






如何添加负样本能提升YOLO目标检测模型的性能?
我们在此期间,还做了一次试验:想要通过增加大量空标签的负样本来提升模型识别的泛化性能。
我们把169张负样本加入28张正样本中,重新进行模型训练。
训练集:169张负样本+28张正样本
测试集:与训练集相同
训练中,我们查看显存占用:
GPU型号:3090
显存占用:3016 MiB(占用不到3G显存)
总显存: 24576 MiB
空闲显存:21560 MiB
训练效果:
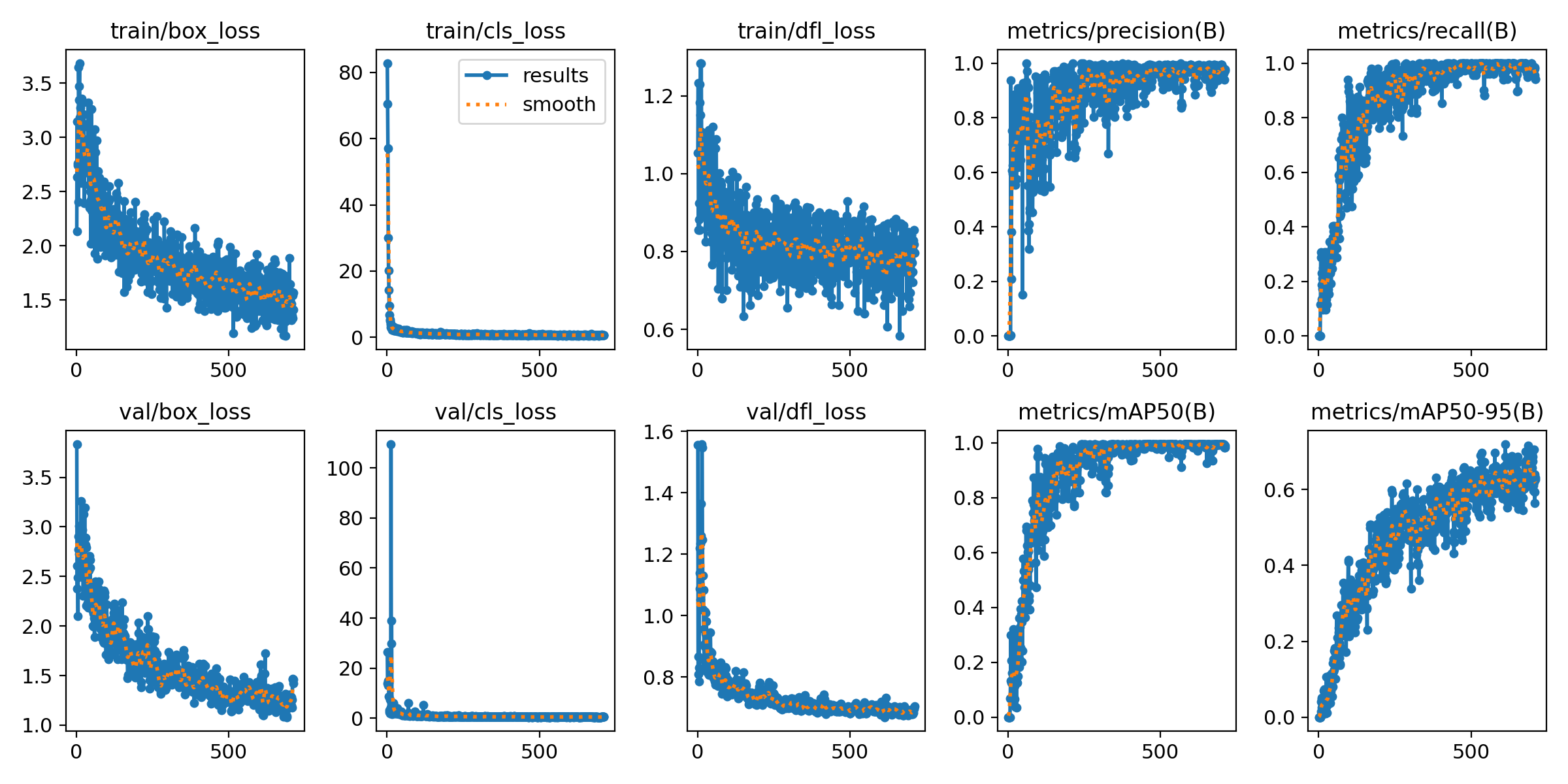
看起来损失函数、准确率、召回率波动很大,盲猜初始学习率设置可能偏大了,把学习率从原来的0.005,调小到0.0001,代码修改如下:
from ultralytics import YOLO # 注意这里是 YOLO,不是 YOLOWorld
# 加载 YOLOv8n 模型(标准目标检测模型)
model = YOLO('yolov8n.pt') # 这是官方 YOLOv8n 检测模型
# 开始训练
results = model.train(
data=r"./ad.yaml", # 你的数据集配置文件
epochs=10000, # 训练 100 轮
imgsz=640, # 输入图像尺寸
lr0=0.0001 # 初始学习率(你可以根据需要调整)
)
训练效果如下:
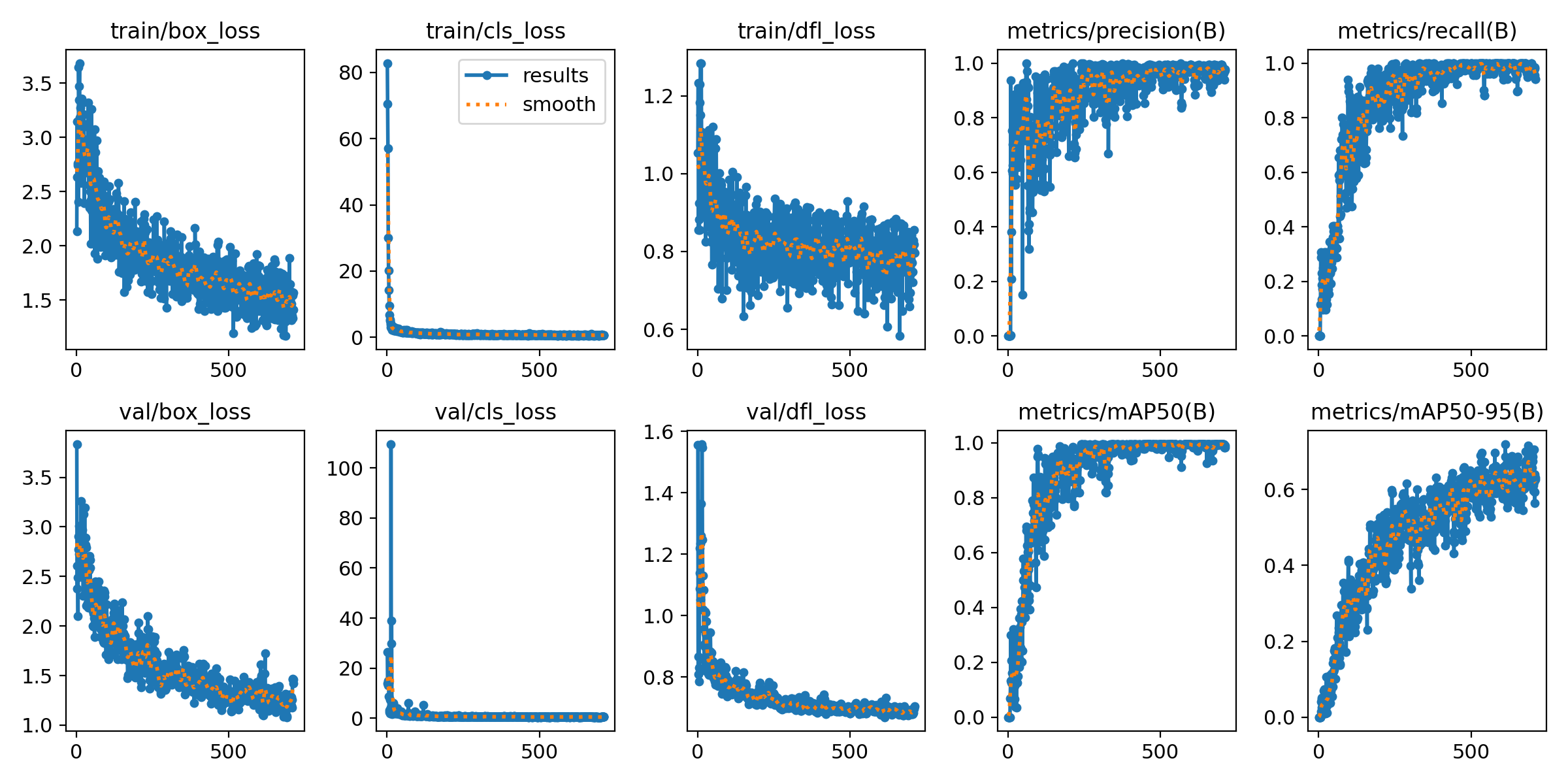
