






把读研以来所有使用到的pytorch函数列举一下(还在更新)
文章目录
- 把读研以来所有使用到的pytorch函数列举一下(还在更新)
- transforms.Compose()函数
- torch.unsqueeze()函数
- torch.floor()函数
- torch.ceil()函数
- torch.clamp()函数
- torch.nn.functional.interpolate()函数
- torch.permute()函数
- torch.squeeze()函数
- torch.manual_seed()函数
- torch.optim.lr_scheduler.StepLR()类
- torch.utils.data.RandomSampler(data_source, replacement=False, num_samples=None, generator=None)类
- torch.utils.data.SequentialSampler(data_source)类
- torch.utils.data.BatchSampler(sampler, batch_size, drop_last)类
- Dataset and IterableDataset类
- torch.utils.data.DataLoader(...) 类
- torch.rsqrt(input, *, out=None) 函数
- torch.flatten(input, start_dim=0, end_dim=- 1) 函数
- Tensor.view(*shape) → Tensor 函数
- Tensor.view(dtype) → Tensor 函数
- torch.repeat_interleave()函数
- torch.nn.Embedding类(nn.Module)
- torch.nn.Linear类(nn.Module)
- torch.bmm()函数
- torch.matmul()函数
- torch.tensor.masked_fill_()函数
- torch.tensor.expand_as()函数
- nn.identity()类
- torch.where()方法
- torch.amax()方法
- torch.cdist()方法,用于计算两个Tensor的距离矩阵
注意1:
model.cuda()#可以将模型加载到GPU上去,但是建议使用model.to(device)
注意2:
model.eval()#将model设置为评估模式,方便进行Evaluation,在评估模式下,batchNorm层,dropout层等用于优化训练而添加的网络层会被关闭,从而使得评估时不会发生偏移。在对模型进行评估时,应该配合使用
with torch.no_grad()与model.eval()如:loop: model.train() # 切换至训练模式 train…… model.eval() with torch.no_grad(): Evaluation end loop
注意3:
model.train()#将model设置为训练模式,方便进行train,在训练模式下,启用batch normalization和drop out等用于优化训练而添加的网络层。
transforms.Compose()函数
-
torchvision.transforms.Compose(transforms) -
其作用是将多个步骤整合到一起
transforms.Compose([transforms.CenterCrop(10),transforms.ToTensor()])#transforms.CenterCrop()与transforms.ToTensor()均为自带方法class resizeImageWithGT(object): def __init__(self, MAX_HW=1504): self.max_hw = MAX_HW def __call__(self, sample): ... TC = transforms.Compose([resizeImageWithGT(MAX_HW)]) TC(sample)#使用方式 -
transforms总结:-
torchvision.transforms.Normalize(mean, std, inplace=False)类Normalize a tensor image with mean and standard deviation. This transform does not support PIL Image. Given mean:
(mean[1],...,mean[n])and std:(std[1],..,std[n])fornchannels, this transform will normalize each channel of the inputtorch.Tensori.e.,output[channel] = (input[channel] - mean[channel]) / std[channel]
-
torch.unsqueeze()函数
-
作用是在指定的位置插入一个维度
# 创建一个3*4的全1二维tensor a = torch.ones(3,4) ''' 运行结果 tensor([[1., 1., 1., 1.], [1., 1., 1., 1.], [1., 1., 1., 1.]]) ''' a = a.unsqueeze(0) print(a.shape) ''' 运行结果 tensor([[[1., 1., 1., 1.], [1., 1., 1., 1.], [1., 1., 1., 1.]]]) torch.Size([1, 3, 4]) ''' a = a.unsqueeze(a.dim()) print(a.shape) ''' 运行结果 tensor([[[1.], [1.], [1.], [1.]], [[1.], [1.], [1.], [1.]], [[1.], [1.], [1.], [1.]]]) torch.Size([3, 4, 1]) '''
torch.floor()函数
-
torch.floor(input, *, out=None)用不大于每个值的最大整数替换每个值>>> a = torch.randn(4) >>> a tensor([-0.8166, 1.5308, -0.2530, -0.2091]) >>> torch.floor(a) tensor([-1., 1., -1., -1.])
torch.ceil()函数
-
torch.ceil(input, *, out=None)用大于等于每个值得最小整数替换每个值>>> a = torch.randn(4) >>> a tensor([-0.6341, -1.4208, -1.0900, 0.5826]) >>> torch.ceil(a) tensor([-0., -1., -1., 1.])
