






按步教你玩转CPT-SoVITS-克隆复制好友的声音-保姆级教程
整合包教程
文末有新版整合包下载链接可以先到文末下载好跟着文章一步一步完成声音克隆
在开始之前
为了避免在之后的使用中出现各种意料之外的问题,请务必对照下面的 Checklist 检查本机环境。
关闭全局梯子 / 绕过局域网
使用推荐的浏览器(✅Chrome / Edge / Firefox)
关闭浏览器自带的网页翻译功能
关闭所有第三方杀毒软件 / 安全卫士等
如果内存吃紧,将系统虚拟内存设置为自动
建议关闭共享显存,教程:
关闭共享显存
win11关闭GPU加速,貌似有占用不满的bug
部分浏览器(尤其是 Edge)会出现 WebUI 打开后无法正常工作的现象。如果遇到卡死/无法点击交互等现象,请尝试更换为上述推荐的其他浏览器。
版本说明:
GPT-SoVITS-V1于2024年1月发布,V2于2024年8月7日发布,8月7日前的整合包都为V1版,V1版的后缀为beta,V2版的后缀为V2,四位数字表示更新日期,如:GPT-SoVITS-beta0706fix1是在7月6号更新的V1版整合包,GPT-SoVITS-V2-0807是在8月7号更新的V2版整合包。V1将不再更新,最终版本是0706fix1,V2还在持续更新中。
V2的特点
对低音质参考音频合成出来音质更好
底膜训练集增加到5k小时,zero shot性能更好音色更像,所需数据集更少
增加韩粤两种语言,中日英韩粤5个语种均可跨语种合成
更好的文本前端:持续迭代更新。V2中英文加入多音字优化。
1.下载并更新
完整整合包(选择最新的下载)
百度网盘:
https://pan.baidu.com/s/1OE5qL0KreO-ASHwm6Zl9gA?pwd=mqpi
提取码:mqpi
1.1:下载
1.1.2:百度网盘(要会员)

有百度网盘会员的可以选择百度网盘,修改日期就是更新时间。打开V2文件夹,勾选压缩包,点击右上角的下载后自动跳转到百度网盘客户端。如果没有客户端的先下载一个客户端。
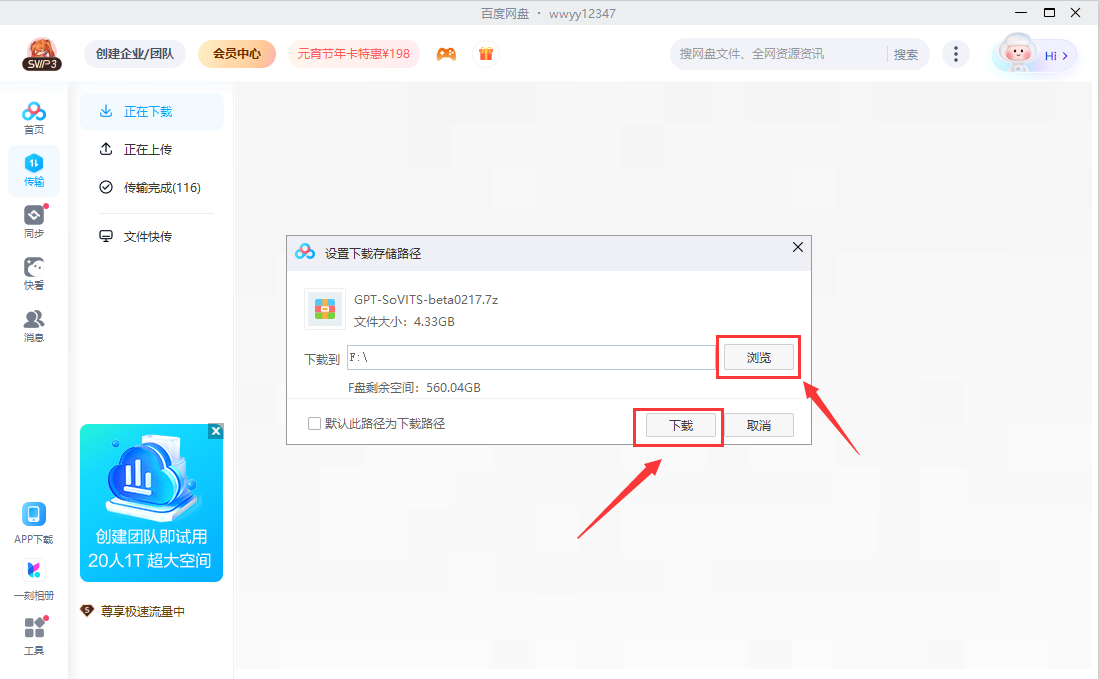
2:解压并打开
2.1:解压
请使用7-Zip解压!其他解压工具可能会吞文件,比如360解压、Windows自带的解压、2345好压等很多解压工具都会吞文件!
