






将自然语言文本转换为 SQL:利用 RAG 和 LLM 进行精确查询
在 RAG 和 LLM(Gemini-pro、paLM 2)的帮助下,使用嵌入和提示工程构建可执行 SQL 查询,以从您自己的自定义数据源中检索数据。
在快速发展的人工智能 (AI) 领域,生成式 AI 与大型语言模型 (LLM) 的结合已成为改变游戏规则的因素,为各个领域提供了变革性的能力。最近的进展引发了关于生成式 AI 重新定义人工智能本质的潜力的讨论。

生成式人工智能包括一类能够通过多种媒介(从文本和对话到视觉效果和音乐)生成原创内容和概念的人工智能。这些人工智能系统在图像识别、自然语言理解和翻译等任务中模拟人类智能。另一方面,**大型语言模型 (LLM)**代表了一种特定形式的人工智能,旨在理解和生成文本等功能。这些模型使用机器学习技术(尤其是 Transformer 模型架构)在海量数据集上进行训练。
然而,一个关键问题出现了:*我们如何利用生成式 AI 和 LLM 的强大功能来为特定数据源或数据集量身定制解决方案?*一种潜在的应用是利用 LLM 从简单文本构建 SQL 查询并从数据源中检索相关数据。这种方法称为检索增强生成 (RAG),有望简化文本到 SQL 转换和数据检索等流程。
在本文中,我们将深入探讨使用 RAG 根据用户输入问题将文本查询转换为 SQL 查询的复杂性。通过动态构建 SQL 查询以响应用户查询,我们旨在展示这种方法在促进与数据库的无缝交互和增强数据检索过程方面的潜力。
什么是检索增强生成 (RAG)?
检索增强生成 (RAG) 是一种变革性的 AI 框架,旨在通过整合外部知识源来提高大型语言模型 (LLM) 的功效。通过将 LLM 的响应植根于这些外部信息存储库,RAG 旨在丰富模型的理解并增强其生成准确且与上下文相关的内容的能力。在基于 LLM 的问答系统中实施 RAG 有两个关键优势:首先,它确保访问最新和最值得信赖的事实,从而增强模型响应的可靠性。其次,通过提供有关模型来源的透明度,RAG 使用户能够验证其声明的准确性,从而对 AI 生成的输出产生信任感和信心。无论您是研究人员、学生还是知识寻求者,RAG 都能提供直观和智能的帮助,帮助您提取有价值的见解、进行分析和做出明智的决策。借助 RAG,用户可以充分发挥其数据资源的潜力,实现不同领域的创新、生产力和成功。
RAG 如何工作?
RAG 通过一个简化的过程进行运作,该过程无缝结合信息检索和生成技术,为用户查询提供准确且与上下文相关的响应。
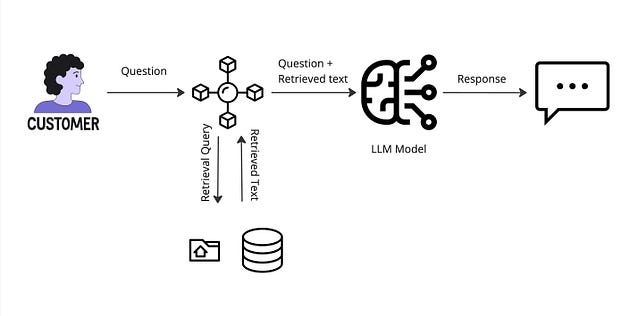
RAG 架构
以下是 RAG 工作原理的详细说明:
*步骤 1:用户查询*
当用户向 RAG 系统提出问题时,该过程开始。
*第 2 步:信息检索*
收到用户查询后,RAG 的检索器组件会快速从各种来源搜索和检索相关信息。这些信息可能来自互联网、内部数据库或其他数据存储库。
*步骤 3:上下文增强*
检索到的信息随后作为附加上下文增强到原始查询中。增强后的上下文丰富了对查询的理解,并为生成全面的响应提供了有价值的背景信息。
*步骤 4:生成响应*
在增强上下文到位后,RAG 的语言模型组件将根据用户查询和增强上下文的组合输入生成响应。利用其庞大的知识库和自然语言处理能力,LLM 可以制定出信息丰富且符合语境的答案。
使用 RAG 的优势
RAG 的一个主要优势是它能够通过 Retriever 组件访问来自外部源的数据。与传统模型不同,RAG 可以从未经明确训练的来源检索信息,从而扩大其知识库的范围和多功能性。此功能使 RAG 能够提供更全面、更准确的响应,使其成为各个领域信息检索和生成的强大工具。
使用 RAG 的另一个优点是避免幻觉。在 LLM 领域,幻觉指的是模型产生的内容看似可信,但缺乏准确性或事实依据的情况。假设使用传统方法,你根据数据集向 LLM 模型询问有关特定数据的问题。未在该数据集上进行训练的 LLM 会产生幻觉,并通过它在互联网上找到的任何内容给出基于问题的数据,而不是特定于你拥有的数据集。RAG 有可能通过整合来自外部知识源的检索机制来减轻 LLM 中的幻觉。
