







3.1 一元线性回归
3.1.1 算法原理
例子:利用【发际线的高度】等特征预测【计算机水平】
分析数据发现是线性关系
- 仅通过发际线高度预测计算机水平: f ( x ) = w 1 x 1 + b f(x) = w_{1}x_{1} + b f(x)=w1x1+b
- 加上二值离散特征【颜值】(好看:1,不好看:0) f ( x ) = w 1 x 1 + w 2 x 2 + b f(x) = w_{1}x_{1} + w_{2}x_{2} +b f(x)=w1x1+w2x2+b
- 加上有序的多值离散特征【饭量】(小:1,中:2,大:3) f ( x ) = w 1 x 1 + w 2 x 2 + w 3 x 3 + b f(x) = w_{1}x_{1} + w_{2}x_{2} + w_{3}x_{3} +b f(x)=w1x1+w2x2+w3x3+b
- 加上无序的多值离散特征【肤色】onehot(黄:[1,0,0],黑:[0,1,0],白:[0,0,1])
均方误差 平行于y轴 f ( x ) = w 1 x 1 + w 2 x 2 + w 3 x 3 + b f(x) = w_{1}x_{1} + w_{2}x_{2} + w_{3}x_{3} +b f(x)=w1x1+w2x2+w3x3+b
正交误差 垂直于分界线
3.2.1 最小二乘法
基于均方误差最小化来进行模型求解的方法称为“最小二乘法”
E ( w , b ) = ∑ i = 1 m ( y i − f ( x i ) ) 2 = ∑ i = 1 m ( y i − ( w x i + b ) ) 2 = ∑ i = 1 m ( y i − w x i − b ) 2 \begin{aligned} E_{(w, b)} &= \sum_{i = 1}^{m}\left(y_{i}-f\left(x_{i}\right)\right)^{2} \\ &= \sum_{i = 1}^{m}\left(y_{i}-\left(w x_{i}+b\right)\right)^{2} \\ &= \sum_{i = 1}^{m}\left(y_{i}-w x_{i}-b\right)^{2} \end{aligned} E(w,b)=i=1∑m(yi−f(xi))2=i=1∑m(yi−(wxi+b))2=i=1∑m(yi−wxi−b)2
3.2.2 极大似然估计
对于离散型(连续型)随机变量
X
X
X ,假设其概率质量函数为
P
(
x
;
θ
)
P(x;\theta)
P(x;θ)(概率密度函数为
p
(
x
;
θ
)
p(x;\theta)
p(x;θ) ),其中 为待估计的参数值(可以有多个)。现有
x
1
,
x
2
,
x
3
.
.
.
,
x
n
x_{1},x_{2},x_{3}...,x_{n}
x1,x2,x3...,xn是来自
X
X
X 的
n
n
n 个独立同分布的样本,它们的联合概率为
L
(
θ
)
=
∏
i
=
1
n
P
(
x
i
;
θ
)
L(\theta)=\prod_{i=1}^{n} P\left(x_{i} ; \theta\right)
L(θ)=i=1∏nP(xi;θ)极大似然估计的直观想法:使得观测样本出现概率最大的分布就是待求分布,也即使得联合概率(似然函数) 取到最大值的 即为 的估计值。

连乘计算量一般比较大,可以取对数转换成加法。
转换称号举证向量计算会快很多(W的向量化 for循环->numpy)



3.3 求解 w w w 和 b b b
求
w
w
w 和
b
b
b其本质上是一个多元函数求最值(点)的问题,更具体点是凸函数求最值的问题。
思路:
- 证明 E ( w , b ) = ∑ i = 1 m ( y i − w x i − b ) 2 E_{(w, b)}=\sum_{i=1}^{m}\left(y_{i}-w x_{i}-b\right)^{2} E(w,b)=∑i=1m(yi−wxi−b)2是关于 w w w 和 b b b 的凸函数
- 用凸函数求最值得方法求出 w w w 和 b b b
3.1 证明是凸函数