torch.clamp()函数
-
torch.clamp(input, min:tensor or number=None, max:tensor or number=None, *, out=None) → Tensor裁剪input的所有值,最大不超过max,最小不小于min>>> a = torch.randn(4) >>> a tensor([-1.7120, 0.1734, -0.0478, -0.0922]) >>> torch.clamp(a, min=-0.5, max=0.5) tensor([-0.5000, 0.1734, -0.0478, -0.0922]) >>> min = torch.linspace(-1, 1, steps=4) >>> torch.clamp(a, min=min) tensor([-1.0000, 0.1734, 0.3333, 1.0000])
torch.nn.functional.interpolate()函数
-
torch.nn.functional.interpolate(input, size=None, scale_factor=None, mode='nearest', align_corners=None, recompute_scale_factor=None, antialias=False)基于size或则scale_factor进行上采样或则下采样,插值算法由mode参数决定。现在版本支持空间以及体积的采样(如3维或4、5维的数据),input的维度为(批量大小,通道数,深度[可选],高度[可选],宽度),mode可选范围为nearest, linear (3D-only), bilinear, bicubic (4D-only), trilinear (5D-only), area, nearest-exact。
torch.permute()函数
-
torch.permute(input, dims) → Tensor用于置换input的维度,根据dims返回置换维度后的input>>> x = torch.randn(2, 3, 5) >>> x.size() torch.Size([2, 3, 5]) >>> torch.permute(x, (2, 0, 1)).size() torch.Size([5, 2, 3])
torch.squeeze()函数
-
torch.squeeze(input, dim=None, *, out=None) → TensorReturns a tensor with all the dimensions of
inputof size 1 removed.For example, if input is of shape: (A × \times × 1 × \times × B × \times × C × \times × 1 × \times × D) then the out tensor will be of shape: (A × \times × B × \times × C × \times × D).When
dimis given, a squeeze operation is done only in the given dimension. If input is of shape: (A×1×B),squeeze(input, 0)leaves the tensor unchanged, butsqueeze(input, 1)will squeeze the tensor to the shape (A×B).>>> x = torch.zeros(2, 1, 2, 1, 2) >>> x.size() torch.Size([2, 1, 2, 1, 2]) >>> y = torch.squeeze(x) >>> y.size() torch.Size([2, 2, 2]) >>> y = torch.squeeze(x, 0) >>> y.size() torch.Size([2, 1, 2, 1, 2]) >>> y = torch.squeeze(x, 1) >>> y.size() torch.Size([2, 2, 1, 2])
torch.manual_seed()函数
-
torch.manual_seed(seed)设置生成随机数的种子,返回一个对象
torch.Generator,只能决定torch的随机数生成
torch.optim.lr_scheduler.StepLR()类
-
torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=- 1, verbose=False)Decays the learning rate of each parameter group by gamma every step_size epochs. Notice that such decay can happen simultaneously with other changes to the learning rate from outside this scheduler. When last_epoch=-1, sets initial lr as lr.
>>> # Assuming optimizer uses lr = 0.05 for all groups >>> # lr = 0.05 if epoch < 30 >>> # lr = 0.005 if 30 <= epoch < 60 >>> # lr = 0.0005 if 60 <= epoch < 90 >>> # ... >>> scheduler = StepLR(optimizer, step_size=30, gamma=0.1)#由于没有设置last_epoch故初始的lr=lr >>> for epoch in range(100): >>> train(...) >>> validate(...) >>> scheduler.step() -
scheduler实例生成后有如下方法
-
get_last_lr()获得最后计算了的学习率
-
load_state_dict(state_dict)加载state_dict(dict)对象 – scheduler state. Should be an object returned from a call to [
state_dict()](https://pytorch.org/docs/1.12/generated/torch.optim.lr_scheduler.StepLR.html?highlight=torch optim lr_scheduler steplr#torch.optim.lr_scheduler.StepLR.state_dict). -
print_lr(is_verbose, group, lr, epoch=None)打印现在的学习率
-
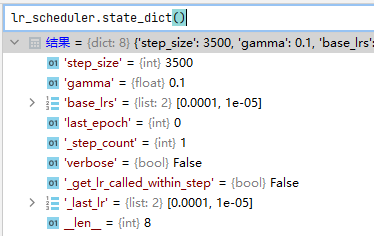
state_dict()返回现在的state_dict对象
-
torch.utils.data.RandomSampler(data_source, replacement=False, num_samples=None, generator=None)类
- Samples elements randomly. If without replacement, then sample from a shuffled dataset. If with replacement, then user can specify
num_samplesto draw. - 翻译:随机提取样本。如果replacement==False那么随机采样整个数据集,否则随机采样num_samples个数据。
torch.utils.data.SequentialSampler(data_source)类
- Samples elements sequentially, always in the same order.