现在我们已经掌握了 RAG 的本质,让我们探索它的实时应用。
使用 RAG 掌握文本到 SQL 转换的艺术
在这种利用生成式 AI 进行文本到 SQL 转换的实用方法中,我们利用由大型语言模型 (LLM)(如 Gemini-Pro 和 Text-Bison 模型)驱动的最先进的生成式 AI,精确高效地将自然语言文本转换为可执行的 SQL 查询。
该方法主要利用嵌入方法(将单词作为数值向量)来查找问题中最接近的匹配实体,然后使用它们来构建我们的 SQL 查询。一旦我们获得匹配的实体,我们就会使用提示工程来要求模型创建 SQL 查询。这种方法不仅有助于高效查询和数据分析,而且还为从数据分析到对话式 AI 等不同领域的数据驱动决策开辟了新的可能性。
什么是嵌入以及嵌入方法是什么?
假设您拥有来自在线市场的大量产品评论,其中包含客户对各种产品的宝贵反馈。每条评论都是一段冗长的文字,表达了对特定商品的意见、体验和感受。
现在,为了理解这些信息宝库,您决定将每条评论分解成更小、更易于管理的块。然后,您为这些块编制索引,并将它们转换为称为嵌入的数字表示。这些嵌入在高维向量空间中捕获文本的语义和上下文。
例如,句子
“相机质量非常好,但电池寿命可以更长”
可能被表示为该嵌入空间中的数值向量。
: [ 0.035, -0.012, 0.018, ... ]
相机: [ -0.024, 0.043, 0.017, ... ]
质量: [ 0.032, -0.021, 0.015, ... ]
是: [ 0.011, -0.027, 0.036, ... ]
优秀,: [ 0.038, -0.009, 0.025, ... ]
但: [ -0.014, 0.037, 0.019, ... ]
电池: [ 0.021, -0.032, 0.024, ... ]
寿命: [ -0.028, 0.015, 0.022, ... ]
可能: [ 0.016, -0.035, 0.031, ... ]
是: [ -0.008, 0.041, 0.013, ... ]
更好: [ 0.027, -0.018, 0.029, ... ]
一旦有了这些嵌入,就可以将它们存储在矢量数据库中,以便随时进行分析。
现在,假设客户想要了解特定相机型号的性能。您可以利用嵌入的强大功能,而不必手动筛选数百或数千条评论。
当客户提交他们的查询(例如*“相机性能”)*时,您可以将此查询转换为其相应的嵌入表示。
接下来,您将对查询的嵌入和数据库中的块嵌入进行相似性检查。此过程将计算查询和每个评论块之间的相似度得分。
最后,您根据相似度得分检索前“k”个最相关的评论块。这些块包含与客户查询特别相关的见解,使您能够提供有针对性的个性化响应,而无需进行详尽的手动搜索。
通过这种方式,嵌入可以成为一种强大的工具,可以有效地从大型文本数据集中导航和提取有价值的信息,从而实现更有效的决策和知识发现。
现在,事情变得非常有趣。这些顶级块不会原封不动地交给你。它们会与你的原始查询一起输入到大型语言模型 (LLM) 中。这一步至关重要,因为它允许 LLM 不仅考虑查询本身,还考虑最相关的文档块提供的上下文。
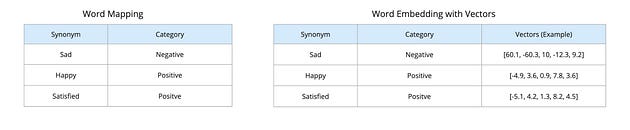
嵌入
为了更好地理解这种嵌入方法,让我们考虑一个更简单的场景。假设你有一个任务,根据单词的情绪对单词进行分类——无论它们传达的是积极还是消极的含义。例如,“悲伤”这个词可能被归类为消极的,而“积极”显然属于积极的类别。
抑郁 = [62.1,-59.3,12,-12.6,10.3](仅为示例向量)
我们来介绍一下“沮丧”这个词。
它没有在我们的情绪映射中明确列出,但使用嵌入方法,我们仍然可以对其进行分类。怎么做?