凸集和凹集对应的最直观的例子是⚪和❤
这里和之前高等数学中得凹凸刚好相反,是最优化问题上得凹凸函数。
另外,好像凹函数也是在凸集上的。



半正定包含正定,多了等于0的情况。也就是说,正定要求更严格,正定一定符合半正定。
求海塞矩阵


3.3.2 求解 w w w 和 b b b

3.4 机器学习三要素
模型
根据问题,确定假设空间。
例如根据发际线高度预测计算机水平。
假设空间:根据我们的经验和观察到的数据形态,这个问题应该是个线性关系
f ( x ) = w T x + b f(x)=w^{T}x+b f(x)=wTx+b 起码不是二次函数之类的,先确定一个大概的范围。
策略
根据评价标准,确定选取最优模型的策略(通常会产生一个损失函数)。
案例中策略:在假设空间中满足均方误差最小(最小二乘法)的模型,即为我们要求的模型。
基 于 均 方 误 差 ( 最 小 二 乘 ) 损 失 函 数 E ( w , b ) = ∑ i = 1 m ( y i − f ( x i ) ) 2 基于均方误差(最小二乘)损失函数 E_{(w,b)}= \sum_{i=1}^{m} (y_{i}-f(x_{i}))^{2} 基于均方误差(最小二乘)损失函数E(w,b)=i=1∑m(yi−f(xi))2 基于极大似然的损失函数 ϵ \epsilon ϵ 符合正态分布,其损失函数和上述一致。
算法
求解损失函数,确定最优模型。
求出w,b
证明他是凸函数,根据凸函数梯度=0最优求出最优解(闭式解)
神经网络一般解不出闭式解 只能用梯度下降,牛顿法 解出近似解
3.2 多元线性回归
3.2.1 由最小二乘法导出损失函数 E w ^ E_{\hat{\boldsymbol{w}}} Ew^
