







 本文介绍如何使用Python进行自然语言处理,包括从网络和硬盘获取文本、处理HTML、搜索引擎结果及本地文件,还详细讲解了使用正则表达式进行词组搭配检测、文本规范化和分词等操作。
本文介绍如何使用Python进行自然语言处理,包括从网络和硬盘获取文本、处理HTML、搜索引擎结果及本地文件,还详细讲解了使用正则表达式进行词组搭配检测、文本规范化和分词等操作。
本章原文链接:https://usyiyi.github.io/nlp-py-2e-zh/3.html
3 处理原始文本
import nltk, re, pprint
from nltk import word_tokenize
3.1 从网络和硬盘访问文本
1、从网络上下载文本
from urllib import request
url = "https://www.gutenberg.org/files/2554/2554-0.txt"
response = request.urlopen(url)
raw = response.read().decode("utf8")
print(type(raw),"\n", len(raw),"\n")
raw[:80]
<class 'str'>
1176967
'\ufeffThe Project Gutenberg EBook of Crime and Punishment, by Fyodor Dostoevsky\r\n\r\nTh'
2、分词
tokens = word_tokenize(raw)
print (type(tokens),"\n",len(tokens))
tokens[:15]
<class 'list'>
257727
['\ufeffThe',
'Project',
'Gutenberg',
'EBook',
'of',
'Crime',
'and',
'Punishment',
',',
'by',
'Fyodor',
'Dostoevsky',
'This',
'eBook',
'is']
3、从这个列表创建一个NLTK 文本
text = nltk.Text(tokens)
print(type(text),"\n")
print(text[1024:1062],"\n")
text.collocations() # 常用搭配
<class 'nltk.text.Text'>
['an', 'exceptionally', 'hot', 'evening', 'early', 'in', 'July', 'a', 'young', 'man', 'came', 'out', 'of', 'the', 'garret', 'in', 'which', 'he', 'lodged', 'in', 'S.', 'Place', 'and', 'walked', 'slowly', ',', 'as', 'though', 'in', 'hesitation', ',', 'towards', 'K.', 'bridge', '.', 'He', 'had', 'successfully']
Katerina Ivanovna; Pyotr Petrovitch; Pulcheria Alexandrovna; Avdotya
Romanovna; Rodion Romanovitch; Marfa Petrovna; Sofya Semyonovna; old
woman; Project Gutenberg-tm; Porfiry Petrovitch; Amalia Ivanovna;
great deal; young man; Nikodim Fomitch; Ilya Petrovitch; Project
Gutenberg; Andrey Semyonovitch; Hay Market; Dmitri Prokofitch; Good
heavens
4、手工检查文件以发现标记内容开始和结尾的独特的字符串
print(raw.find("PART I"),"\n")
print(raw.rfind("End of Project Gutenberg’s Crime")) # 注意,这里的 ’ 是中文符号下的 ‘
# 这里的raw.rfind() 是反向find的意思
5336
1157812
raw1 = raw[5336:1157812]
raw1.find("PART I")
raw1[:50]
'PART I\r\n\r\n\r\n\r\nCHAPTER I\r\n\r\nOn an exceptionally hot'
5、处理HTML
url = "http://news.bbc.co.uk/2/hi/health/2284783.stm"
html = request.urlopen(url).read().decode("utf8")
html[:60]
'<!doctype html public "-//W3C//DTD HTML 4.0 Transitional//EN'
from bs4 import BeautifulSoup
raw = BeautifulSoup(html).get_text()
tokens = word_tokenize(raw)
tokens
['BBC',
'NEWS',
'|',
'Health',
'|',
'Blondes',
"'to",
'die',
'out',
'in',
'200',
"years'",
'NEWS',
...]
tokens = tokens[110:390]
text = nltk.Text(tokens)
text.concordance('gene')
Displaying 5 of 5 matches:
hey say too few people now carry the gene for blondes to last beyond the next
blonde hair is caused by a recessive gene . In order for a child to have blond
have blonde hair , it must have the gene on both sides of the family in the g
ere is a disadvantage of having that gene or by chance . They do n't disappear
des would disappear is if having the gene was a disadvantage and I do not thin
6、处理搜索引擎的结果
import feedparser
llog = feedparser.parse("http://feed.cnblogs.com/blog/sitehome/rss")
llog
{'feed': {'title': '博客园_首页',
'title_detail': {'type': 'text/plain',
'language': None,
'base': 'http://feed.cnblogs.com/blog/sitehome/rss',
'value': '博客园_首页'},
'encoding': 'utf-8',
'version': 'atom10',
'namespaces': {'': 'http://www.w3.org/2005/Atom'}}
llog["feed"]["title"]
'博客园_首页'
len(llog.entries)
20
post = llog.entries[2]
post.title
'KnockOut 绑定之foreach绑定 - GavinJay'
content = post.content[0].value
content[:70]
'【摘要】foreach绑定对于数组中的每一个元素复制一节标记语言,也就是html,并且将这节标记语言和数组里面的每一个元素绑定。当我们呈现一'
raw = BeautifulSoup(content).get_text()
word_tokenize(raw)
['【摘要】foreach绑定对于数组中的每一个元素复制一节标记语言,也就是html,并且将这节标记语言和数组里面的每一个元素绑定。当我们呈现一组list数据,或者一个表格的时候,十分有用。',
'如果你绑定的数组是一个',
"''",
'监控数组',
"''",
',',
'observable',
'array',
',',
'(',
'和wpf里面的ObservableCollec',
'阅读全文']
7、读取本地文件
f = open("3.document.txt",'r') # 'r'意味着以只读方式打开文件(默认),'U'表示“通用”,它让我们忽略不同的换行约定。
raw = f.read()
raw
' 沁园春·雪\n作者:毛泽东\n北国风光,千里冰封,万里雪飘。\n望长城内外,惟余莽莽;大河上下,顿失滔滔。\n山舞银蛇,原驰蜡象,欲与天公试比高。\n须晴日,看红装素裹,分外妖娆。\n江山如此多娇,引无数英雄竞折腰。\n惜秦皇汉武,略输文采;唐宗宋祖,稍逊风骚。 '
import os
os.listdir(".")