官网英文原版下载:https://www.7-zip.org/download.html
汉化版直链下载:https://423down.lanzouo.com/i9Sn922czite
解压方法:
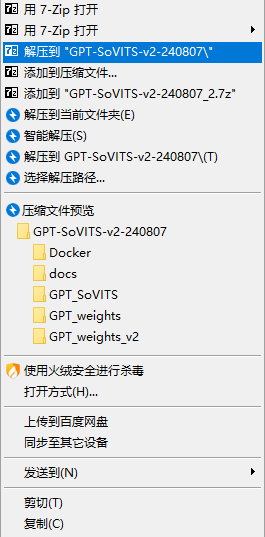
2.2:打开
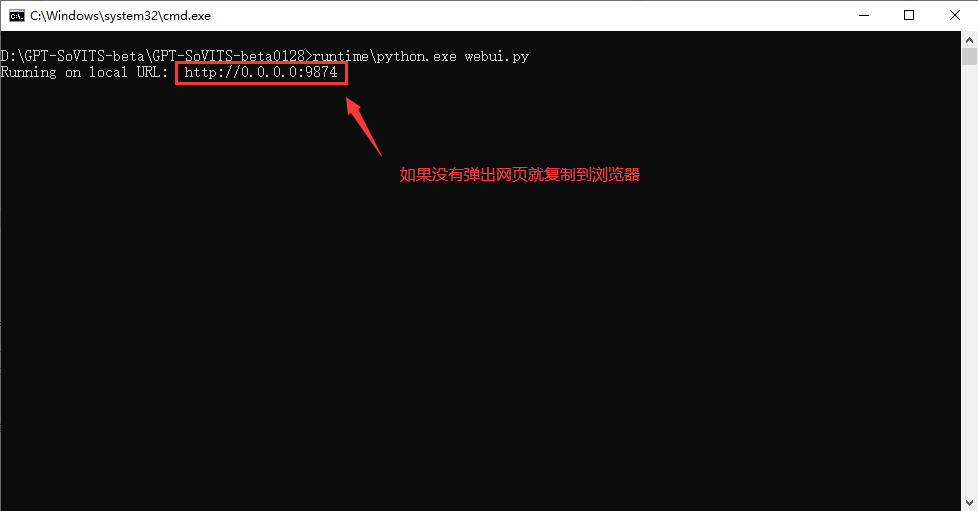
打开文件来到根目录,双击go-webui.bat打开,不要以管理员身份运行!
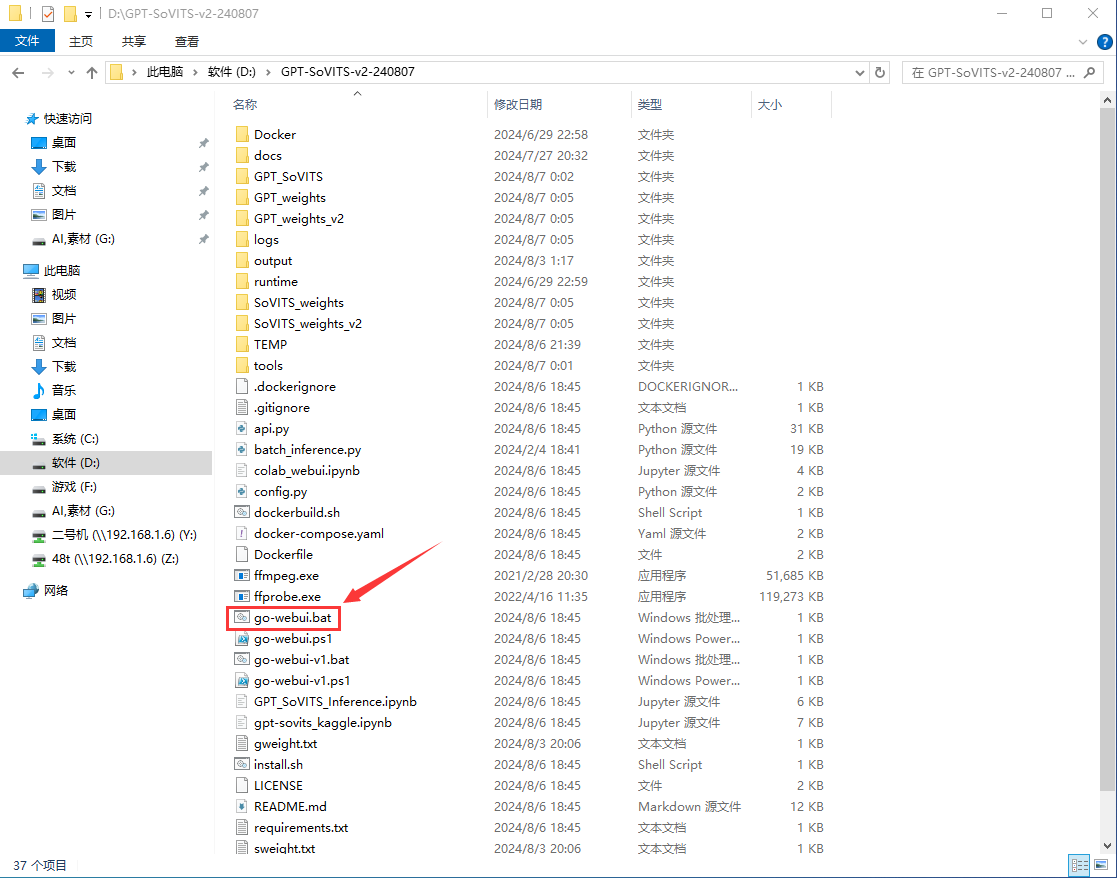
如果没有.bat的后缀可以在查看里打开文件扩展名,后面也会遇到很多需要后缀的