简化统一计算
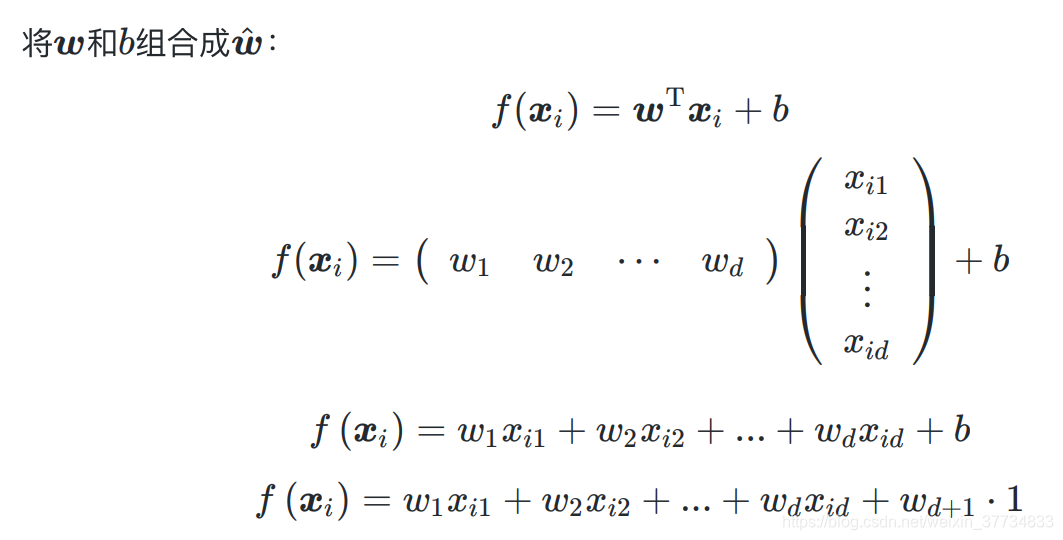
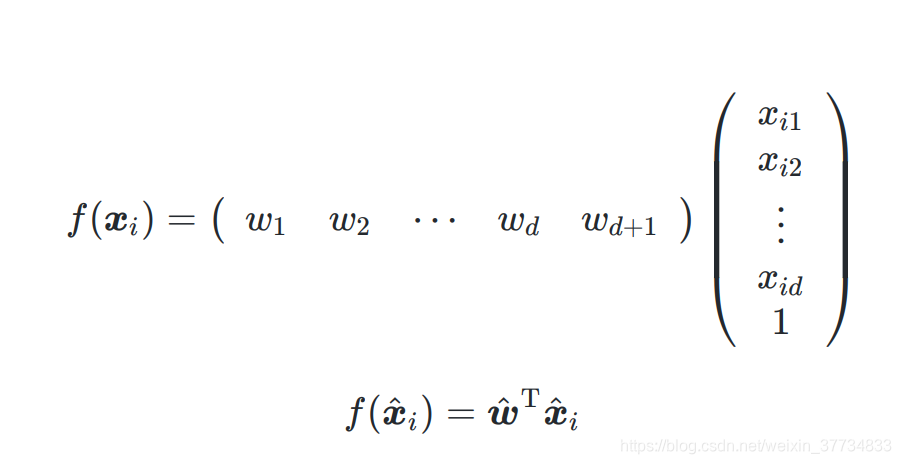 最小二乘法,得到
最小二乘法,得到
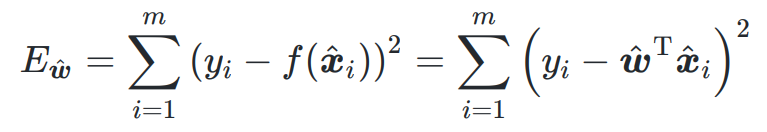
向量化
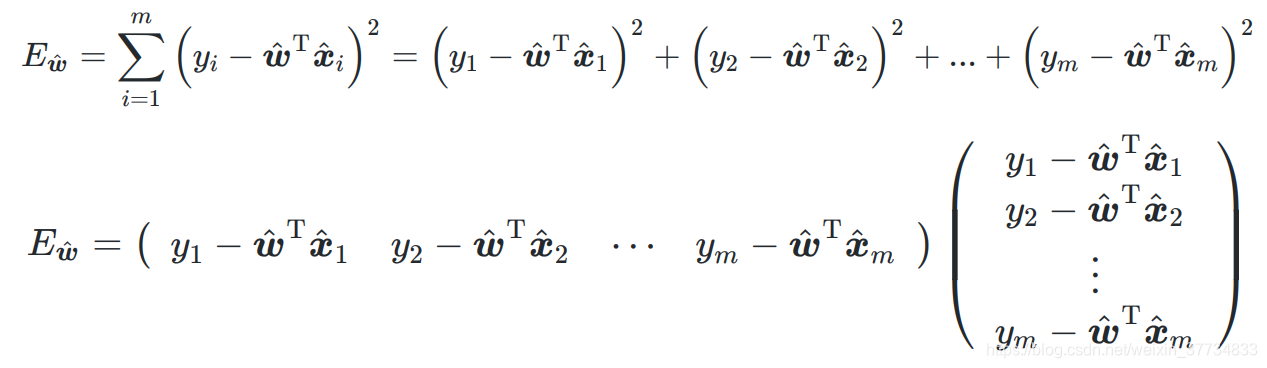
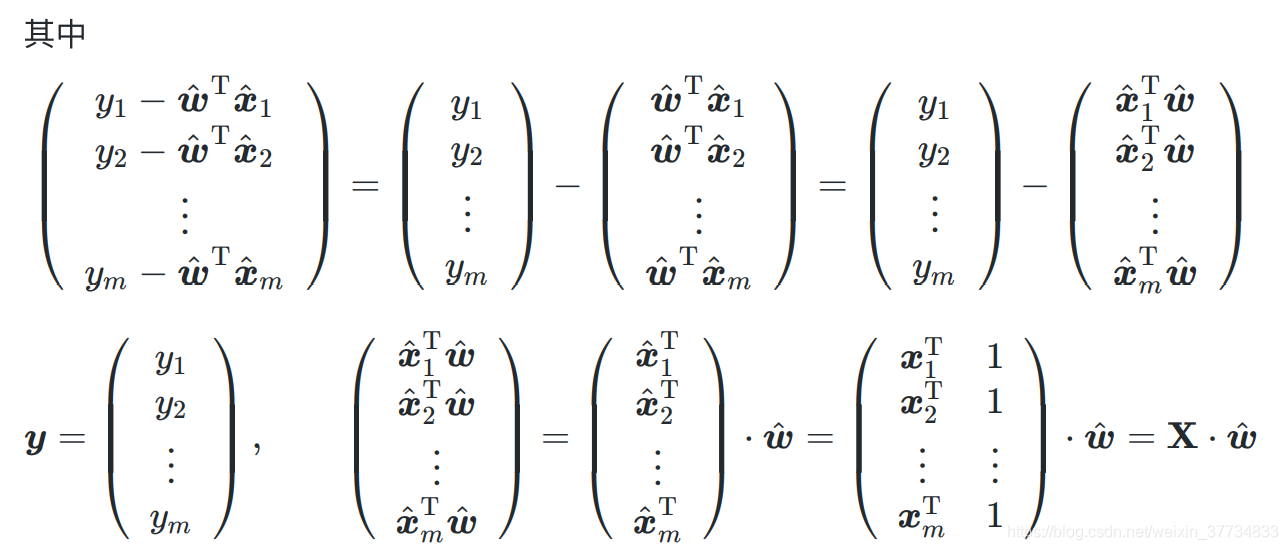
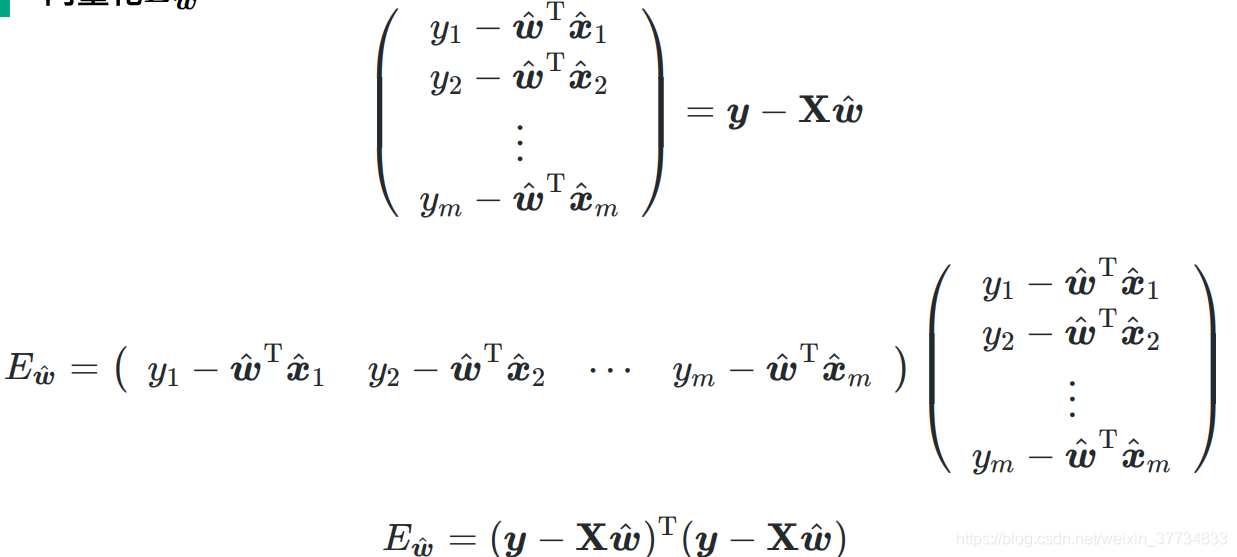
3.2.2 求解 w ^ \hat{\boldsymbol{w}} w^
- 证明凸函数,海塞矩阵求导
- 求解
证明凸函数