['picture',
'【Python自然语言处理】读书笔记:第一章:语言处理与Python.md~',
'README.md',
'.git',
'【Python自然语言处理】读书笔记:第三章:处理原始文本.ipynb',
'.ipynb_checkpoints',
'【Python自然语言处理】读书笔记:第二章:获得文本语料和词汇资源.md',
'3.document.txt',
'【Python自然语言处理】读书笔记:第一章:语言处理与Python.md',
'【Python自然语言处理】读书笔记:第二章:获得文本语料和词汇资源.md~']
f = open("3.document.txt","r")
for line in f:
print(line.strip()) # strip()方法删除输入行结尾的换行符。
沁园春·雪
作者:毛泽东
北国风光,千里冰封,万里雪飘。
望长城内外,惟余莽莽;大河上下,顿失滔滔。
山舞银蛇,原驰蜡象,欲与天公试比高。
须晴日,看红装素裹,分外妖娆。
江山如此多娇,引无数英雄竞折腰。
惜秦皇汉武,略输文采;唐宗宋祖,稍逊风骚。
8、从PDF、MS Word 及其他二进制格式中提取文本
文字常常以二进制格式出现,如PDF 和MSWord,只能使用专门的软件打开。第三方函数库如pypdf和pywin32提供了对这些格式的访问。
9、NLP 的流程

10、str
>>> a = [1, 2, 3, 4, 5, 6, 7, 6, 5, 4, 3, 2, 1]
>>> b = [' ' * 2 * (7 - i) + 'very' * i for i in a]
>>> for line in b:
... print(line)
very
veryvery
veryveryvery
veryveryveryvery
veryveryveryveryvery
veryveryveryveryveryvery
veryveryveryveryveryveryvery
veryveryveryveryveryvery
veryveryveryveryvery
veryveryveryvery
veryveryvery
veryvery
very
help(str)
Help on class str in module builtins:
class str(object)
| str(object='') -> str
| str(bytes_or_buffer[, encoding[, errors]]) -> str
|
| Create a new string object from the given object. If encoding or
| errors is specified, then the object must expose a data buffer
| that will be decoded using the given encoding and error handler.
| Otherwise, returns the result of object.__str__() (if defined)
| or repr(object).
| encoding defaults to sys.getdefaultencoding().
| errors defaults to 'strict'.
|
| Methods defined here:
|
| __add__(self, value, /)
| Return self+value.
| must be a string, whose characters will be mapped to None in the result.
列表中的元素可以很大也可以很小,只要我们喜欢:例如,它们可能是段落、句子、短语、单词、字符。
因此,我们在一段NLP 代码中可能做的第一件事情就是将一个字符串分词放入一个字符串列表中。
相反,当我们要将结果写入到一个文件或终端,我们通常会将它们格式化为一个字符串。
3.4 使用正则表达式检测词组搭配
import re
wordlist = [w for w in nltk.corpus.words.words("en") if w.islower()]
wordlist
['a',
'aa',
'aal',
'aalii',
'aam',
'unsubjectlike']
sum(1 for w in wordlist if re.search("^e-?mail$", w)) # ? 匹配前边的字符0次或1次 # 这行代码的意思是统计总共由多少email或e-mail