- 翻译:按序采样整个数据集,总相同的顺序。
torch.utils.data.BatchSampler(sampler, batch_size, drop_last)类
-
Wraps another sampler to yield a mini-batch of indices.
-
翻译:包装另外一个采样器去生成一个小批量的坐标
>>> list(BatchSampler(SequentialSampler(range(10)), batch_size=3, drop_last=False)) [[0, 1, 2], [3, 4, 5], [6, 7, 8], [9]] >>> list(BatchSampler(SequentialSampler(range(10)), batch_size=3, drop_last=True)) [[0, 1, 2], [3, 4, 5], [6, 7, 8]] >>> list(data.BatchSampler(data.SequentialSampler(range(2,10)), batch_size=3, drop_last=False)) [[0, 1, 2], [3, 4, 5], [6, 7]]
Dataset and IterableDataset类
-
PyTorch supports two different types of datasets:
- map-style datasets
- iterable-style datasets
-
map-style datasets 对应 Dataset 类
torch.utils.data.Dataset(*args, **kwds)其是一个抽象类,所有维护一个key->data映射的数据集应该继承这个类,继承后需要实现__getitem__()与__len__()方法# 根据传入的index返回对应的数据 def __getitem__(self, index): ...# 返回数据集的长度 def __len__(self): ... -
iterable-style datasets 对应 IterableDataset 类
torch.utils.data.IterableDataset(*args, **kwds)其是一个迭代的Dataset类,也是抽象类,所有维护一个数据样本iterable的数据集应该继承这个类(特别对于数据集来自一个stream时很好用),继承后需要实现__iter__()方法# 返回一个这个数据集样本的iterator def __iter__(self): ...>>> # When num_workers > 0, each worker process will have a different copy of the dataset object, so it is often desired to configure each copy independently to avoid having duplicate data returned from the workers. >>> # 当 num_workers > 0 时开启了多线程读取数据方式,Setting the argument num_workers as a positive integer will turn on multi-process data loading with the specified number of loader worker processes. >>> # get_worker_info(), when called in a worker process, returns information about the worker. It can be used in either the dataset’s __iter__() method or the DataLoader ‘s worker_init_fn option to modify each copy’s behavior. >>> # Example 1: splitting workload across all workers in __iter__(): >>> class MyIterableDataset(torch.utils.data.IterableDataset): ... def __init__(self, start, end): ... super(MyIterableDataset).__init__() ... assert end > start, "this example code only works with end >= start" ... self.start = start ... self.end = end ... ... def __iter__(self): ... worker_info = torch.utils.data.get_worker_info() ... if worker_info is None: # single-process data loading, return the full iterator ... iter_start = self.start ... iter_end = self.end ... else: # in a worker process ... # split workload ... per_worker = int(math.ceil((self.end - self.start) / float(worker_info.num_workers))) ... worker_id = worker_info.id ... iter_start = self.start + worker_id * per_worker ... iter_end = min(iter_start + per_worker, self.end) ... return iter(range(iter_start, iter_end)) ... >>> # should give same set of data as range(3, 7), i.e., [3, 4, 5, 6]. >>> ds = MyIterableDataset(start=3, end=7) >>> # Single-process loading >>> print(list(torch.utils.data.DataLoader(ds, num_workers=0))) [3, 4, 5, 6] >>> # Mult-process loading with two worker processes >>> # Worker 0 fetched [3, 4]. Worker 1 fetched [5, 6]. >>> print(list(torch.utils.data.DataLoader(ds, num_workers=2))) [3, 5, 4, 6] >>> # With even more workers >>> print(list(torch.utils.data.DataLoader(ds, num_workers=20))) [3, 4, 5, 6]>>> # Example 2: splitting workload across all workers using worker_init_fn: >>> class MyIterableDataset(torch.utils.data.IterableDataset): ... def __init__(self, start, end): ... super(MyIterableDataset).