这就是正常打开了,稍加等待就会弹出网页。如果没有弹出网页可以复制http://0.0.0.0:9874到浏览器打开
如果没有弹出网页就复制到浏览器
这就是网页端
在开始使用前先提醒一下大家:打开的bat不可以关闭!这个黑色的bat框就是控制台,所有的日志都会在这上面呈现,所有的信息以控制台为准。如果要向别人提问请写清楚:哪一步骤+网页端(方便看你填没填对)+控制台截图!所有的报错都在控制台上!你不给别人看控制台谁也不知道你是什么问题!Error后面的一般是报错
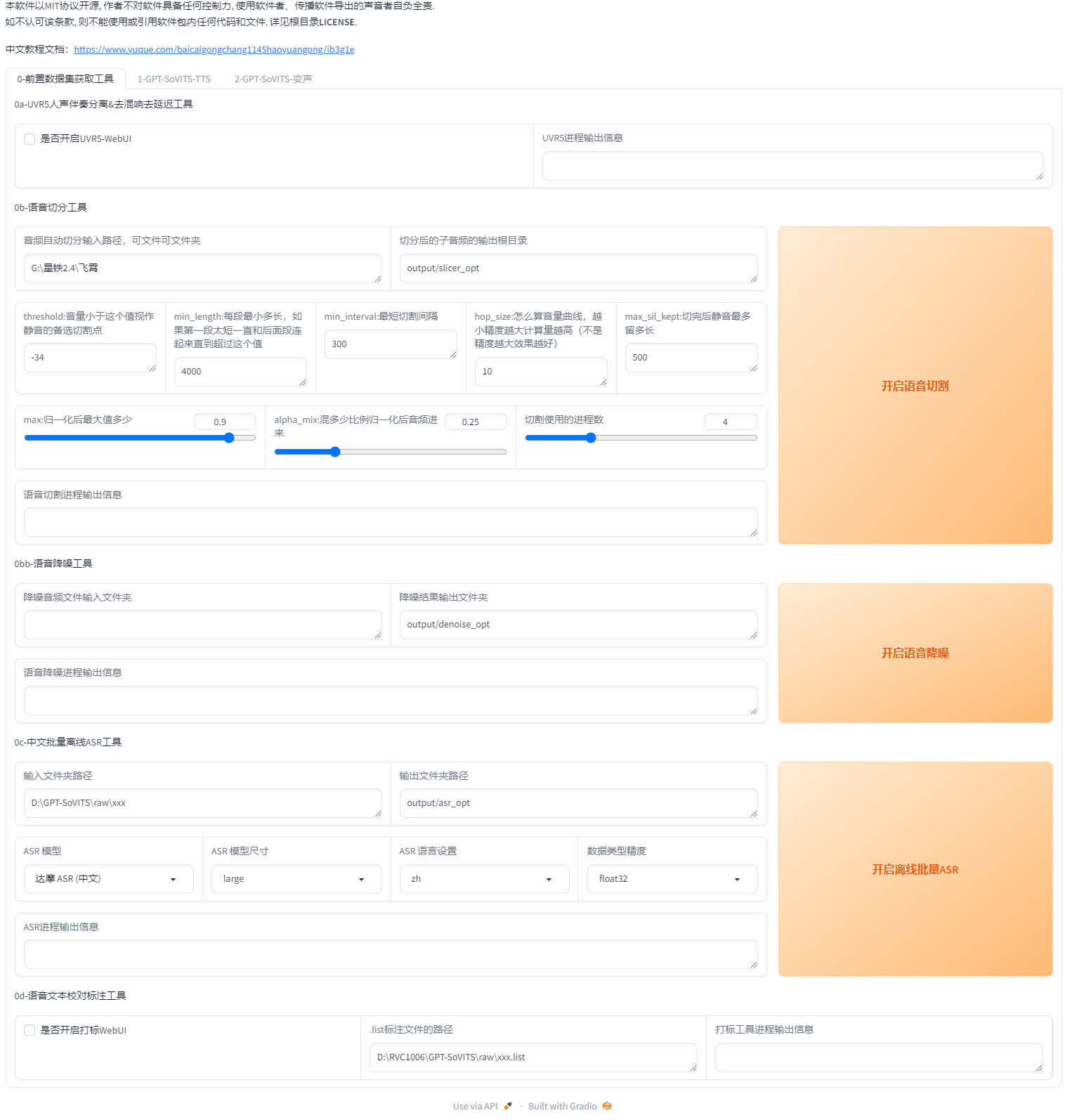
3:数据集处理
请认真准备数据集!以免后面出现各种报错,和炼出不理想的模型!好的数据集是炼出好的模型的基础!