0
2、范围与闭包
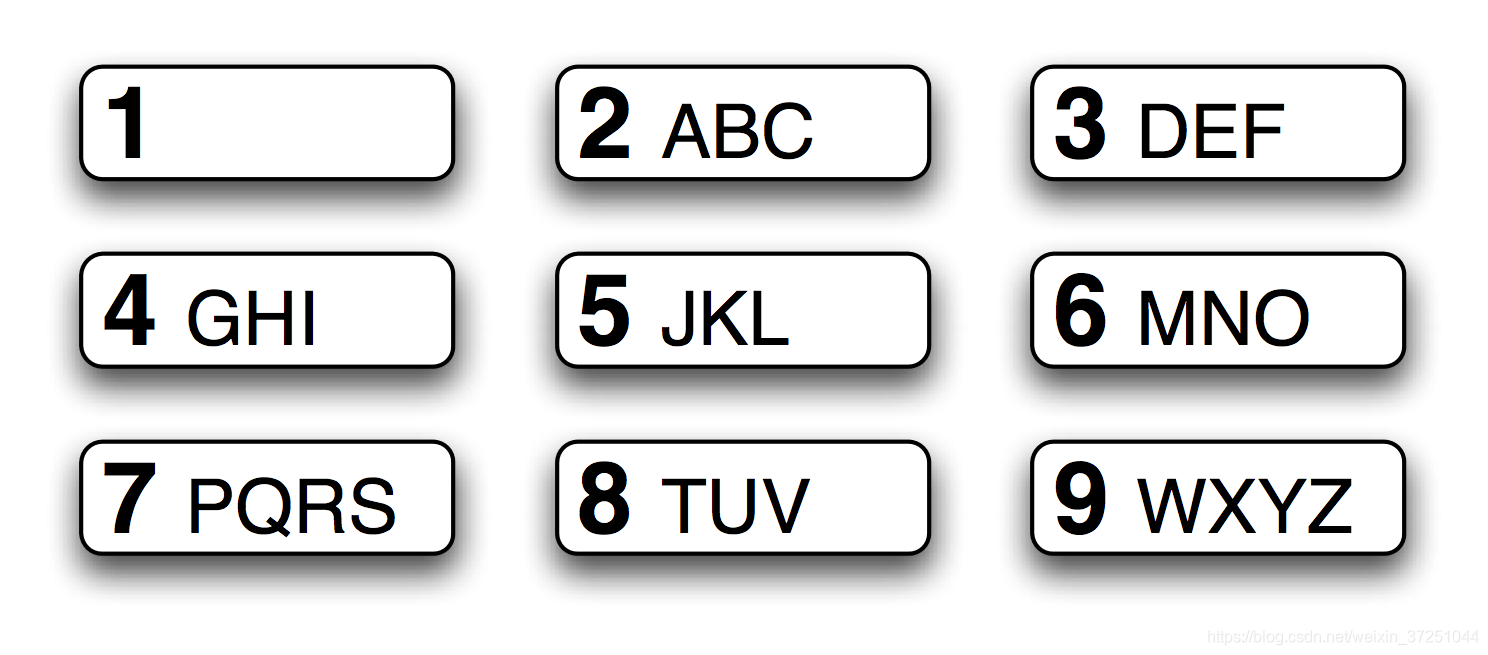
# 通过序列4653输入。有哪些其它词汇由相同的序列产生?
[w for w in wordlist if re.search("^[ghi][mno][jkl][def]$", w)]
['gold', 'golf', 'hold', 'hole']
# 匹配只使用中间行的4、5、6 键的词汇
[w for w in wordlist if re.search("^[g-o]+$", w)] # - 表示范围 + 表示匹配1次或多次
['g',
'ghoom',
'gig',
'giggling',
'onlook',
'onlooking',
'oolong']
chat_words = sorted(set(w for w in nltk.corpus.nps_chat.words()))
[w for w in chat_words if re.search("^m+i+n+e+$", w)] # + 表示匹配1次或多次
['miiiiiiiiiiiiinnnnnnnnnnneeeeeeeeee',
'miiiiiinnnnnnnnnneeeeeeee',
'mine',
'mmmmmmmmiiiiiiiiinnnnnnnnneeeeeeee']
[w for w in chat_words if re.search("^m*i*n*e*$", w)] # * 表示匹配0次或多次
['',
'e',
'i',
'in',
'm',
'me',
'meeeeeeeeeeeee',
'mi',
'miiiiiiiiiiiiinnnnnnnnnnneeeeeeeeee',
'miiiiiinnnnnnnnnneeeeeeee',
'min',
'mine',
'mm',
'mmm',
'mmmm',
'mmmmm',
'mmmmmm',
'mmmmmmmmiiiiiiiiinnnnnnnnneeeeeeee',
'mmmmmmmmmm',
'mmmmmmmmmmmmm',
'mmmmmmmmmmmmmm',
'n',
'ne']
[w for w in chat_words if re.search("^[ha]+$", w)] # [ ] 匹配集合里边的没有顺序
['a',
'aaaaaaaaaaaaaaaaa',
'aaahhhh',
'ah',
'ahah',
'ahahah',
'ahh',
'ahhahahaha',
'ahhh',
'ahhhh',
'ahhhhhh',
'ahhhhhhhhhhhhhh',
'h',
'ha',
'haaa',
'hah',
'haha',
'hahaaa',
'hahah',
'hahaha',
'hahahaa',
'hahahah',
'hahahaha',
'hahahahaaa',
'hahahahahaha',
'hahahahahahaha',
'hahahahahahahahahahahahahahahaha',
'hahahhahah',
'hahhahahaha']
wsj = sorted(set(nltk.corpus.treebank.words()))
[w for w in wsj if re.search("^[0-9]+\.[0-9]+$", w)] # \. 表示后边的字符.不在具有转义含义而是字面的表示 .
['0.0085',
'0.05',
'0.1',
'2029',
'3057',
'8300']
[w for w in wsj if re.search("^[0-9]+-[a-z]{3,5}$", w)] # 中间的 - 表示字符本身, {3,5} 表示匹配前边的字符或组合3次或5次
['10-day',
'10-lap',
'10-year',
'84-month',
'87-store',
'90-day']
[w for w in wsj if re.search("^[a-z]{5,}-[a-z]{2,3}-[a-z]{,6}$", w)] # {5,} 表示匹配前边的字符或组合5次或5次以上 {,6} 表示匹配前边的字符或组合6次或6次以下
['black-and-white',
'bread-and-butter',
'father-in-law',
'machine-gun-toting',
'savings-and-loan']
[w for w in wsj if re.search("(ed|ing)$", w)] # (ed|ing) 表示匹配已组合ed或者ing结尾的单词
['62%-owned',
'Absorbed',
'According',
'Adopting',
'Advanced',
'Advancing',
'licensed',
'licensing',
'lifted',
...]
for i in [w for w in wsj if re.search("ed|ing$", w)]: # 不加() 只要遇到ed就匹配截止
if i not in [w for w in wsj if re.search("(ed|ing)$", w)]:
print (i)
Biedermann
Breeden
Cathedral
staff-reduction
succeeds
supposedly
weddings
[w for w in wsj if re.search("w(i|e|ai|oo)t", w)] # 匹配含有wit,wet,wait,woot
['Hymowitz',
'Switzerland',
'awaits',
'withhold',
'within',
'without',
'withstand',
'witness',
'witnesses']
word = "supercalifragilisticexpialidocious"
re.findall(r"[aeiou]", word)
['u',
'e',
'a',
'i',
'a',
'i',
'i',
'i',
'e',
'i',
'a',
'i',
'o',
'i',
'o',
'u']
# 看看一些文本中的两个或两个以上的元音序列,并确定它们的相对频率:
wsj = sorted(set(nltk.corpus.treebank.words()))
fd = nltk.FreqDist(vs for vs in re.findall(r"[aeiou]{2,}", word) for word in wsj)
fd.most_common(12)
[('ia', 12408), ('iou', 12408)]
>>> wsj = sorted(set(nltk.corpus.treebank.words()))
>>> fd = nltk.FreqDist(vs for word in wsj for vs in re.findall(r'[aeiou]{2,}', word))
>>> fd.most_common(12)
[('io', 549),
('ea', 476),
('ie', 331),
('ou', 329),
('ai', 261),
('ia', 253),
('ee', 217),
('oo', 174),
('ua', 109),
('au', 106),
('ue', 105),
('ui', 95)]
[vs for word in wsj for vs in re.findall(r'[aeiou]{2,}', word)] # 疑问:for word in wsj 放在前边和放在后边为啥不一样?
['ea',
'oi',
'ea',
'ou',
'oi',
'ea',
'au',
...]
[vs for vs in re.findall(r'[aeiou]{2,}', word) for word in wsj] # 疑问:for word in wsj 放在前边和放在后边为啥不一样?
['ia',
'ia',
'ia',
'ia',
'ia',
'ia',
'ia',
...]