__init__() ... assert end > start, "this example code only works with end >= start" ... self.start = start ... self.end = end ... ... def __iter__(self): ... return iter(range(self.start, self.end)) ... >>> # should give same set of data as range(3, 7), i.e., [3, 4, 5, 6]. >>> ds = MyIterableDataset(start=3, end=7) >>> # Single-process loading >>> print(list(torch.utils.data.DataLoader(ds, num_workers=0))) [3, 4, 5, 6] >>> >>> # Directly doing multi-process loading yields duplicate data >>> print(list(torch.utils.data.DataLoader(ds, num_workers=2))) [3, 3, 4, 4, 5, 5, 6, 6] >>> # Define a `worker_init_fn` that configures each dataset copy differently >>> def worker_init_fn(worker_id): ... worker_info = torch.utils.data.get_worker_info() ... dataset = worker_info.dataset # the dataset copy in this worker process ... overall_start = dataset.start ... overall_end = dataset.end ... # configure the dataset to only process the split workload ... per_worker = int(math.ceil((overall_end - overall_start) / float(worker_info.num_workers))) ... worker_id = worker_info.id ... dataset.start = overall_start + worker_id * per_worker ... dataset.end = min(dataset.start + per_worker, overall_end) ... >>> # Mult-process loading with the custom `worker_init_fn` >>> # Worker 0 fetched [3, 4]. Worker 1 fetched [5, 6]. >>> print(list(torch.utils.data.DataLoader(ds, num_workers=2, worker_init_fn=worker_init_fn))) [3, 5, 4, 6] >>> # With even more workers >>> print(list(torch.utils.data.DataLoader(ds, num_workers=20, worker_init_fn=worker_init_fn))) [3, 4, 5, 6]
torch.utils.data.DataLoader(…) 类
-
torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=None, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None, multiprocessing_context=None, generator=None, *, prefetch_factor=2, persistent_workers=False, pin_memory_device='') -
Data loader. Combines a dataset and a sampler, and provides an iterable over the given dataset.
The
DataLoadersupports both map-style and iterable-style datasets with single- or multi-process loading, customizing loading order and optional automatic batching (collation) and memory pinning.See
torch.utils.datadocumentation page for more details. -
这个方法超级复杂,每次需要使用时可以去查看文档
-
一个例子:
def collate_fn_crowd(batch): # re-organize the batch batch_new = [] for b in batch: imgs, points = b if imgs.ndim == 3: imgs = imgs.unsqueeze(0) for i in range(len(imgs)): batch_new.append((imgs[i, :, :, :], points[i])) batch = batch_new batch = list(zip(*batch)) batch[0] = nested_tensor_from_tensor_list(batch[0]) return tuple(batch) # 加载训练集,验证集 train_set, val_set = loading_data(args.data_root) # 初始化随机样本采样器 sampler_train = torch.utils.data.RandomSampler(train_set) # 使用批量样本采样器去包装随机样本采样器 batch_sampler_train = torch.utils.data.BatchSampler(sampler_train, args.batch_size, drop_last=True) # 使用批量样本采样器以及collate_fn_crowd()收集方法,并行args.num_workers个线程提取数据 data_loader_train = DataLoader(train_set, batch_sampler=batch_sampler_train, collate_fn=collate_fn_crowd, num_workers=args.num_workers) # 使用数据加载器来加载数据 for samples, targets in data_loader: ...
torch.rsqrt(input, *, out=None) 函数
-
torch.rsqrt(input, *, out=None) -
数学公式:
Returns a new tensor with the reciprocal of the square-root of each of the elements of
input.
out i = 1 input i \text{out}_{i} = \frac{1}{\sqrt{\text{input}_{i}}} outi=inputi1 -
# example >>> a = torch.randn(4) >>> a tensor([-0.0370, 0.2970, 1.5420, -0.9105]) >>> torch.rsqrt(a) tensor([ nan, 1.8351, 0.8053, nan])
torch.flatten(input, start_dim=0, end_dim=- 1) 函数
-
torch.flatten(input, start_dim=0, end_dim=- 1) -
Flattens
inputby reshaping it into a one-dimensional tensor. Ifstart_dimorend_dimare passed, only dimensions starting withstart_dimand ending withend_dimare flattened. The order of elements ininputis unchanged. -
Unlike NumPy’s flatten, which always copies input’s data, this function may return the original object, a view, or copy.
-
If no dimensions are flattened, then the original object
inputis returned. -
if input can be viewed as the flattened shape, then that view is returned.
-
if the input cannot be viewed as the flattened shape, then that copy is returned.