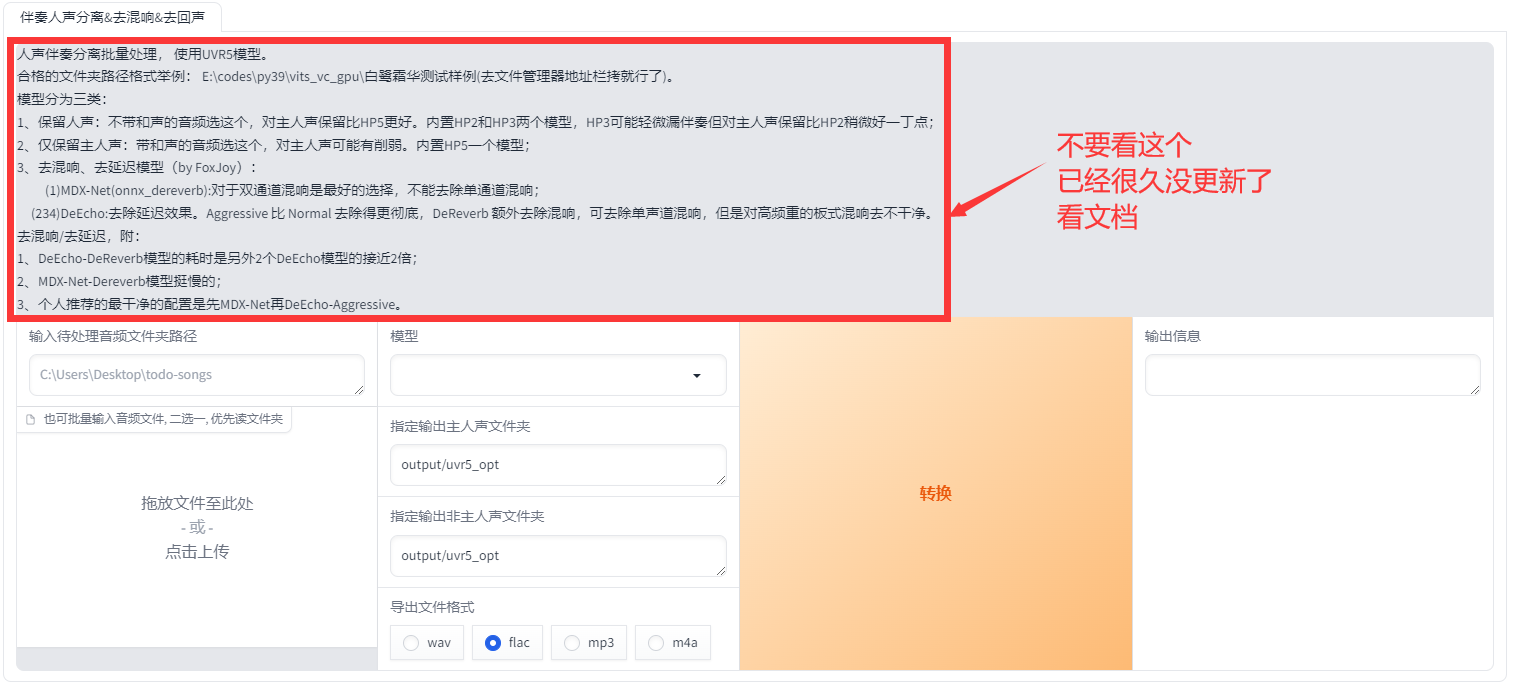
3.1:使用UVR5处理原音频(如果原音频足够干净可以跳过这步,比如游戏中提取的干声)
3.1.1:方法1:用自带的UVR5处理音频
点击开启UVR5-WebUI稍加等待就会自动弹出图二的网页,如果没有弹出复制http://0.0.0.0:9873到浏览器打开

首先输入音频文件夹路径或者直接选择文件(2选1)
文件夹上面那个地址框就是文件夹路径
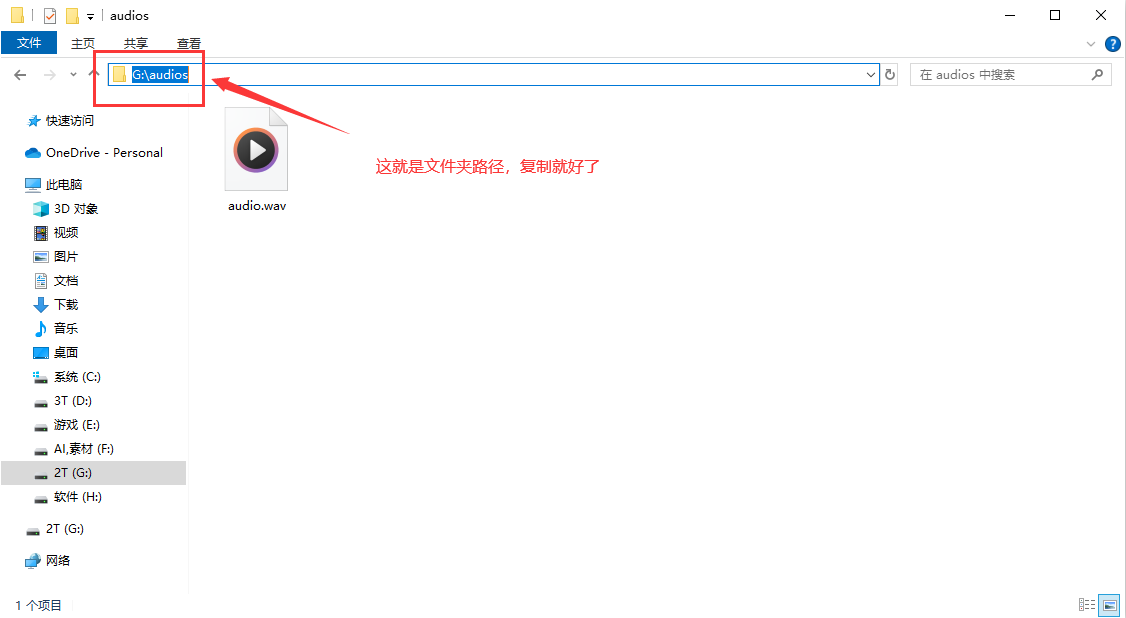
如果要复制文件路径就是这样↓
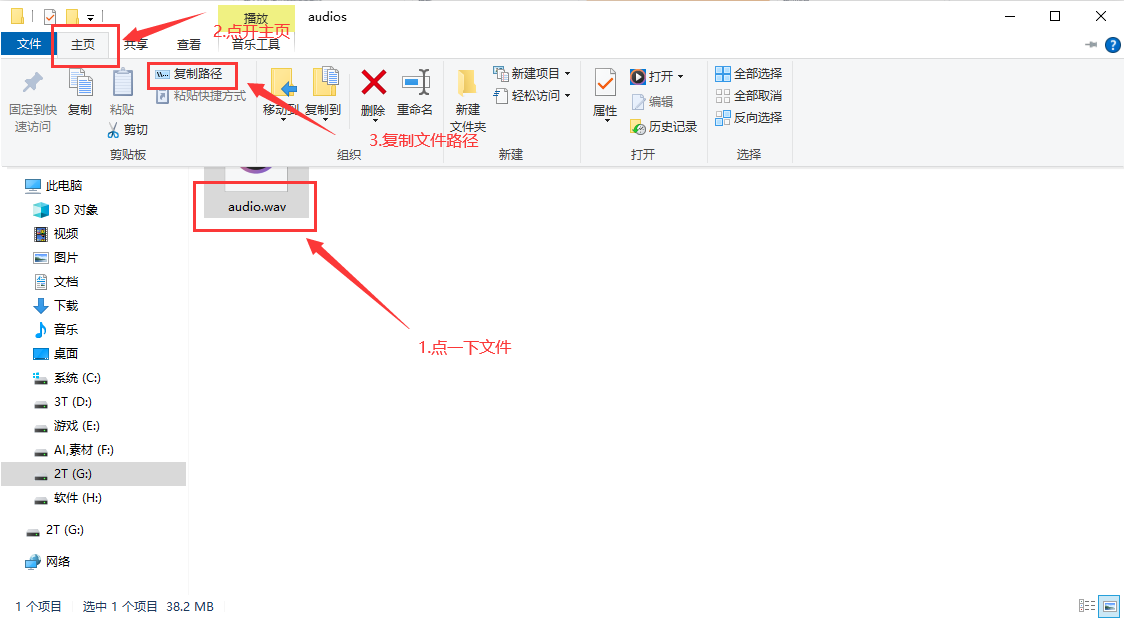
先用model_bs_roformer_ep_317_sdr_12.9755模型(已经是目前最好的模型)处理一遍(提取人声),然后将输出的干声音频再用onnx_dereverb最后用DeEcho-Aggressive(去混响),输出格式选wav。输出的文件默认在GPT-SoVITS-beta\output\uvr5_opt这个文件夹下,建议不要改输出路径,到时候找不到文件谁也帮不了你。