import re
[int(n) for n in re.findall("[0-9]{2,}", '2009-12-31')]
[2009, 12, 31]
3、忽略掉词内部的元音
英文文本是高度冗余的,忽略掉词内部的元音仍然可以很容易的阅读,有些时候这很明显。例如,declaration变成dclrtn,inalienable变成inlnble,保留所有词首或词尾的元音序列。在我们的下一个例子中,正则表达式匹配词首元音序列,词尾元音序列和所有的辅音;其它的被忽略。
regexp = r"^[AEIOUaeiou]+|[AEIOUaeiou]+$|[^AEIOUaeiou]"
def compress(word):
pieces = re.findall(regexp, word)
return "".join(pieces)
english_udhr = nltk.corpus.udhr.words("English-Latin1")
print(english_udhr[:75],"\n")
print(nltk.tokenwrap(compress(w) for w in english_udhr[:75]))
['Universal', 'Declaration', 'of', 'Human', 'Rights', 'Preamble', 'Whereas', 'recognition', 'of', 'the', 'inherent', 'dignity', 'and', 'of', 'the', 'equal', 'and', 'inalienable', 'rights', 'of', 'all', 'members', 'of', 'the', 'human', 'family', 'is', 'the', 'foundation', 'of', 'freedom', ',', 'justice', 'and', 'peace', 'in', 'the', 'world', ',', 'Whereas', 'disregard', 'and', 'contempt', 'for', 'human', 'rights', 'have', 'resulted', 'in', 'barbarous', 'acts', 'which', 'have', 'outraged', 'the', 'conscience', 'of', 'mankind', ',', 'and', 'the', 'advent', 'of', 'a', 'world', 'in', 'which', 'human', 'beings', 'shall', 'enjoy', 'freedom', 'of', 'speech', 'and']
Unvrsl Dclrtn of Hmn Rghts Prmble Whrs rcgntn of the inhrnt dgnty and
of the eql and inlnble rghts of all mmbrs of the hmn fmly is the fndtn
of frdm , jstce and pce in the wrld , Whrs dsrgrd and cntmpt fr hmn
rghts hve rsltd in brbrs acts whch hve outrgd the cnscnce of mnknd ,
and the advnt of a wrld in whch hmn bngs shll enjy frdm of spch and
4、将正则表达式与条件频率分布结合起来
在这里,我们将从罗托卡特语词汇中提取所有辅音-元音序列,如ka和si。因为每部分都是成对的,它可以被用来初始化一个条件频率分布。然后我们为每对的频率画出表格:
rotokas_words = nltk.corpus.toolbox.words("rotokas.dic")
cvs = [cv for w in rotokas_words for cv in re.findall(r"[ptksvr][aeiou]", w)]
print (cvs[:10])
['ka', 'ka', 'ka', 'ka', 'ka', 'ro', 'ka', 'ka', 'vi', 'ko']
cfd = nltk.ConditionalFreqDist(cvs)
cfd.tabulate()
a e i o u
k 418 148 94 420 173
p 83 31 105 34 51
r 187 63 84 89 79
s 0 0 100 2 1
t 47 8 0 148 37
v 93 27 105 48 49
5、辅音-元音对的单词的列表
cv_word_pairs = [(cv, w) for w in rotokas_words for cv in re.findall(r"[ptksvr][aeiou]", w)]
cv_index = nltk.Index(cv_word_pairs)
print(cv_index["su"],"\n\n",cv_index["po"])
['kasuari']
['kaapo', 'kaapopato', 'kaipori', 'kaiporipie', 'kaiporivira', 'kapo', 'kapoa', 'kapokao', 'kapokapo', 'kapokapo', 'kapokapoa', 'kapokapoa', 'kapokapora', 'kapokapora', 'kapokaporo', 'kapokaporo', 'kapokari', 'kapokarito', 'kapokoa', 'kapoo', 'kapooto', 'kapoovira', 'kapopaa', 'kaporo', 'kaporo', 'kaporopa', 'kaporoto', 'kapoto', 'karokaropo', 'karopo', 'kepo', 'kepoi', 'keposi', 'kepoto']
这段代码依次处理每个词w,对每一个词找出匹配正则表达式«[ptksvr][aeiou]»的所有子字符串。对于词kasuari,它找到ka, su和ri。因此,cv_word_pairs将包含(‘ka’, ‘kasuari’), (‘su’, ‘kasuari’)和(‘ri’, ‘kasuari’)。更进一步使用nltk.Index()转换成有用的索引。
6、查找词干
def stem(word):
for suffix in ['ing', 'ly', 'ed', 'ious', 'ies', 'ive', 'es', 's', 'ment']:
if word.endswith(suffix):
return word[:-len(suffix)]
return word
re.findall(r"^.*(ing|ly|ed|ious|ies|ive|es|s|ment)$", "processing")
['ing']
re.findall(r"^.*(?:ing|ly|ed|ious|ies|ive|es|s|ment)$", "processing") # (?:) 表示返回匹配到的字符串,而不是匹配到的部分片段
['processing']
re.findall(r"^(.*)(ing|ly|ed|ious|ies|ive|es|s|ment)$", "processing") # (.*) 表示两个部分分别提取出来
[('process', 'ing')]
re.findall(r'^(.*)(ing|ly|ed|ious|ies|ive|es|s|ment)$', 'processes') # (.*) 表示贪婪提取
[('processe', 's')]
re.findall(r"^(.*?)(ing|ly|ed|ious|ies|ive|es|s|ment)$", "processing") # (.*?) 添加一个 *? 号表示非贪婪提取
[('process', 'ing')]
re.findall(r'^(.*?)(ing|ly|ed|ious|ies|ive|es|s|ment)?$', 'language') # 后边添加?表示可选提取
[('language', '')]
def stem2(word):
regexp = r'^(.*?)(ing|ly|ed|ious|ies|ive|es|s|ment)?$'
stem, suffix = re.findall(regexp, word)[0]
return stem
raw = """DENNIS: Listen, strange women lying in ponds distributing swords
is no basis for a system of government. Supreme executive power derives from
a mandate from the masses, not from some farcical aquatic ceremony."""
tokens = word_tokenize(raw)
print([stem(t) for t in tokens],"\n\n",[stem2(t) for t in tokens])
['DENNIS', ':', 'Listen', ',', 'strange', 'women', 'ly', 'in', 'pond', 'distribut', 'sword', 'i', 'no', 'basi', 'for', 'a', 'system', 'of', 'govern', '.', 'Supreme', 'execut', 'power', 'deriv', 'from', 'a', 'mandate', 'from', 'the', 'mass', ',', 'not', 'from', 'some', 'farcical', 'aquatic', 'ceremony', '.']
['DENNIS', ':', 'Listen', ',', 'strange', 'women', 'ly', 'in', 'pond', 'distribut', 'sword', 'i', 'no', 'basi', 'for', 'a', 'system', 'of', 'govern', '.', 'Supreme', 'execut', 'power', 'deriv', 'from', 'a', 'mandate', 'from', 'the', 'mass', ',', 'not', 'from', 'some', 'farcical', 'aquatic', 'ceremony', '.']