-
>>> t = torch.tensor([[[1, 2], ... [3, 4]], ... [[5, 6], ... [7, 8]]]) >>> torch.flatten(t) tensor([1, 2, 3, 4, 5, 6, 7, 8]) >>> torch.flatten(t, start_dim=1) tensor([[1, 2, 3, 4], [5, 6, 7, 8]])
Tensor.view(*shape) → Tensor 函数
-
Returns a new tensor with the same data as the
selftensor but of a differentshape. -
其与transpose()函数不一样,其不改变数据在存储中的表示方式
-
>>> x = torch.randn(4, 4) >>> x.size() torch.Size([4, 4]) >>> y = x.view(16) >>> y.size() torch.Size([16]) >>> z = x.view(-1, 8) # the size -1 is inferred from other dimensions >>> z.size() torch.Size([2, 8]) >>> a = torch.randn(1, 2, 3, 4) >>> a.size() torch.Size([1, 2, 3, 4]) >>> b = a.transpose(1, 2) # Swaps 2nd and 3rd dimension >>> b.size() torch.Size([1, 3, 2, 4]) >>> c = a.view(1, 3, 2, 4) # Does not change tensor layout in memory >>> c.size() torch.Size([1, 3, 2, 4]) >>> torch.equal(b, c) # 可以看出其与transpose()不同 False
Tensor.view(dtype) → Tensor 函数
-
Returns a new tensor with the same data as the
selftensor but of a differentdtype. -
>>> x = torch.randn(4, 4) >>> x tensor([[ 0.9482, -0.0310, 1.4999, -0.5316], [-0.1520, 0.7472, 0.5617, -0.8649], [-2.4724, -0.0334, -0.2976, -0.8499], [-0.2109, 1.9913, -0.9607, -0.6123]]) >>> x.dtype torch.float32 >>> y = x.view(torch.int32) >>> y tensor([[ 1064483442, -1124191867, 1069546515, -1089989247], [-1105482831, 1061112040, 1057999968, -1084397505], [-1071760287, -1123489973, -1097310419, -1084649136], [-1101533110, 1073668768, -1082790149, -1088634448]], dtype=torch.int32) >>> y[0, 0] = 1000000000 >>> x tensor([[ 0.0047, -0.0310, 1.4999, -0.5316], [-0.1520, 0.7472, 0.5617, -0.8649], [-2.4724, -0.0334, -0.2976, -0.8499], [-0.2109, 1.9913, -0.9607, -0.6123]]) >>> x.view(torch.cfloat) tensor([[ 0.0047-0.0310j, 1.4999-0.5316j], [-0.1520+0.7472j, 0.5617-0.8649j], [-2.4724-0.0334j, -0.2976-0.8499j], [-0.2109+1.9913j, -0.9607-0.6123j]]) >>> x.view(torch.cfloat).size() torch.Size([4, 2]) >>> x.view(torch.uint8) tensor([[ 0, 202, 154, 59, 182, 243, 253, 188, 185, 252, 191, 63, 240, 22, 8, 191], [227, 165, 27, 190, 128, 72, 63, 63, 146, 203, 15, 63, 22, 106, 93, 191], [205, 59, 30, 192, 112, 206, 8, 189, 7, 95, 152, 190, 12, 147, 89, 191], [ 43, 246, 87, 190, 235, 226, 254, 63, 111, 240, 117, 191, 177, 191, 28, 191]], dtype=torch.uint8) >>> x.view(torch.uint8).size() torch.Size([4, 16])
torch.repeat_interleave()函数
-
torch.repeat_interleave(input, repeats, dim=None, *, output_size=None) → Tensor -
Repeat elements of a tensor.
-
>>> x = torch.tensor([1, 2, 3]) >>> x.repeat_interleave(2) # By default, use the flattened input array, and return a flat output array. tensor([1, 1, 2, 2, 3, 3]) >>> y = torch.tensor([[1, 2], [3, 4]]) >>> torch.repeat_interleave(y, 2) tensor([1, 1, 2, 2, 3, 3, 4, 4]) >>> torch.repeat_interleave(y, 3, dim=1) tensor([[1, 1, 1, 2, 2, 2], [3, 3, 3, 4, 4, 4]]) >>> torch.repeat_interleave(y, torch.tensor([1, 2]), dim=0) tensor([[1, 2], [3, 4], [3, 4]]) >>> torch.repeat_interleave(y, torch.tensor([1, 2]), dim=0, output_size=3) tensor([[1, 2], [3, 4], [3, 4]]) -
If the repeats is tensor([n1, n2, n3, …]), then the output will be tensor([0, 0, …, 1, 1, …, 2, 2, …, …]) where 0 appears n1 times, 1 appears n2 times, 2 appears n3 times, etc.
