







往期地址:
- 操作系统系列一 —— 操作系统概述
- 操作系统系列二 —— 进程
- 操作系统系列三 —— 编译与链接关系
- 操作系统系列四 —— 栈与函数调用关系
- 操作系统系列五 —— 目标文件详解
- 操作系统系列六 —— 详细解释【静态链接】
- 操作系统系列七 —— 装载
- 操作系统系列八 ——动态链接
- 操作系统系列九 ——系统调用和API
- 从编译角度看c和c++混合编译
- stripped文件描述以及gdb反汇编工具使用
- 操作系统的信号量操作以及实战中的踩坑分析
本期主题:
程序的汇编指令讲解
目录
1. x86-64的历史由来
- Intel处理器系列俗称x86系列,刚开始是单芯片,16位微处理器,后面随着集成电路技术不断提高,现在都是64位的处理器,称为x86-64;
- 由于是从16位体系结构扩展成32位的,Intel用术语 字(words) 来表示16位数据类型,因此,32位被称为双字(double words),64位称为 四字(quad words)
历史由来
Intel处理器俗称x86的由来可以追溯到英特尔开发的一系列处理器,这些处理器型号以“86”结尾。
- 8086处理器:1978年,英特尔发布了8086处理器,这是一个16位的处理器,也是英特尔的第一款x86架构处理器。8086处理器采用了当时新型的复杂指令集计算(CISC)架构,为未来的x86系列奠定了基础。
- 后续的处理器型号:在8086之后,英特尔继续推出了一系列以“86”结尾的处理器,包括:
80186
80286
80386
80486
这些处理器共同特征是都采用了类似的指令集架构,并且在型号命名上延续了“86”的传统。- x86架构:由于这些处理器的型号命名习惯,整个系列被统称为x86架构。这一名称后来成为该指令集架构的代名词,无论其具体的处理器型号是什么。
- 品牌和架构的延续:虽然后来的处理器型号不再直接以“86”结尾(如奔腾系列、酷睿系列等),但这些处理器仍然基于x86架构。因此,x86成为了英特尔以及兼容处理器的一个通用术语,用于指代这一系列的指令集架构。
下图是C语言类型在 x86-64位中的大小
| C语言类型 | Intel数据类型 | 汇编代码后缀 | 大小(字节) |
|---|---|---|---|
| char | 字节 | b | 1 |
| short | 字 | w | 2 |
| int | 双字 | l | 4 |
| long | 四字 | q | 8 |
| char* | 四字 | q | 8 |
| float | 单精度 | s | 4 |
| double | 双精度 | l | 8 |
大多数gcc生成的汇编代码都有一个字符的后缀,表明操作数的大小。例如数据传输指令mov有四种变种:
- movb(传送字节)
- movw(传输字)
- movl(传输双字)
- movq(传输四字)
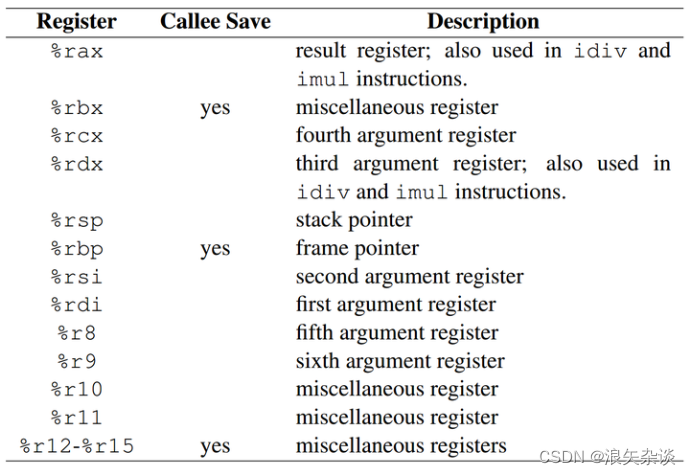
2. x86-64的寄存器信息
x86-64的机器代码和C语言代码相差非常大,C语言程序员比较关注的如下:
- 程序计数器(通常也被称为"PC",在x86-64中用%rip来表示),表示将要执行的下一条指令在内存中的地址;
- 通用目的寄存器,一个x86-64的中央处理器包含一组16个存储64位值的通用目的寄存器;
- 栈指针寄存器
- 作用:rsp(Stack Pointer)寄存器指向栈的顶部。栈是一种数据结构,遵循后进先出(LIFO)原则,通常用于管理函数调用和返回、局部变量等。
- 用法:每当数据被推入栈时,rsp 的值会减小(因为栈在x86_64上是向低地址增长的);每当数据被弹出栈时,rsp 的值会增大。
- 变化:在函数调用和返回过程中,rsp 会频繁变化。每次调用一个新函数时,会在栈上分配一个新的栈帧,rsp 会减少。函数返回时,rsp 会恢复到调用前的状态。
- 帧指针寄存器
- 作用:rbp(Base Pointer 或 Frame Pointer)寄存器通常用于保存当前栈帧的基地址。栈帧是一个函数在栈上分配的区域,用于存储局部变量、函数参数、返回地址等。
- 用法:在进入一个函数时,通常会保存调用者的 rbp 并将当前的 rsp(栈指针)值保存到 rbp,以便函数可以轻松地访问其栈帧中的局部变量和参数。
- 变化:在函数调用过程中,rbp 通常保持不变,直到函数返回。它用于帮助调试器和程序维护栈帧链。
寄存器如下图:
3. 操作数指示符
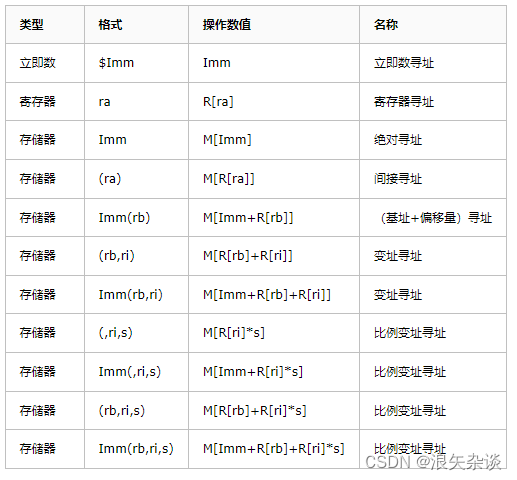
大多数指令有一个或多个操作数(operand),指示出执行一个操作中要使用的源数据值,放置位置以及目的位置。
1. 寻址方式
根据操作数的可能性,将寻址方式分为三种类型:
- 立即数,用来表示常数值,例如 $1234,就是代表常数1234;
- 寄存器,表示某个寄存器的内容,我们用符号 r a r_a ra 来表示任意寄存器,用符号 R[ r a r_a ra] 来表示它的值;
- 内存引用,根据计算出来的地址访问某个内存位置;
寻址模式综合一下:
2. 数据传输指令
将数据从一个位置复制到另一个位置的指令。
MOV 指令的简单形式如下,代表着将数据从 S移动到D这个位置:
MOV S,D
MOV指令由四条指令组成:movb、movw、movl、movq,对应着我们前面说的汇编指令后缀名的差异,其实主要差别在于操作数的大小不同。
MOV操作指令有几个特点:
源操作数指定的是一个数据,这个数据可以是 立即数,也可以存储在寄存器或者内存中;目的操作数指定的是一个位置,要么是寄存器或者是一个地址;mov指令不能两个操作数都指向内存地址,如果想要实现将一个值从一个内存地址复制到另一个内存地址,需要使用两条指令——第一条指令将源值加载到寄存器中,第二条指令将寄存器值写入目的位置;
举例看下面的命令,实际上的意思就是将 0x4050这个数据,放在eax寄存器中
movl $0x4050, %eax
example 实例
看一个指针的具体例子
源码:
long exchange(long *xp, long y)
{
long x = *xp;
*xp = y;
return x;
}
对应的反汇编代码,使用 objdump -d xxx 来进行反汇编:

对汇编代码进行解释:
// 前面讲过了,%rdi存的是第一个参数,%rsi 存的是第二个参数
// 在例子中具体具体就是 %rdi存的是xp这个指针,%rsi存的是y
// (%rdi),取出xp指针的值,即*xp
mov (%rdi),%rax , 把*xp赋值给返回值x
mov %rsi,(%rdi) , 把y赋值给*xp
从上面的汇编代码中可以看出两点:
C语言的指针其实就是地址。间接引用指针其实就是将该指针放在一个寄存器中,然后在内存引用中使用这个寄存器。像x这样的局部变量通常保存在寄存器中,而不是内存中。由于访问寄存器比访问内存要快得多。
3. 压入和弹出栈数据
栈是一种数据结构,可以添加或者删除值,遵循后进先出的原则。通过push把数据压入栈中,通过pop操作删除数据。
栈向下增长,栈顶元素的地址是所有栈中元素地址最低的。%rsp保存着栈顶元素的地址。
| 指令 | 效果 | 描述 |
|---|---|---|
| pushq S | R[%rsp] <- R[%rsp] - 8; M[R[%rsp]] <- S | 将四字压入栈 1. 先是取出%rsp寄存器的值,并减8,再给回%rsp寄存器; 2. 将S的值给到新的%rsp寄存器的值所指向的内容中 |
| popq D | D <- M[R[%rsp]] ; R[%rsp] <- R[%rsp] + 8 | 将四字弹出栈 1. 先是取出%rsp寄存器的值,给到8; 2. 将%rsp寄存器+8 |
4. 加载有效地址 lea指令
加载有效地址(load effective address)指令lea实际上是mov指令的变形,它的指令形式是从内存读数据到寄存器。
与mov指令的差别在于:写入的目的操作数一定是寄存器。
example
看一个例子,源码如下:
#include <stdio.h>
#include <stdlib.h>
long scale(long x, long y, long z)
{
long t = x + 4 * y + 12 * z;
return t;
}
注意使用gcc编译的时候,需要使用-Og,这样是为了防止编译器进行优化,导致结果对不上
gcc -Og -c main.c -o main_Og.o
使用objdump看结果:
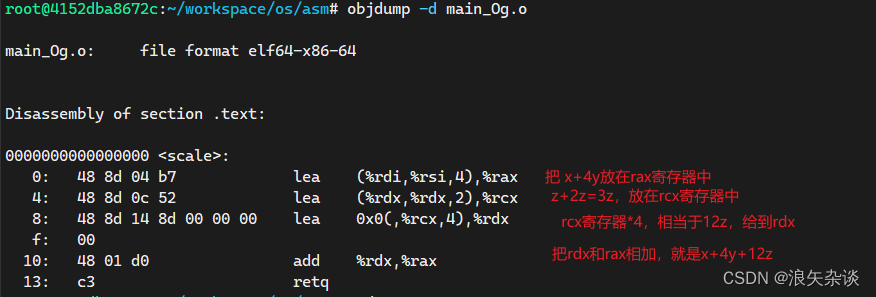















 1217
1217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