7、使用nltk.findall搜索已分词文本
你可以使用一种特殊的正则表达式搜索一个文本中多个词(这里的文本是一个词符列表)。例如," " 找出文本中所有a man的实例。
尖括号用于标记词符的边界,尖括号之间的所有空白都被忽略(这只对NLTK中的findall()方法处理文本有效)。
在下面的例子中,我们使用<.*>[1],它将匹配所有单个词符,将它括在括号里,于是只匹配词(例如monied)而不匹配短语(例如,a monied man)会生成。
第二个例子找出以词bro结尾的三个词组成的短语[2]。
最后一个例子找出以字母l开始的三个或更多词组成的序列[3]。
from nltk.corpus import gutenberg, nps_chat
moby = nltk.Text(gutenberg.words("melville-moby_dick.txt"))
print(moby[:10],"\n")
print(moby.findall(r"<a><.*><man>"),"\n")
print(moby.findall(r"<a>(<.*>)<man>"))
['[', 'Moby', 'Dick', 'by', 'Herman', 'Melville', '1851', ']', 'ETYMOLOGY', '.']
a monied man; a nervous man; a dangerous man; a white man; a white
man; a white man; a pious man; a queer man; a good man; a mature man;
a white man; a Cape man; a great man; a wise man; a wise man; a
butterless man; a white man; a fiendish man; a pale man; a furious
man; a better man; a certain man; a complete man; a dismasted man; a
younger man; a brave man; a brave man; a brave man; a brave man
None
monied; nervous; dangerous; white; white; white; pious; queer; good;
mature; white; Cape; great; wise; wise; butterless; white; fiendish;
pale; furious; better; certain; complete; dismasted; younger; brave;
brave; brave; brave
None
chat = nltk.Text(nps_chat.words())
print(chat[:10],"\n")
chat.findall(r"<.*><.*><bro>")
['now', 'im', 'left', 'with', 'this', 'gay', 'name', ':P', 'PART', 'hey']
you rule bro; telling you bro; u twizted bro
chat.findall(r"<l.*>{3,}")
lol lol lol; lmao lol lol; lol lol lol; la la la la la; la la la; la
la la; lovely lol lol love; lol lol lol.; la la la; la la la
p=r'[a-zA-Z]+'
nltk.re_show(p,'123asd456')
123{asd}456
8、在大型文本语料库中搜索x and other ys形式的表达式
from nltk.corpus import brown
hobbies_learned = nltk.Text(brown.words(categories = ["hobbies", "learned"]))
hobbies_learned.findall(r"<\w*><and><other><\w*s>")
speed and other activities; water and other liquids; tomb and other
landmarks; Statues and other monuments; pearls and other jewels;
charts and other items; roads and other features; figures and other
objects; military and other areas; demands and other factors;
abstracts and other compilations; iron and other metals
hobbies_learned.findall(r"<as><\w*><as><\w*>")
as accurately as possible; as well as the; as faithfully as possible;
as much as what; as neat as a; as simple as you; as well as other; as
well as other; as involved as determining; as well as other; as
important as another; as accurately as possible; as accurate as any;
as much as any; as different as a; as Orphic as that; as coppery as
Delawares; as good as another; as large as small; as well as ease;
Persian; as long as those; as importantly as his; as well as
providing; as well as the; as well as vertically; as well as new; as
well as certain; as well as the; as close as possible; as far as
obtainable; as well as the; as important as the; as long as the; as
satisfactory as those
3.6 规范化文本
raw = """DENNIS: Listen, strange women lying in ponds distributing swords
... is no basis for a system of government. Supreme executive power derives from
... a mandate from the masses, not from some farcical aquatic ceremony."""
tokens = word_tokenize(raw)
print(tokens)
['DENNIS', ':', 'Listen', ',', 'strange', 'women', 'lying', 'in', 'ponds', 'distributing', 'swords', 'is', 'no', 'basis', 'for', 'a', 'system', 'of', 'government', '.', 'Supreme', 'executive', 'power', 'derives', 'from', 'a', 'mandate', 'from', 'the', 'masses', ',', 'not', 'from', 'some', 'farcical', 'aquatic', 'ceremony', '.']
1、词干提取器
看Porter词干提取器正确处理了词lying(将它映射为lie),而Lancaster词干提取器并没有处理好。
porter = nltk.PorterStemmer()
print([porter.stem(t) for t in tokens])
['denni', ':', 'listen', ',', 'strang', 'women', 'lie', 'in', 'pond', 'distribut', 'sword', 'is', 'no', 'basi', 'for', 'a', 'system', 'of', 'govern', '.', 'suprem', 'execut', 'power', 'deriv', 'from', 'a', 'mandat', 'from', 'the', 'mass', ',', 'not', 'from', 'some', 'farcic', 'aquat', 'ceremoni', '.']
lancaster = nltk.LancasterStemmer()
print([lancaster.stem(t) for t in tokens])
['den', ':', 'list', ',', 'strange', 'wom', 'lying', 'in', 'pond', 'distribut', 'sword', 'is', 'no', 'bas', 'for', 'a', 'system', 'of', 'govern', '.', 'suprem', 'execut', 'pow', 'der', 'from', 'a', 'mand', 'from', 'the', 'mass', ',', 'not', 'from', 'som', 'farc', 'aqu', 'ceremony', '.']
2、词形归并
WordNet词形归并器只在产生的词在它的词典中时才删除词缀。这个额外的检查过程使词形归并器比刚才提到的词干提取器要慢。请注意,它并没有处理lying,但它将women转换为woman。
wnl = nltk.WordNetLemmatizer()
print([wnl.lemmatize(t) for t in tokens])
['DENNIS', ':', 'Listen', ',', 'strange', 'woman', 'lying', 'in', 'pond', 'distributing', 'sword', 'is', 'no', 'basis', 'for', 'a', 'system', 'of', 'government', '.', 'Supreme', 'executive', 'power', 'derives', 'from', 'a', 'mandate', 'from', 'the', 'mass', ',', 'not', 'from', 'some', 'farcical', 'aquatic', 'ceremony', '.']
