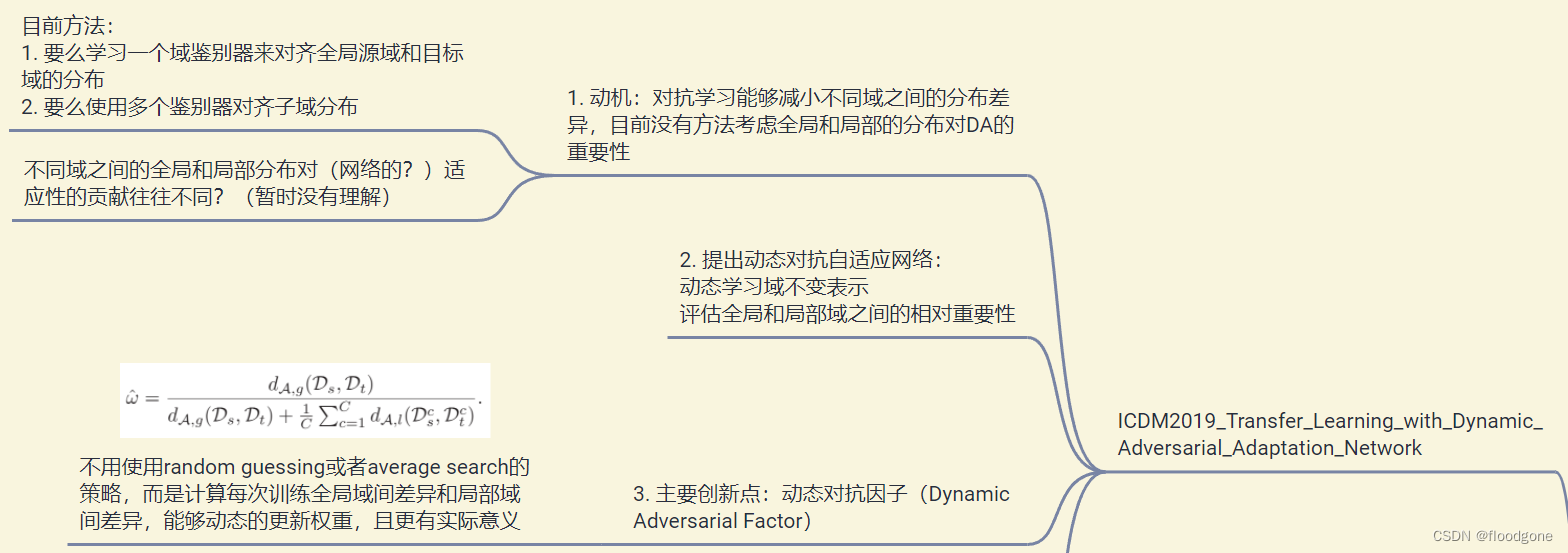
感觉和之前看过一篇19年ICDM上有关迁移学习的文章中提出的动态对抗因子想法一致,区别在于本片文章的作者并没有引用该文章,对文章的创新性还是大打折扣了。
评价
- 对注意力机制应用的包装:注意机制可以实现有目的的知识转移,从而使提取的特征具有高度的分辨力。
- 读前感觉很新颖,读后感觉文章创新型尚可吧。
- Conclusion部分提出了两个未来的方向,都比较笼统(减小样本数量对网络的影响+降低算法计算复杂度)。














 3885
3885











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