见效不大,看来不是这个问题,直接增加大量负样本貌似达不到好的效果,从推理结果来看,采样查看显示,所有采样推理样本的置信度均大幅下降。
训练集放负样本,
训练集:169张负样本+80张正样本
测试集:80张正样本
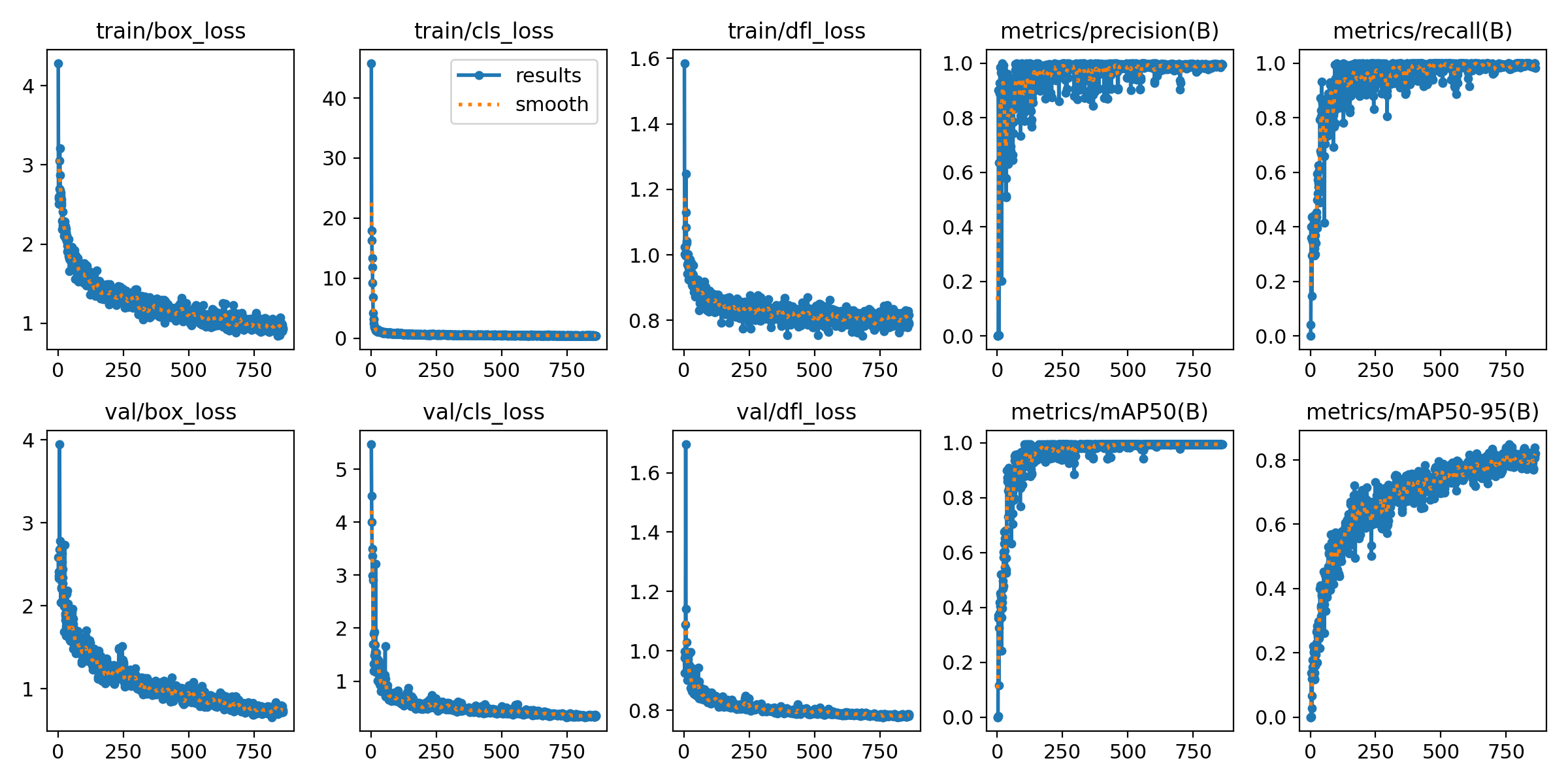
训练集和测试集中都加入负样本会让训练结果看起来比较差,这怎么理解呢?
训练集中加入负样本,测试集不加入,中间过程会看起来评价指标震荡较大,但最终的测试机评价效果基本一致。
目前的模型中,我认为训练集加入了负样本但测试集没加负样本的模型是最佳模型。

















 2611
2611

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