3.7 用正则表达式为文本分词
1、分词的简单方法
raw = """'When I'M a Duchess,' she said to herself, (not in a very hopeful tone
though), 'I won't have any pepper in my kitchen AT ALL. Soup does very
well without--Maybe it's always pepper that makes people hot-tempered,'..."""
print(re.split(r" ", raw)) # 在 空格字符 处分割原始文本
["'When", "I'M", 'a', "Duchess,'", 'she', 'said', 'to', 'herself,', '(not', 'in', 'a', 'very', 'hopeful', 'tone\nthough),', "'I", "won't", 'have', 'any', 'pepper', 'in', 'my', 'kitchen', 'AT', 'ALL.', 'Soup', 'does', 'very\nwell', 'without--Maybe', "it's", 'always', 'pepper', 'that', 'makes', 'people', "hot-tempered,'..."]
print(re.split(r"[ \t\n]+",raw)) # 在 空格 或 制表符(\t) 或 换行符(\n) 处分割原始文本
["'When", "I'M", 'a', "Duchess,'", 'she', 'said', 'to', 'herself,', '(not', 'in', 'a', 'very', 'hopeful', 'tone', 'though),', "'I", "won't", 'have', 'any', 'pepper', 'in', 'my', 'kitchen', 'AT', 'ALL.', 'Soup', 'does', 'very', 'well', 'without--Maybe', "it's", 'always', 'pepper', 'that', 'makes', 'people', "hot-tempered,'..."]
print(re.split(r"\s+", raw)) # 在 所有空白字符 处分割原始文本
["'When", "I'M", 'a', "Duchess,'", 'she', 'said', 'to', 'herself,', '(not', 'in', 'a', 'very', 'hopeful', 'tone', 'though),', "'I", "won't", 'have', 'any', 'pepper', 'in', 'my', 'kitchen', 'AT', 'ALL.', 'Soup', 'does', 'very', 'well', 'without--Maybe', "it's", 'always', 'pepper', 'that', 'makes', 'people', "hot-tempered,'..."]
print(re.split(r"\W+", raw)) # 在 \w 的补集处分割原始文本 ; \w 表示匹配所有字符,相当于[a-zA-Z0-9_] ; \W 表示 \w 的补集,即所有字母数字下划线以外的字符
['', 'When', 'I', 'M', 'a', 'Duchess', 'she', 'said', 'to', 'herself', 'not', 'in', 'a', 'very', 'hopeful', 'tone', 'though', 'I', 'won', 't', 'have', 'any', 'pepper', 'in', 'my', 'kitchen', 'AT', 'ALL', 'Soup', 'does', 'very', 'well', 'without', 'Maybe', 'it', 's', 'always', 'pepper', 'that', 'makes', 'people', 'hot', 'tempered', '']
print(re.findall(r"\w+|\S\w*", raw)) # 首先匹配字母数字下划线,如果没有则匹配非空白字符(\S 是\s 的补集)加上字母数字下划线
["'When", 'I', "'M", 'a', 'Duchess', ',', "'", 'she', 'said', 'to', 'herself', ',', '(not', 'in', 'a', 'very', 'hopeful', 'tone', 'though', ')', ',', "'I", 'won', "'t", 'have', 'any', 'pepper', 'in', 'my', 'kitchen', 'AT', 'ALL', '.', 'Soup', 'does', 'very', 'well', 'without', '-', '-Maybe', 'it', "'s", 'always', 'pepper', 'that', 'makes', 'people', 'hot', '-tempered', ',', "'", '.', '.', '.']
print(re.findall(r"\w+(?:[-']\w+)*|'|[-.(]+|\S\w*", raw)) # \w+(?:[-']\w+)* 会匹配 hot-tempered和it's
["'", 'When', "I'M", 'a', 'Duchess', ',', "'", 'she', 'said', 'to', 'herself', ',', '(', 'not', 'in', 'a', 'very', 'hopeful', 'tone', 'though', ')', ',', "'", 'I', "won't", 'have', 'any', 'pepper', 'in', 'my', 'kitchen', 'AT', 'ALL', '.', 'Soup', 'does', 'very', 'well', 'without', '--', 'Maybe', "it's", 'always', 'pepper', 'that', 'makes', 'people', 'hot-tempered', ',', "'", '...']
2、nltk自带的正则匹配
3.8 分割
1、断句
len(nltk.corpus.brown.words()) / len(nltk.corpus.brown.sents()) # 计算布朗语料库中每个句子的平均词数
20.250994070456922
# 使用nltk自带的Punkt句子分割器为一篇小说文本断句
text = nltk.corpus.gutenberg.raw("chesterton-thursday.txt")
sents = nltk.sent_tokenize(text)
pprint.pprint(sents[79:89]) # pprint()模块打印出来的数据结构更加完整,每行为一个数据结构,更加方便阅读打印输出结果
['"Nonsense!"',
'said Gregory, who was very rational when anyone else\nattempted paradox.',
'"Why do all the clerks and navvies in the\n'
'railway trains look so sad and tired, so very sad and tired?',
'I will\ntell you.',
'It is because they know that the train is going right.',
'It\n'
'is because they know that whatever place they have taken a ticket\n'
'for that place they will reach.',
'It is because after they have\n'
'passed Sloane Square they know that the next station must be\n'
'Victoria, and nothing but Victoria.',
'Oh, their wild rapture!',
'oh,\n'
'their eyes like stars and their souls again in Eden, if the next\n'
'station were unaccountably Baker Street!"',
'"It is you who are unpoetical," replied the poet Syme.']