通过在我们的词向量数据库中找到最接近的匹配项。在本例中,“沮丧”与“悲伤”紧密相关,因此我们的模型将其归类为负面。
这种根据单词嵌入对单词进行分类的能力提供了极大的灵活性。我们可以考虑单词的同义词或变体,这些同义词或变体可能并不明确存在于我们的数据库中。这意味着我们的模型不受其所知道的单词的限制;它可以理解和分类超出其初始训练数据的概念。
我们如何创建嵌入?
嵌入可以通过多种方式创建。
- Word2Vec:将单词表示为连续向量空间中的密集向量,使用 CBOW 或 skip-gram 架构进行训练。
- FastText:通过考虑子词信息扩展 Word2Vec,使其能够处理词汇表之外的单词并捕获形态信息。
- GloVe:使用矩阵分解,根据语料库中的单词共现统计构建词嵌入。
- Doc2Vec:扩展 Word2Vec 以生成整个文档或句子的嵌入,从而促进相似性比较和文档聚类。
- BERT:预训练语言模型,通过考虑句子上下文来生成上下文词嵌入,利用转换器架构进行深度语境化表示。
- Faiss:用于高效相似性搜索和密集向量聚类的库,通常与嵌入方法一起用于在高维空间中快速进行最近邻搜索。
导入spacy
从gensim.models导入Word2Vec
nlp = spacy.load( “en_core_web_sm” )
sentence = “相机质量非常好,但电池寿命可以更好”
tokens = [token.text.lower() for token in nlp(sentence)]
data = [tokens]
model = Word2Vec(data, min_count= 1 )
embeddings = {token: model.wv[token] for token in tokens}
for token, embedding in embeddings.items():
print ( f “ {token} : {embedding} ” )
使用嵌入方法 + 提示工程来框架 SQL 查询

应用程序 RAG 架构
上图是我们解决方案的架构。让我们通过一个例子逐步分解并理解它。
假设我们有一个名为 Company_Data 的数据库,其中包含 3 列,如下所示。
创建 表公司数据(
公司名称字符串、
情绪字符串、
类别字符串
);
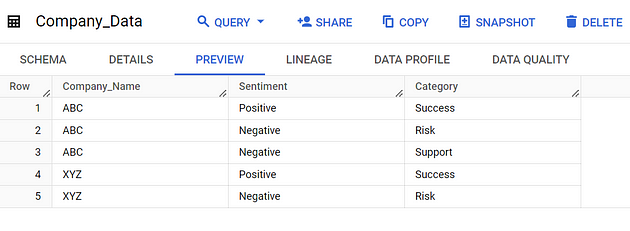
*步骤1:用户查询*
用户提出问题
问题:“XYZ 公司在 2023 年将取得哪些胜利”
参照数据库,我们看到与此最接近的答案是第 4 行,其中公司名称为“XYZ”,类别为“成功”,情绪为“积极”,因为问题中出现了***“胜利”这个词。***
*第 2 步:带提示的嵌入和 LLM 模型*
下一步是将我们的问题传递给嵌入函数,以检索可用于构建 SQL 问题的最接近的单词匹配。
由于我们处理 3 个不同的列,因此我们为每一列创建 3 个不同的嵌入函数。
导入openai
导入pandas作为pd
从vertexai.language_models导入TextGenerationModel
从vertexai.preview.generative_models导入GenerativeModel
从google.cloud导入bigquery
def company_embedding_value(问题):
[代码在这里]
def category_embedding_value(问题):
[代码在这里]
def sentiment_embedding_value(问题):
[代码在这里]
prompt= """
"""
company_name=company_embedding_value(question)
sentiment=sentiment_embedding_value(question)
category=category_embedding_value(question)
def company_embedding_value ( question ):
query_str = """
SELECT query.query, base.Category
FROM VECTOR_SEARCH(
[您的主要代码以及 ML/Embedding 模型]
top_k => 10, options => '{"fraction_lists_to_search": 0.01}'
)
"""
job_config = #根据嵌入的存储位置定义您的作业配置。
query_job = #执行查询以获取最接近的匹配。