处理完的音频(vocal)的是人声,(instrument)是伴奏,(No Reverb)的没混响的,(Reverb)的是混响。(vocal)(No Reverb)才是要用的文件,其他都可以删除。结束后记得到WebUI关闭UVR5节省显存。
如果没有成功输出,报错了(现在版本应该不会报错了)。
那么推荐使用下面一种方法——UVR5客户端。(✅可能兼容性有问题,但是效果是和UVR5对齐的,不要瞎黑内置工具效果有问题)
报错原因
3.1.2:方法2:使用UVR5客户端(没有bug,模型更多)
3.1.3:方法3:MDX23C(MAC用户暂时用)
3.2:切割音频
在切割音频前建议把所有音频拖进音频软件(如au、剪映)调整音量,最大音量调整至-9dB到-6dB,过高的删除
首先输入原音频的文件夹路径(不要有中文),如果刚刚经过了UVR5处理那么就是uvr5_opt这个文件夹。然后建议可以调整的参数有min_length、min_interval和max_sil_kept单位都是ms。min_length根据显存大小调整,显存越小调越小。min_interval根据音频的平均间隔调整,如果音频太密集可以适当调低。max_sil_kept会影响句子的连贯性,不同音频不同调整,不会调的话保持默认。其他参数不建议调整。点击开启语音切割,马上就切割好了。默认输出路径在output/slicer_opt。当然也可以使用其他切分工具切分。
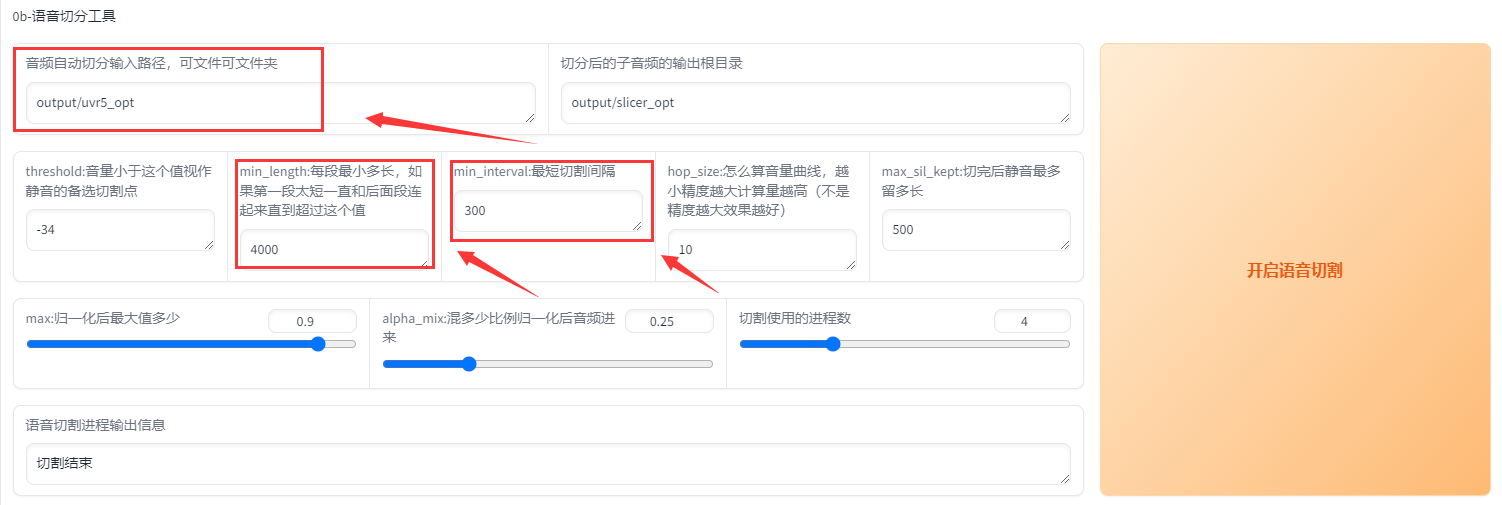
切分完后文件在output\slicer_opt。打开切分文件夹,排序方式选大小,将时长超过 显存数 秒的音频手动切分至 显存数 秒以下。比如显卡是4090 显存是24g,那么就要将超过24秒的音频手动切分至24s以下,音频时长太长的会爆显存。如果语音切割后还是一个文件,那是因为音频太密集了。可以调低min_interval,从300调到100基本能解决这问题。实在不行用au手动切分。
3.3:音频降噪
(如果原音频足够干净可以跳过这步,比如游戏中提取的干声)
如果你觉得你的音频足够清晰可以跳过这步,降噪对音质的破坏挺大的,谨慎使用。
输入刚才切割完音频的文件夹,默认是output/slicer_opt文件夹。然后点击开启语音降噪。默认输出路径在output/denoise_opt。