2、分词
类似的问题在口语语言处理中也会出现,听者必须将连续的语音流分割成单个的词汇。
>>> text = "doyouseethekittyseethedoggydoyoulikethekittylikethedoggy"
>>> seg1 = "0000000000000001000000000010000000000000000100000000000"
>>> seg2 = "0100100100100001001001000010100100010010000100010010000"
seg3 = "0000100100000011001000000110000100010000001100010000001"
def segment(text, segs):
words = []
last = 0
for i in range(len(segs)):
if segs[i] == "1":
words.append(text[last:i+1])
last = i + 1
words.append(text[last:])
return words
print(segment(text,seg1))
print(segment(text,seg2))
print(segment(text,seg3))
['doyouseethekitty', 'seethedoggy', 'doyoulikethekitty', 'likethedoggy']
['do', 'you', 'see', 'the', 'kitty', 'see', 'the', 'doggy', 'do', 'you', 'like', 'the', 'kitty', 'like', 'the', 'doggy']
['doyou', 'see', 'thekitt', 'y', 'see', 'thedogg', 'y', 'doyou', 'like', 'thekitt', 'y', 'like', 'thedogg', 'y']
计算目标函数:给定一个假设的源文本的分词(左),推导出一个词典和推导表,它能让源文本重构,然后合计每个词项(包括边界标志)与推导表的字符数,作为分词质量的得分;得分值越小表明分词越好。
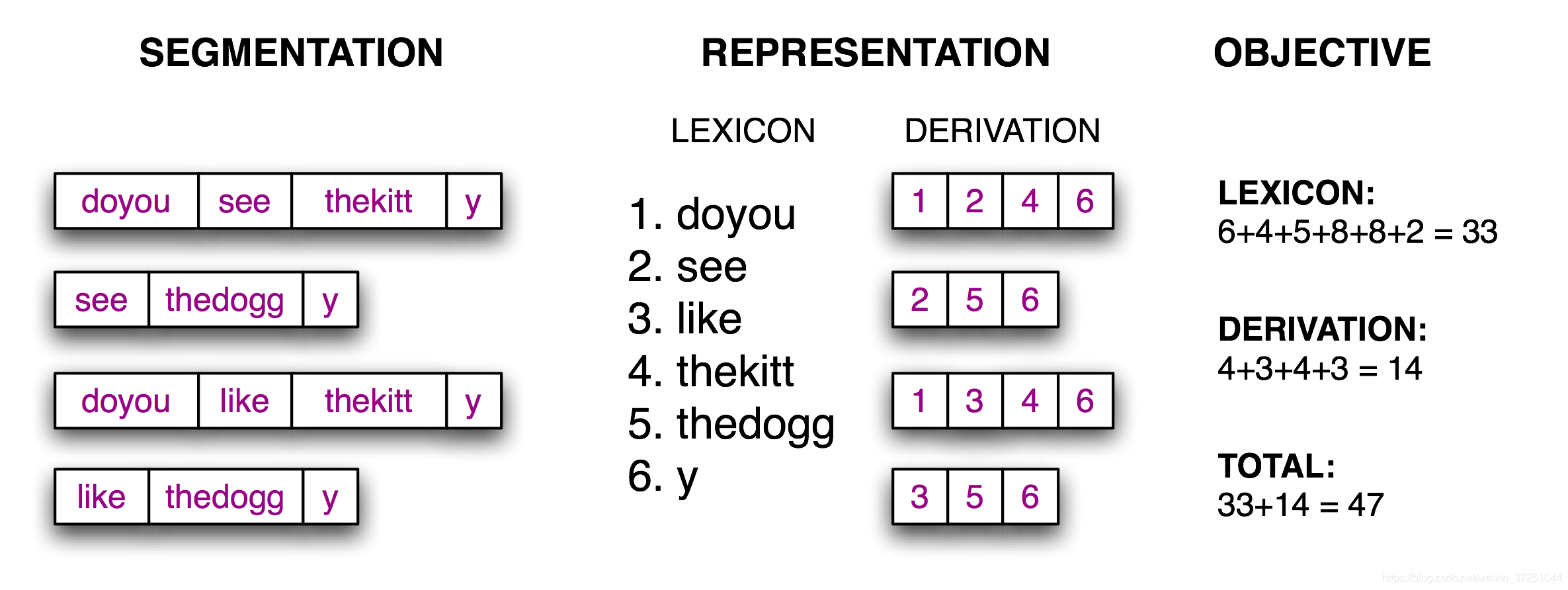
def evaluate(text, segs):
words = segment(text, segs)
text_size = len(words)
lexicon_size = sum(len(word) + 1 for word in set(words))
return text_size + lexicon_size
print(evaluate(text, seg1))
print(evaluate(text, seg2))
print(evaluate(text, seg3))
64
48
47
例 3-4. 使用模拟退火算法的非确定性搜索:一开始仅搜索短语分词;随机扰动 0 和 1,
它们与“温度”成比例;每次迭代温度都会降低,扰动边界会减少。
from random import randint
def flip(segs, pos):
return segs[:pos] + str(1-int(segs[pos])) + segs[pos+1:] # 将segs中pos位置的数字翻转:1变0 ; 0变1
def flip_n(segs, n):
for i in range(n):
segs = flip(segs, randint(0,len(segs)-1)) # 随机翻转segs中的0或者1 n次
return segs
def anneal(text, segs, iterations, cooling_rate):
temperature = float(len(segs))
while temperature > 0.5:
best_segs, best = segs, evaluate(text, segs)
for i in range(iterations):
guess = flip_n(segs, int(round(temperature))) # round 返回浮点数的四舍五入
score = evaluate(text, guess)
if score < best:
best, best_segs = score, guess
score, segs = best, best_segs
temperature = temperature / cooling_rate
print (evaluate(text, segs), segment(text, segs))
print
return segs
text = "doyouseethekittyseethedoggydoyoulikethekittylikethedoggy"
seg1 = "0000000000000001000000000010000000000000000100000000000"
anneal(text, seg1, 5000, 1.2)
64 ['doyouseethekitty', 'seethedoggy', 'doyoulikethekitty', 'likethedoggy']
64 ['doyouseethekitty', 'seethedoggy', 'doyoulikethekitty', 'likethedoggy']
64 ['doyouseethekitty', 'seethedoggy', 'doyoulikethekitty', 'likethedoggy']
64 ['doyouseethekitty', 'seethedoggy', 'doyoulikethekitty', 'likethedoggy']
64 ['doyouseethekitty', 'seethedoggy', 'doyoulikethekitty', 'likethedoggy']
63 ['do', 'y', 'ousee', 'thekitt', 'y', 'see', 'thedoggy', 'doy', 'oulike', 'thekitt', 'y', 'li', 'ke', 'thedoggy']
63 ['do', 'y', 'ousee', 'thekitt', 'y', 'see', 'thedoggy', 'doy', 'oulike', 'thekitt', 'y', 'li', 'ke', 'thedoggy']
63 ['do', 'y', 'ousee', 'thekitt', 'y', 'see', 'thedoggy', 'doy', 'oulike', 'thekitt', 'y', 'li', 'ke', 'thedoggy']
63 ['do', 'y', 'ousee', 'thekitt', 'y', 'see', 'thedoggy', 'doy', 'oulike', 'thekitt', 'y', 'li', 'ke', 'thedoggy']
63 ['do', 'y', 'ousee', 'thekitt', 'y', 'see', 'thedoggy', 'doy', 'oulike', 'thekitt', 'y', 'li', 'ke', 'thedoggy']
59 ['do', 'you', 'see', 'thekitt', 'y', 'see', 'thedoggy', 'doy', 'oulike', 'thekitt', 'y', 'like', 'thedoggy']
57 ['doyou', 'see', 'thekitt', 'y', 'see', 'thedoggy', 'doy', 'oulike', 'thekitt', 'y', 'like', 'thedoggy']
52 ['doyou', 'see', 'the', 'k', 'itt', 'y', 'see', 'thedoggy', 'doyou', 'like', 'the', 'k', 'itt', 'y', 'like', 'thedoggy']
52 ['doyou', 'see', 'the', 'k', 'itt', 'y', 'see', 'thedoggy', 'doyou', 'like', 'the', 'k', 'itt', 'y', 'like', 'thedoggy']
49 ['doyou', 'see', 'the', 'kitt', 'y', 'see', 'thedoggy', 'doyou', 'like', 'the', 'kitt', 'y', 'like', 'thedoggy']
49 ['doyou', 'see', 'the', 'kitt', 'y', 'see', 'thedoggy', 'doyou', 'like', 'the', 'kitt', 'y', 'like', 'thedoggy']
49 ['doyou', 'see', 'the', 'kitt', 'y', 'see', 'thedoggy', 'doyou', 'like', 'the', 'kitt', 'y', 'like', 'thedoggy']
46 ['doyou', 'see', 'thekitt', 'y', 'see', 'thedoggy', 'doyou', 'like', 'thekitt', 'y', 'like', 'thedoggy']