标量对向量(矩阵)求导,分母布局(竖)
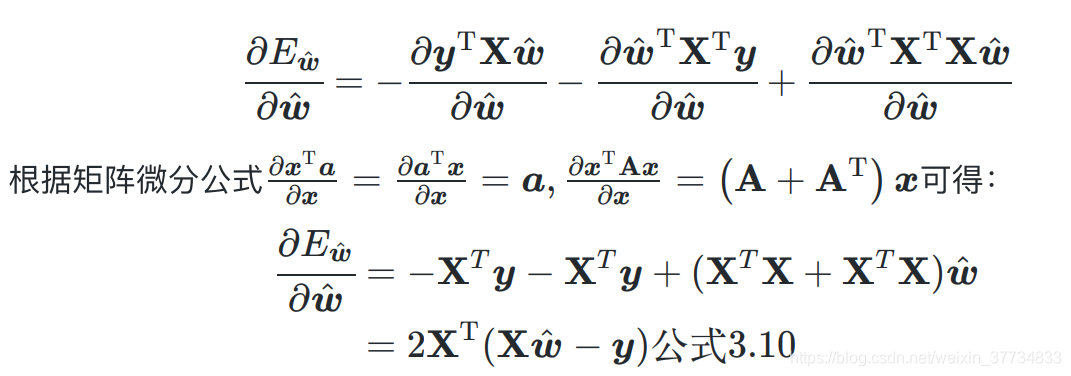

求解
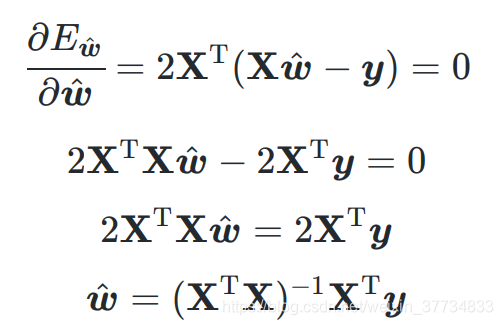
如果数据量少(一个参数最少需要一个样本),参数量太大,无法求出闭式解,会求出多个可能的解,常见的方法是正则化。
3.3 对数几率回归(逻辑回归)-用来分类
3.3.1 算法原理
要做什么?之前的线性回归可以预测出任何值,但是生活中常常需要将预测值限定在一个范围,比如预测是否就是{0,1},概率值是(0,1),因此我们可以将线性回归映射到(0,1)区间上。利用对数函数,具体来说常见的是sigmoid函数。
3.3.2 损失函数的极大似然估计推导



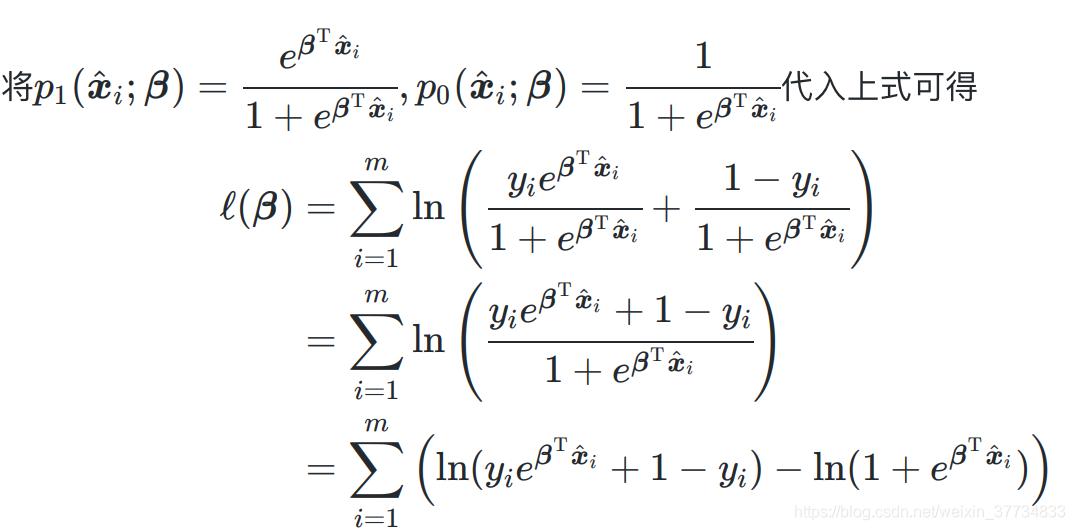

3.3.3 损失函数的信息论推导
 相对熵(KL散度)
相对熵(KL散度)
用来衡量两个分布的差异,常常用来衡量理想分布p和实际预测分布q之间的差异,用来判断当前模型预测的好坏。
D K L ( p ∥ q ) ≠ D K L ( q ∥ p ) D_{K L}(p \| q)\ne D_{K L}(q \| p) DKL(p∥q)=DKL(q∥p),两者相对熵值不同,为了统一,也常用 1 2 [ D K L ( p ∥ q ) + D K L ( q ∥ p ) ] \frac{1}{2} \left [ D_{K L}(p \| q)+D_{K L}(q \| p) \right ] 21[DKL(p∥q)+DKL(q∥p)]表示两个分布差异。