torch.nn.Embedding类(nn.Module)
-
torch.nn.Embedding(num_embeddings, embedding_dim, padding_idx=None, max_norm=None, norm_type=2.0, scale_grad_by_freq=False, sparse=False, _weight=None, device=None, dtype=None)num_embeddings是输入的字典大小,如果你输入里面有10个不一样的元素,然后你的字典设置为9,会导致如下错误发生
>>> x = torch.arange(10).reshape(5,-1) # 输入有10个不一样的元素 >>> embedding = torch.nn.Embedding(9, 3) # Embedding层字典大小只有9<10导致错误 >>> embedding(x) Traceback (most recent call last): File "D:\Anaconda\envs\first_semester_of_master\lib\site-packages\IPython\core\interactiveshell.py", line 3553, in run_code exec(code_obj, self.user_global_ns, self.user_ns) File "<ipython-input-48-c328606b6f70>", line 1, in <module> embedding(x) File "D:\Anaconda\envs\first_semester_of_master\lib\site-packages\torch\nn\modules\module.py", line 1130, in _call_impl return forward_call(*input, **kwargs) File "D:\Anaconda\envs\first_semester_of_master\lib\site-packages\torch\nn\modules\sparse.py", line 160, in forward self.norm_type, self.scale_grad_by_freq, self.sparse) File "D:\Anaconda\envs\first_semester_of_master\lib\site-packages\torch\nn\functional.py", line 2199, in embedding return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse) IndexError: index out of range in selfembedding_dim输出的每个词向量的维度
>>> # 接上面 >>> embedding = torch.nn.Embedding(10, 3) >>> embedding(x).shape torch.Size([5, 2, 3])embedding = torch.nn.Embedding(10, 3)的内部权重的结构是 ( 10 × 3 ) (10\times3) (10×3)
即针对每个x的值如1,寻找权重中的weight[1,:]使用这个做结果第三维的值
例子:
>>> em=torch.rand(3,2) >>> em Out: tensor([[0.8452, 0.5519], # 0对应向量 [0.7074, 0.3604], # 1对应向量 [0.8119, 0.3996]]) # 2对象向量 >>> input=torch.tensor([0,1,2,1]) >>> torch.nn.functional.embedding(input,em) Out: tensor([[0.8452, 0.5519], # 0 [0.7074, 0.3604], # 1 [0.8119, 0.3996], # 2 [0.7074, 0.3604]]) # 1 -
后面的参数用到再说
torch.nn.Linear类(nn.Module)
-
torch.nn.Linear(in_features, out_features, bias=True, device=None, dtype=None)对输入使用线性变换: y = x A T + b y = xA^T + b y=xAT+b
其实上面这个不是重点,这个函数的重点在于其可以针对维度如 ( 2 × 2 × 3 ) (2\times2\times3) (2×2×3)这种多维度的输入,与我以前所一直认为的只能针对二维输入不一样,其可以支持多维
还是先说说其参数:
- in_features:输入的最后一维度的大小,如 ( 2 × 2 × 3 ) (2\times2\times3) (2×2×3)就是3
- out_features:你想要输出的最后一维度的大小,比如,如果这个参数是4,那么 ( 2 × 2 × 3 ) (2\times2\times3) (2×2×3)会变为 ( 2 × 2 × 4 ) (2\times2\times4) (2×2×4)
- bias:是否使用偏差,即上面公式是否+b
ps:这个组件的默认权重与偏差的初始化使用如下方式
- 权重A使用 U ( − k , k ) \mathcal{U}(-\sqrt{k}, \sqrt{k}) U(−k,k)初始化,即在 ( − k , k ) (-\sqrt{k}, \sqrt{k}) (−k,k)范围内的平均分布权重初始化, k = 1 in_features k = \frac{1}{\text{in\_features}} k=in_features1
- 偏差b使用与权重一样的初始化方式
-
举例:
>>> x = torch.arange(12,dtype=torch.float32).view(2,2,3) >>> x Out: tensor([[[ 0., 1., 2.], [ 3., 4., 5.]], [[ 6., 7., 8.], [ 9., 10., 11.]]]) >>> linear=torch.nn.Linear(3,1) # in_features=3,out_features=1 >>> linear.weight # 展示权重 Out: Parameter containing: tensor([[ 0.4956, -0.0664, -0.5577]], requires_grad=True) >>> linear.bias # 展示偏差 Out: Parameter containing: tensor([0.2490], requires_grad=True) >>> y = linear(x) >>> y.shape Out: torch.Size([2, 2, 1]) >>> y Out: tensor([[[-0.9327], # 下面会展示如何得到这个-0.9327 [-1.3183]], [[-1.7040], [-2.0896]]], grad_fn=<ViewBackward0>) >>> torch.sum(torch.dot(x[0,0,:],linear.weight.t().view(3))+linear.bias) # 即[ 0., 1., 2.]与权重[ 0.4956, -0.0664, -0.5577]的转置做矩阵乘法,再加上偏差0.2490 Out: tensor(-0.9327, grad_fn=<SumBackward0>)
torch.bmm()函数
-
torch.bmm(input, mat2, *, out=None) → Tensor如果
input是一个 ( b × n × m ) (b \times n \times m) (b×n×m) 张量,mat2是一个 ( b × m × p ) (b \times m \times p) (b×m×p) 张量,out将会是 ( b × n × p ) (b \times n \times p) (b×n×p) 张量。out i = input i @ mat2 i \text{out}_i = \text{input}_i \mathbin{@} \text{mat2}_i outi=inputi@mat2i,即每个对应的 ( n × m ) (n \times m) (n×m)矩阵与 ( m × p ) (m \times p) (m×p)矩阵做矩阵乘法