first_closest = [row.Company_Name for row in results][ 0 ]
return first_closest
从这个例子中,这些是嵌入函数将返回的值:
company_name = 'XYZ'
情绪 = '积极'
类别 = '成功'
*步骤3:使用SQL提示将embedding_values传递给最终的LLM模型。*
现在我们有了值,我们可以将它们直接传递给最终函数,这将有助于形成 SQL 查询。
def form_sql ( question, company_name, sentiment, category ):
args = """
[输入]: "[公司]:{}, [情绪]: {}, [类别]: {}"
[输出]:
"""
schema = """
CREATE TABLE Company_Data if not exist (
Company_Name String,
Sentiment String,
Category String
);
"""
prompt = f"""
您是一位查询公司数据的专家 SQL 开发人员。
您必须根据用户的问题在 [Database-name] 数据库中编写 SQL 代码。
对每个查询使用此基本模板:Select * from Company_Data WHERE ... 。
这是您正在使用的架构:[SCHEMA]: {schema}。
仅当问题中引用日期时才添加日期过滤器。
提出的问题是:{question}。要回答这个问题,我们需要将这些列添加到 WHERE 条件中:
"""
if company_name:
prompt += f"我们将添加event_company 添加到我们的 WHERE 条件中。从问题中,我们有,公司名称是:{company_name} \n"
if sentiment:
prompt += f"我们将在 WHERE 条件中添加情绪。从问题中,我们有,情绪是:{sentiment} \n"
if category:
prompt += f"我们将在 WHERE 条件中添加分类。从问题中,我们有,分类是:{category} \n"
prompt += "请不要使用您自己的逻辑,也不要向 WHERE 条件中添加除这些之外的任何其他列。"
result = [您的 llm 模型].predict(prompt)
return result.text
最终结果如下

输出图像
这只是一个简单的示例,说明如何使用生成式 AI 构建 SQL 查询以进行精确查询。此应用程序可以处理大量数据,其中可以以多种不同的方式提出问题。您可以将数据提取到数据源中,创建和存储嵌入,然后访问它并将其提供给您的 LLM 模型以获取或检索数据。
未来的应用
现在我们有了 SQL 查询,我们可以用它做更多的事情:
- 文本摘要
- 数据分析
- 创建仪表板和可视化
- 作出预测
结论
总之,生成式人工智能和大型语言模型 (LLM) 与检索增强生成 (RAG) 的融合为彻底改变数据查询和检索领域提供了前所未有的机会。通过将文本到 SQL 转换等最先进的技术与先进的人工智能架构无缝集成,我们可以充分发挥数据源的潜力,同时确保信息提取的准确性、效率和可靠性。
嵌入的强大功能与快速工程相结合,使我们能够弥合自然语言查询和 SQL 命令之间的差距,促进与数据库的动态交互并增强跨不同领域的决策能力。借助 RAG,用户可以利用外部知识库的集体智慧,确保访问最新且与上下文相关的信息。
分析
3. 创建仪表板和可视化
4. 作出预测
结论
总之,生成式人工智能和大型语言模型 (LLM) 与检索增强生成 (RAG) 的融合为彻底改变数据查询和检索领域提供了前所未有的机会。通过将文本到 SQL 转换等最先进的技术与先进的人工智能架构无缝集成,我们可以充分发挥数据源的潜力,同时确保信息提取的准确性、效率和可靠性。
嵌入的强大功能与快速工程相结合,使我们能够弥合自然语言查询和 SQL 命令之间的差距,促进与数据库的动态交互并增强跨不同领域的决策能力。借助 RAG,用户可以利用外部知识库的集体智慧,确保访问最新且与上下文相关的信息。
此外,RAG 不仅提高了人工智能生成的响应的准确性和全面性,还通过允许用户验证信息来源来提高信任度和透明度。无论是进行复杂的分析、提取有价值的见解,还是做出数据驱动的决策,RAG 都能为用户提供直观和智能的帮助,为不断发展的人工智能领域的创新和成功铺平道路。
博客原文:专业人工智能社区

















 859
859

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