因为相对熵由两项组成,前一项是自信息,给定数据是确定值,后一项是交叉熵,因此常常用到交叉熵就可以了。最小化相对熵等价于最小化负的交叉熵(最优化一般是最小化)



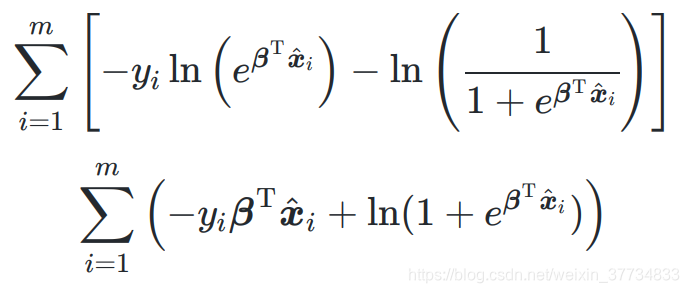
3.3.4 对数几率回归算法的机器学习三要素
- 模型:线性模型,输出值的范围为(0,1) ,近似阶跃的单调可微函数
- 策略:极大似然估计,信息论
- 算法:梯度下降,牛顿法
3.4 二分类线性判别分析LDA(linear discriminant analysis)
3.4.1 算法原理(模型)
从集合角度建模
让全体样本经过投影后,同类样例尽可能近,异类尽可能远。
怎么找到这样的投影方向?
数学角度:
- 同类样本的方差尽可能小
- 不同类样本的样本中心尽可能远
3.4.2 损失函数(策略)

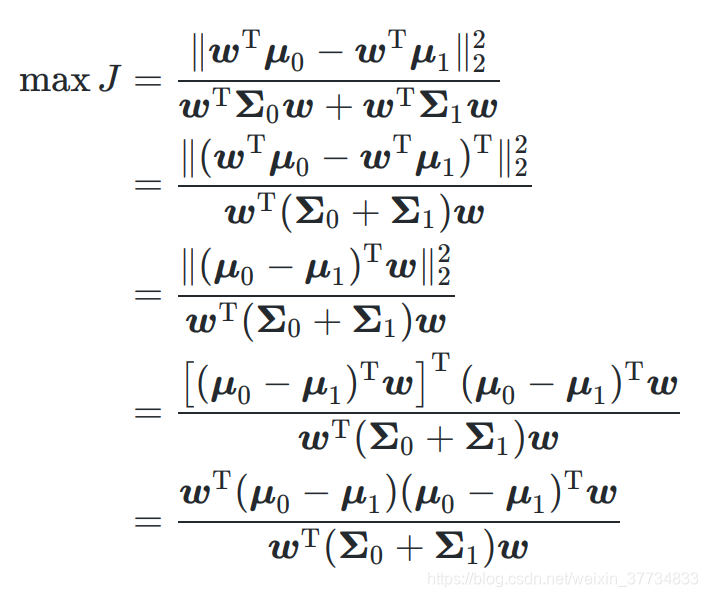
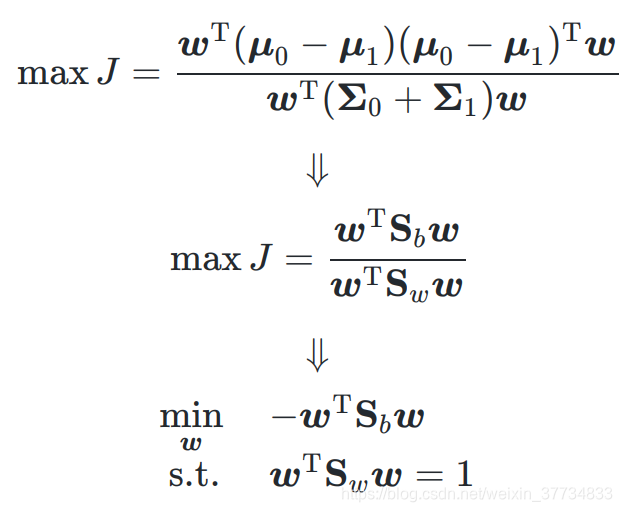
3.4.3 拉格朗日乘子法

3.4.4 求解 w w w 算法




3.4.5 广义特征值和广义瑞丽商
广义特征值

广义瑞丽商
厄米矩阵理解为对称举证就行了
















 3527
3527











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









