






在 Yann Lecun 提出 Le-Net5 之后的十几年内,由于神经网络本身较差的可解释性以及受限于计算能力的影响,神经网络发展缓慢且在较长一段时间内处于低谷。2012年,深度学习三巨头之一、具有神经网络之父之称的 Geoffrey Hinton 的学生 Alex Krizhevsky 率先提出了 AlexNet,并在当年度的 ILSVRC(ImageNet大规模视觉挑战赛)以显著的优势获得当届冠军,top-5 的错误率降至了 16.4%,相比于第二名 26.2% 的错误率有了极大的提升。这一成绩引起了学界和业界的极大关注,计算机视觉也开始逐渐进入深度学习主导的时代。
AlexNet 继承了 LeCun 的 Le-Net5 思想,将卷积神经网络的发展到很宽很深的网络当中,相较于 Le-Net5 的六万个参数,AlexNet 包含了 6 亿三千万条连接,6000 万个参数和 65 万个神经元,其网络结构包括 5 层卷积,其中第一、第二和第五层卷积后面连接了最大池化层,然后是 3 个全连接层。AlexNet 的创新点在于:
首次成功使用
relu作为激活函数,使其在较深的网络上效果超过传统的sigmoid激活函数,极大的缓解了梯度消失问题。首次在实践中发挥了
dropout的作用,为全连接层添加dropout防止过拟合。相较于之前 Le-Net5 中采用的平均池化,AlexNet 首次采用了重叠的最大池化,避免了平均池化的模糊化效果。
提出了 LRN 层,对局部神经元的活动创建了竞争机制。
使用多 GPU 进行并行计算。
采用了一定的数据增强手段,一定程度上也缓解了过拟合。
AlexNet 网络结构
以上是 AlexNet 的基本介绍和创新点,下面我们看一下 AlexNet 的网络架构。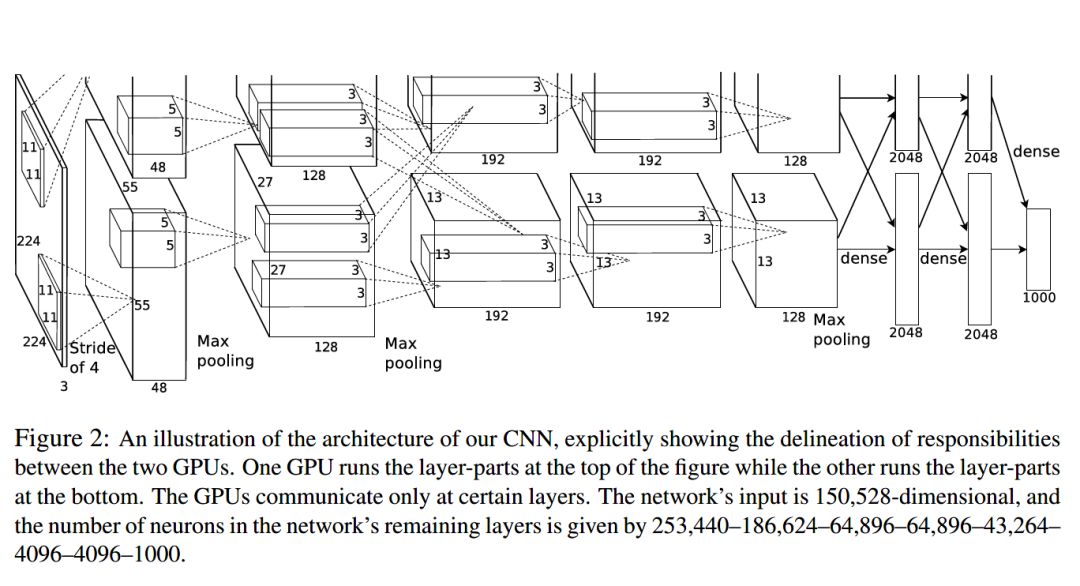
AlexNet 不算池化层总共有 8 层,前 5 层为卷积层,其中第一、第二和第五层卷积都包含了一个最大池化层,后三层为全连接层。所以 AlexNet 的简略结构如下:输入>卷积>池化>卷积>池化>卷积>卷积>卷积>池化>全连接>全连接>全连接>输出
各层的结构和参数如下:
P1层是C1后面的池化层,其输入输出结构如下:
C2层是个卷积层,其输入输出结构如下:
P2层是C2后面的池化层,其输入输出结构如下:
C3层是个卷积层,其输入输出结构如下:
C4层是个卷积层,其输入输出结构如下:
C5层是个卷积层,其输入输出结构如下:
P5层是C5后面的池化层,其输入输出结构如下:
F6层是个全连接层,其输入输出结构如下:
F7层是个全连接层,其输入输出结构如下:
F8层也是个全连接层,即输出层,其输入输出结构如下:
在论文中,输入图像大小为 224 x 224 x 3,实际为 227 x 227 x 3。各层输出采用 relu 进行激活。前五层卷积虽然计算量极大,但参数量并不如后三层的全连接层多,但前五层卷积层的作用却要比全连接层重要许多。
AlexNet 在验证集和测试集上的分类错误率表现:
AlexNet 的 tensorflow 实现
我们继续秉持前面关于利用 tensorflow 构建卷积神经网络的基本步骤和方法:定义创建输入输出的占位符变量模块、初始化各层参数模块、创建前向传播模块、定义模型优化迭代模型,以及在最后设置输入数据。
定义卷积过程
def conv(x, filter_height, filter_width, num_filters, stride_y, stride_x, name,
padding='SAME', groups=1):
# Get number of input channels
input_channels = int(x.get_shape()[-1])
# Create lambda function for the convolution
convolve = lambda i, k: tf.nn.conv2d(i, k,
strides=[1, stride_y, stride_x, 1],
padding=padding)
with tf.variable_scope(name) as scope:
# Create tf variables for the weights and biases of the conv layer
weights = tf.get_variable('weights', shape=[filter_height,
filter_width,
input_channels/groups,
num_filters])
biases = tf.get_variable('biases', shape=[num_filters])
if groups == 1:
conv = convolve(x, weights)
# In the cases of multiple groups, split inputs & weights and
else:
# Split input and weights and convolve them separately
input_groups = tf.split(axis=3, num_or_size_splits=groups, value=x)
weight_groups = tf.split(axis=3, num_or_size_splits=groups,
value=weights)
output_groups = [convolve(i, k) for i, k in zip(input_groups, weight_groups)]
# Concat the convolved output together again
conv = tf.concat(axis=3, values=output_groups)
# Add biases
bias = tf.reshape(tf.nn.bias_add(conv, biases), tf.shape(conv))
# Apply relu function
relu_result = tf.nn.relu(bias, name=scope.name)
return relu_result定义全连接层
def fc(x, num_in, num_out, name, relu=True): with tf.variable_scope(name) as scope: # Create tf variables for the weights and biases weights = tf.get_variable('weights', shape=[num_in, num_out], trainable=True) biases = tf.get_variable('biases', [num_out], trainable=True) # Matrix multiply weights and inputs and add bias act = tf.nn.xw_plus_b(x, weights, biases, name=scope.name) if relu: relu = tf.nn.relu(act) return relu else: return act定义最大池化过程
def max_pool(x, filter_height, filter_width, stride_y, stride_x, name, padding='SAME'): return tf.nn.max_pool(x, ksize=[1, filter_height, filter_width, 1], strides=[1, stride_y, stride_x, 1], padding=padding, name=name)定义 LRN
def lrn(x, radius, alpha, beta, name, bias=1.0): return tf.nn.local_response_normalization(x, depth_radius=radius, alpha=alpha, beta=beta, bias=bias, name=name)定义 dropout 操作
def dropout(x, keep_prob): return tf.nn.dropout(x,keep_prob)
以上关于搭建 AlexNet 的各个组件我们都已准备好,下面我们利用这些组建创建一个 AlexNet 类来实现 AlexNet。
class AlexNet(object):
def __init__(self, x, keep_prob, num_classes, skip_layer,
weights_path='DEFAULT'):
# Parse input arguments into class variables
self.X = x
self.NUM_CLASSES = num_classes
self.KEEP_PROB = keep_prob
self.SKIP_LAYER = skip_layer
if weights_path == 'DEFAULT':
self.WEIGHTS_PATH = 'bvlc_alexnet.npy'
else:
self.WEIGHTS_PATH = weights_path
# Call the create function to build the computational graph of AlexNet
self.create()
def create(self):
# 1st Layer: Conv (w ReLu) -> Lrn -> Pool
conv1 = conv(self.X, 11, 11, 96, 4, 4, padding='VALID', name='conv1')
norm1 = lrn(conv1, 2, 1e-04, 0.75, name='norm1')