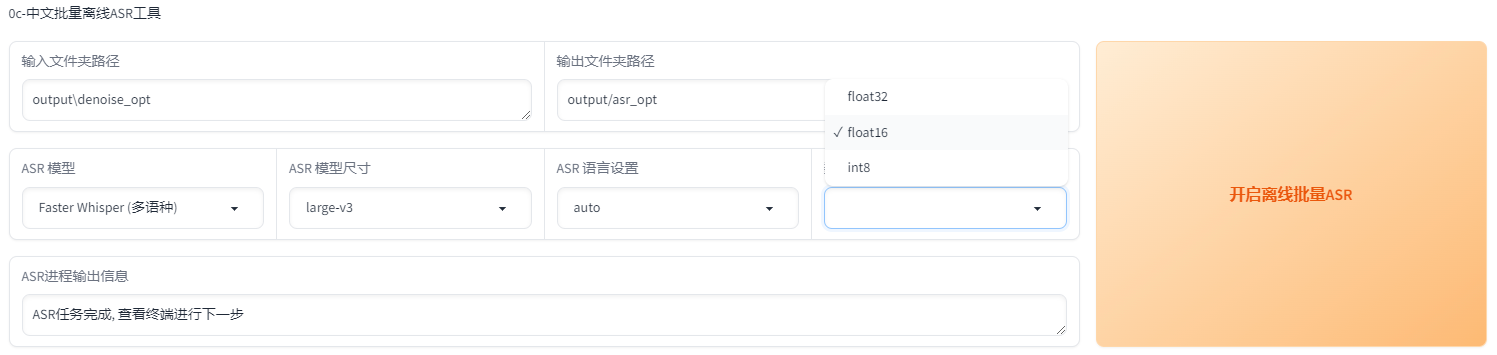
3.4:打标
为什么要打标:打标就是给每个音频配上文字,这样才能让AI学习到每个字该怎么读。这里的标指的是标注
如果你上一步切分了或者降噪了,那么已经自动帮你填充好路径了。然后选择达摩ASR或者fast whisper。达摩ASR只能用于识别汉语和粤语,效果也最好。fast whisper可以标注99种语言,是目前最好的英语和日语识别,模型尺寸选large V3,语种选auto自动。whisper可以选择精度,建议选float16,float16比float32快,int8速度几乎和float16一样。然后点开启离线批量ASR就好了,默认输出是output/asr_opt这个路径。ASR需要一些时间,看着控制台有没有报错就好了
如果有字幕的可以用字幕标注,准确多了。内嵌字幕或者外挂字幕都可以教程
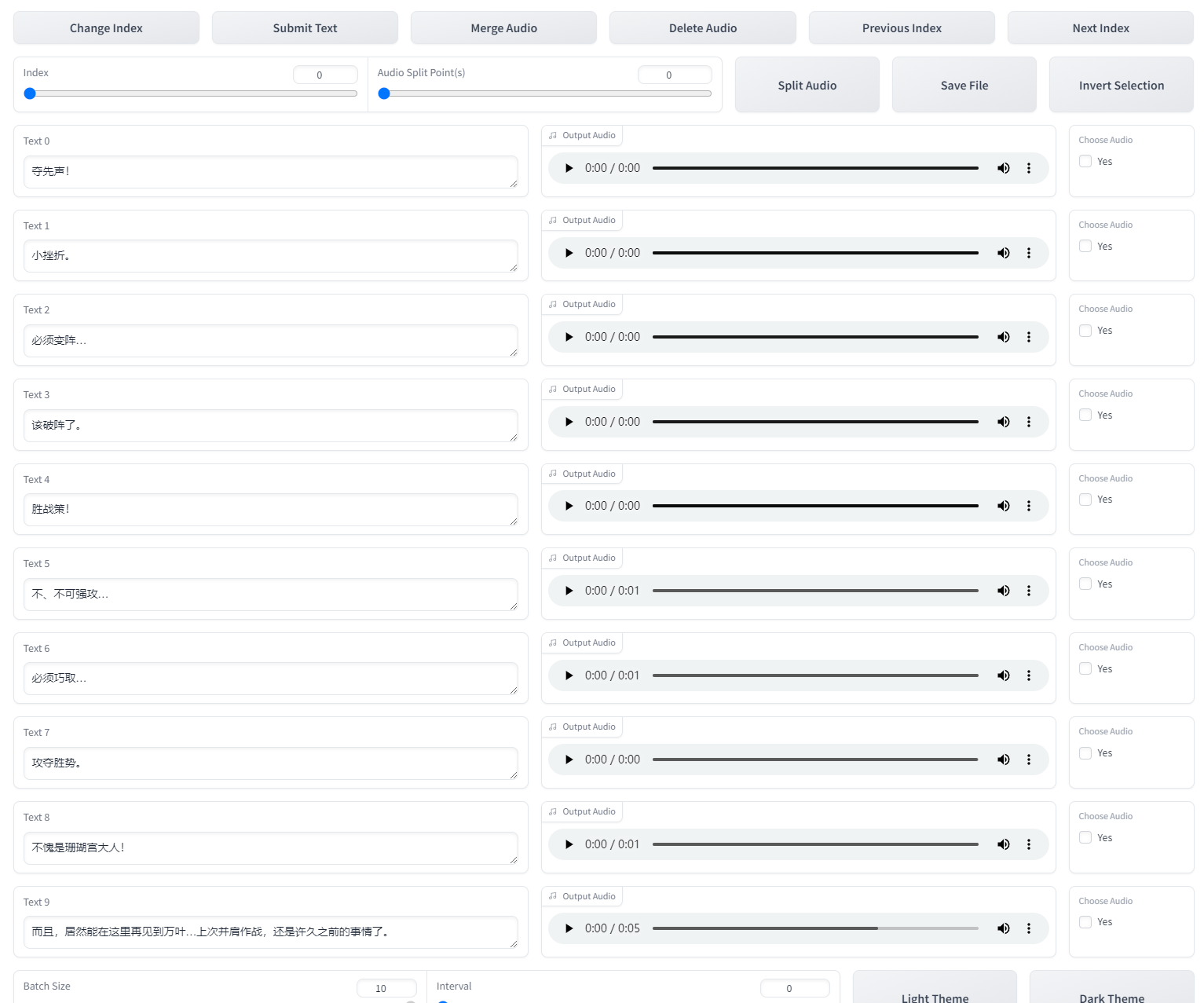
3.5:校对标注(这步比较费时间,如果不追求极致效果可以跳过)