值得注意的是:
input与mat2必须是3维的并且各自包含相同数量的矩阵。>>> input = torch.randn(10, 3, 4) >>> mat2 = torch.randn(10, 4, 5) >>> res = torch.bmm(input, mat2) >>> res.size() torch.Size([10, 3, 5])
torch.matmul()函数
-
超级复杂,最好看示例,就懂了
-
torch.matmul(input, other, *, out=None) → Tensor -
Matrix product of two tensors.
The behavior depends on the dimensionality of the tensors as follows:
-
If both tensors are 1-dimensional, the dot product (scalar) is returned.
-
If both arguments are 2-dimensional, the matrix-matrix product is returned.
-
If the first argument is 1-dimensional and the second argument is 2-dimensional, a 1 is prepended to its dimension for the purpose of the matrix multiply. After the matrix multiply, the prepended dimension is removed.
-
If the first argument is 2-dimensional and the second argument is 1-dimensional, the matrix-vector product is returned.
-
If both arguments are at least 1-dimensional and at least one argument is N-dimensional (where N > 2), then a batched matrix multiply is returned. If the first argument is 1-dimensional, a 1 is prepended to its dimension for the purpose of the batched matrix multiply and removed after. If the second argument is 1-dimensional, a 1 is appended to its dimension for the purpose of the batched matrix multiple and removed after. The non-matrix (i.e. batch) dimensions are broadcasted (and thus must be broadcastable). For example, if
inputis a (j \times 1 \times n \times n)(j×1×n×n) tensor andotheris a (k \times n \times n)(k×n×n) tensor,outwill be a (j \times k \times n \times n)(j×k×n×n) tensor.Note that the broadcasting logic only looks at the batch dimensions when determining if the inputs are broadcastable, and not the matrix dimensions. For example, if
inputis a (j \times 1 \times n \times m)(j×1×n×m) tensor andotheris a (k \times m \times p)(k×m×p) tensor, these inputs are valid for broadcasting even though the final two dimensions (i.e. the matrix dimensions) are different.outwill be a (j \times k \times n \times p)(j×k×n×p) tensor.
This operator supports TensorFloat32.
-
-
>>> # vector x vector >>> tensor1 = torch.randn(3) >>> tensor2 = torch.randn(3) >>> torch.matmul(tensor1, tensor2).size() torch.Size([]) >>> # matrix x vector >>> tensor1 = torch.randn(3, 4) >>> tensor2 = torch.randn(4) >>> torch.matmul(tensor1, tensor2).size() torch.Size([3]) >>> # batched matrix x broadcasted vector >>> tensor1 = torch.randn(10, 3, 4) >>> tensor2 = torch.randn(4) >>> torch.matmul(tensor1, tensor2).size() torch.Size([10, 3]) >>> # batched matrix x batched matrix >>> tensor1 = torch.randn(10, 3, 4) >>> tensor2 = torch.randn(10, 4, 5) >>> torch.matmul(tensor1, tensor2).size() torch.Size([10, 3, 5]) >>> # batched matrix x broadcasted matrix >>> tensor1 = torch.randn(10, 3, 4) >>> tensor2 = torch.randn(4, 5) >>> torch.matmul(tensor1, tensor2).size() torch.Size([10, 3, 5])
torch.tensor.masked_fill_()函数
Tensor.masked_fill_(mask, value)- Fills elements of
selftensor withvaluewheremaskis True. The shape ofmaskmust be broadcastable with the shape of the underlying tensor. - Parameters
- mask (BoolTensor) – the boolean mask
- value (float) – the value to fill in with
torch.tensor.expand_as()函数
-
Tensor.expand_as(other) → Tensor -
Expand this tensor to the same size as
other.self.expand_as(other)is equivalent toself.expand(other.size()).Please see
expand()for more information aboutexpand.-
Parameters
other (
torch.Tensor) – The result tensor has the same size asother.