pool1 = max_pool(norm1, 3, 3, 2, 2, padding='VALID', name='pool1')
# 2nd Layer: Conv (w ReLu) -> Lrn -> Pool with 2 groups
conv2 = conv(pool1, 5, 5, 256, 1, 1, groups=2, name='conv2')
norm2 = lrn(conv2, 2, 1e-04, 0.75, name='norm2')
pool2 = max_pool(norm2, 3, 3, 2, 2, padding='VALID', name='pool2')
# 3rd Layer: Conv (w ReLu)
conv3 = conv(pool2, 3, 3, 384, 1, 1, name='conv3')
# 4th Layer: Conv (w ReLu) splitted into two groups
conv4 = conv(conv3, 3, 3, 384, 1, 1, groups=2, name='conv4')
# 5th Layer: Conv (w ReLu) -> Pool splitted into two groups
conv5 = conv(conv4, 3, 3, 256, 1, 1, groups=2, name='conv5')
pool5 = max_pool(conv5, 3, 3, 2, 2, padding='VALID', name='pool5')
# 6th Layer: Flatten -> FC (w ReLu) -> Dropout
flattened = tf.reshape(pool5, [-1, 6*6*256])
fc6 = fc(flattened, 6*6*256, 4096, name='fc6')
dropout6 = dropout(fc6, self.KEEP_PROB)
# 7th Layer: FC (w ReLu) -> Dropout
fc7 = fc(dropout6, 4096, 4096, name='fc7')
dropout7 = dropout(fc7, self.KEEP_PROB)
# 8th Layer: FC and return unscaled activations
self.fc8 = fc(dropout7, 4096, self.NUM_CLASSES, relu=False, name='fc8')
def load_initial_weights(self, session):
# Load the weights into memory
weights_dict = np.load(self.WEIGHTS_PATH, encoding='bytes').item()
# Loop over all layer names stored in the weights dict
for op_name in weights_dict:
# Check if layer should be trained from scratch
if op_name not in self.SKIP_LAYER:
with tf.variable_scope(op_name, reuse=True):
# Assign weights/biases to their corresponding tf variable
for data in weights_dict[op_name]:
# Biases
if len(data.shape) == 1:
var = tf.get_variable('biases', trainable=False)
session.run(var.assign(data))
# Weights
else:
var = tf.get_variable('weights', trainable=False)
session.run(var.assign(data))在上述代码中,我们利用了之前定义的各个组件封装了前向计算过程,从 http://www.cs.toronto.edu/~guerzhoy/tf_alexnet/上导入了预训练好的模型权重。这样一来,我们就将 AlexNet 基本搭建好了。
参考资料:
Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks[C]// International Conference on Neural Information Processing Systems. Curran Associates Inc. 2012:1097-1105.
https://github.com/kratzert/finetune_alexnet_with_tensorflow
往期精彩:
一个数据科学从业者的学习历程
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