43 ['doyou', 'see', 'thekitty', 'see', 'thedoggy', 'doyou', 'like', 'thekitty', 'like', 'thedoggy']
43 ['doyou', 'see', 'thekitty', 'see', 'thedoggy', 'doyou', 'like', 'thekitty', 'like', 'thedoggy']
43 ['doyou', 'see', 'thekitty', 'see', 'thedoggy', 'doyou', 'like', 'thekitty', 'like', 'thedoggy']
43 ['doyou', 'see', 'thekitty', 'see', 'thedoggy', 'doyou', 'like', 'thekitty', 'like', 'thedoggy']
43 ['doyou', 'see', 'thekitty', 'see', 'thedoggy', 'doyou', 'like', 'thekitty', 'like', 'thedoggy']
43 ['doyou', 'see', 'thekitty', 'see', 'thedoggy', 'doyou', 'like', 'thekitty', 'like', 'thedoggy']
43 ['doyou', 'see', 'thekitty', 'see', 'thedoggy', 'doyou', 'like', 'thekitty', 'like', 'thedoggy']
43 ['doyou', 'see', 'thekitty', 'see', 'thedoggy', 'doyou', 'like', 'thekitty', 'like', 'thedoggy']
'0000100100000001001000000010000100010000000100010000000'
有了足够的数据,就可能以一个合理的准确度自动将文本分割成词汇。这种方法可用于
为那些词的边界没有任何视觉表示的书写系统分词。
3.9 格式化:从列表到字符串
1、从列表到字符串
silly = ['We', 'called', 'him', 'Tortoise', 'because', 'he', 'taught', 'us', '.']
print(" ".join(silly))
We called him Tortoise because he taught us .
1、字符串与格式
我们已经看到了有两种方式显示一个对象的内容:
word = "cat"
sentence = """
hello
word
"""
print(word)
print(sentence)
cat
hello
word
print命令让Python努力以人最可读的形式输出的一个对象的内容。
word
'cat'
sentence
'\nhello\nword\n'
第二种方法——叫做变量提示——向我们显示可用于重新创建该对象的字符串。
2、格式化输出
# 1.变量和常量交替出现
fdist = nltk.FreqDist(['dog', 'cat', 'dog', 'cat', 'dog', 'snake', 'dog', 'cat'])
for word in fdist:
print(word, "->", fdist[word], end = ";")
dog -> 4;cat -> 3;snake -> 1;
# 2.使用str.format()方法
fdist = nltk.FreqDist(['dog', 'cat', 'dog', 'cat', 'dog', 'snake', 'dog', 'cat'])
for word in fdist:
print("{}->{};".format(word, fdist[word]), end = ' ')
dog->4; cat->3; snake->1;
3、使用str.format()方法对齐
"{:6}".format(41) # 字符宽度为6,数字默认右对齐
' 41'
"{:<6}".format(41) # 字符宽度为6,数字 < 表示左对齐
'41 '
"{:6}".format("dog") # 字符宽度为6,字符默认左对齐
'dog '
"{:>6}".format("dog") # 字符宽度为6,字符 > 表示左对齐
' dog'
# 指定浮点数的符号和精度
import math
"{:.4f}".format(math.pi) # 表示小数点后边显示4位
'3.1416'
# 表示百分数
"accuracy for {} words: {:.4%}".format(9375, 3205 / 9375)
'accuracy for 9375 words: 34.1867%'
4、格式化字符串用于数据制表
def tabulate(cfdist, words, categories):
print("{:20}".format("Category"), end = " ")
for word in words:
print("{:>6}".format(word), end = " ")
print ()
for category in categories:
print("{:20}".format(category), end = " ")
for word in words:
print("{:6}".format(cfdist[category][word]), end = " ")
print()
from nltk.corpus import brown
cfd = nltk.ConditionalFreqDist(
(genre, word)
for genre in brown.categories()
for word in brown.words(categories = genre))
genres = ['news', 'religion', 'hobbies', 'science_fiction', 'romance', 'humor']
modals = ['can', 'could', 'may', 'might', 'must', 'will']
tabulate(cfd, modals, genres)
Category can could may might must will
news 93 86 66 38 50 389
religion 82 59 78 12 54 71
hobbies 268 58 131 22 83 264
science_fiction 16 49 4 12 8 16
romance 74 193 11 51 45 43
humor 16 30 8 8 9 13
# 自动定制列的宽度
#width = max(len(w) for w in words)
"{:{width}}".format("Monty Python", width = 15)
'Monty Python '
5、将结果写入文件
output_file = open("3.output.txt", "w")
words = set(nltk.corpus.genesis.words("english-kjv.txt"))
for word in sorted(words):
print(word, file = output_file)
# 当我们将非文本数据写入文件时,我们必须先将它转换为字符串。
print(str(len(words)), file = output_file)
6、文本换行
saying = ['After', 'all', 'is', 'said', 'and', 'done', ',',
'more', 'is', 'said', 'than', 'done', '.']
for word in saying:
print(word, "(" + str(len(word)) + ") , ", end = " ")
After (5) , all (3) , is (2) , said (4) , and (3) , done (4) , , (1) , more (4) , is (2) , said (4) , than (4) , done (4) , . (1) ,
我们可以在Python 的textwrap模块的帮助下采取换行。
from textwrap import fill
format = "%s (%d) , "
pieces = [format % (word, len(word)) for word in saying]
output = " ".join(pieces)
print(output,"\n")
print(fill(output))
After (5) , all (3) , is (2) , said (4) , and (3) , done (4) , , (1) , more (4) , is (2) , said (4) , than (4) , done (4) , . (1) ,
After (5) , all (3) , is (2) , said (4) , and (3) , done (4) , ,
(1) , more (4) , is (2) , said (4) , than (4) , done (4) , . (1)
,

















 1273
1273

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