-
nn.identity()类
-
一个占位符,进行identity操作的nn.Module,对参数不敏感
-
torch.nn.Identity(*args, **kwargs) -
>>> # 示例 >>> m = nn.Identity(54, unused_argument1=0.1, unused_argument2=False) >>> input = torch.randn(128, 20) >>> output = m(input) >>> print(output.size()) torch.Size([128, 20])
torch.where()方法
-
torch.where(condition, x, y) → Tensor -
Return a tensor of elements selected from either
xory, depending oncondition.The operation is defined as:
out i = { x i if condition i y i otherwise \text{out}_i = \begin{cases} \text{x}_i & \text{if } \text{condition}_i \\ \text{y}_i & \text{otherwise} \\ \end{cases} outi={xiyiif conditioniotherwise
The tensors
condition,x,ymust be broadcastable. -
>>> x = torch.randn(3, 2) >>> y = torch.ones(3, 2) >>> x tensor([[-0.4620, 0.3139], [ 0.3898, -0.7197], [ 0.0478, -0.1657]]) >>> torch.where(x > 0, x, y) tensor([[ 1.0000, 0.3139], [ 0.3898, 1.0000], [ 0.0478, 1.0000]]) >>> x = torch.randn(2, 2, dtype=torch.double) >>> x tensor([[ 1.0779, 0.0383], [-0.8785, -1.1089]], dtype=torch.float64) >>> torch.where(x > 0, x, 0.) tensor([[1.0779, 0.0383], [0.0000, 0.0000]], dtype=torch.float64)
torch.amax()方法
-
torch.amax(input, dim, keepdim=False, *, out=None) → Tensor -
Returns the maximum value of each slice of the
inputtensor in the given dimension(s)dim. -
如dim=0,则返回0维度下每个切片的最大值
-
The difference between
max/minandamax/aminis:amax/aminsupports reducing on multiple dimensions,amax/amindoes not return indices,amax/aminevenly distributes gradient between equal values, whilemax(dim)/min(dim)propagates gradient only to a single index in the source tensor.
-
>>> a = torch.randn(4, 4) >>> a tensor([[ 0.8177, 1.4878, -0.2491, 0.9130], [-0.7158, 1.1775, 2.0992, 0.4817], [-0.0053, 0.0164, -1.3738, -0.0507], [ 1.9700, 1.1106, -1.0318, -1.0816]]) >>> torch.amax(a, 1) tensor([1.4878, 2.0992, 0.0164, 1.9700])
torch.cdist()方法,用于计算两个Tensor的距离矩阵
-
torch.cdist(x1, x2, p=2.0, compute_mode='use_mm_for_euclid_dist_if_necessary') -
Computes batched the p-norm distance between each pair of the two collections of row vectors.
-
参数
- x1 (Tensor) – input tensor of shape B×P×M.
- x2 (Tensor) – input tensor of shape B×R×M.
- p – p value for the p-norm distance to calculate between each vector pair ∈[0,∞].
- compute_mode – ‘use_mm_for_euclid_dist_if_necessary’ - will use matrix multiplication approach to calculate euclidean distance (p = 2) if P > 25 or R > 25 ‘use_mm_for_euclid_dist’ - will always use matrix multiplication approach to calculate euclidean distance (p = 2) ‘donot_use_mm_for_euclid_dist’ - will never use matrix multiplication approach to calculate euclidean distance (p = 2) Default: use_mm_for_euclid_dist_if_necessary.
-
If x1 has shape B×P×M and x2 has shape B×R×M then the output will have shape B×P×R.
-
>>> a = torch.tensor([[0.9041, 0.0196], [-0.3108, -2.4423], [-0.4821, 1.059]]) >>> a tensor([[ 0.9041, 0.0196], [-0.3108, -2.4423], [-0.4821, 1.0590]]) >>> b = torch.tensor([[-2.1763, -0.4713], [-0.6986, 1.3702]]) >>> b tensor([[-2.1763, -0.4713], [-0.6986, 1.3702]]) >>> torch.cdist(a, b, p=2) tensor([[3.1193, 2.0959], [2.7138, 3.8322], [2.2830, 0.3791]])


















 8484
8484

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