上一步打标完会自动填写list路径,你只需要点击开启打标webui
打开后就是SubFix,从左往右从上到下依次意思是:跳转页码、保存修改、合并音频、删除音频、上一页、下一页、分割音频、保存文件、反向选择。每一页修改完都要点一下保存修改(Submit Text),如果没保存就翻页那么会重置文本,在完成退出前要点保存文件(Save File),做任何其他操作前最好先点一下保存修改(Submit Text)。合并音频和分割音频不建议使用,精度非常差,一堆bug。删除音频先要点击要删除的音频右边的yes,再点删除音频(Delete Audio)。删除完后文件夹中的音频不会删除但标注已经删除了,不会加入训练集的。这个SubFix一堆bug,任何操作前都多点两下保存。
4:训练
4.1:输出logs
来到第二个页面
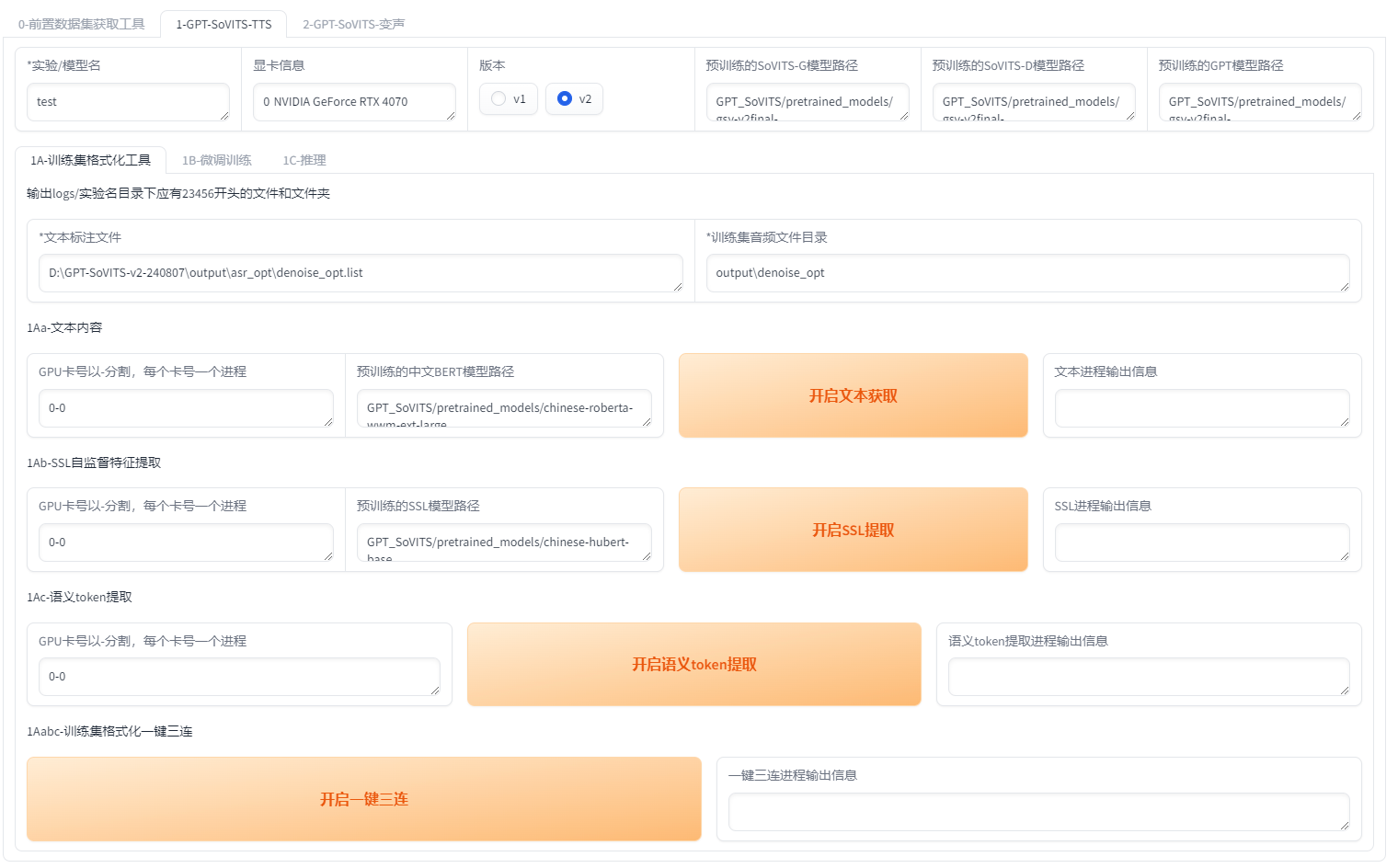
先设置实验名也就是模型名,
理论上可以是中文!打标结束会自动填写路径,只要点下一键三连就好了
如果是英语,日语,粤语或韩语的话logs里的3-bert文件夹是空的,是正常的不用管。
4.2:微调训练
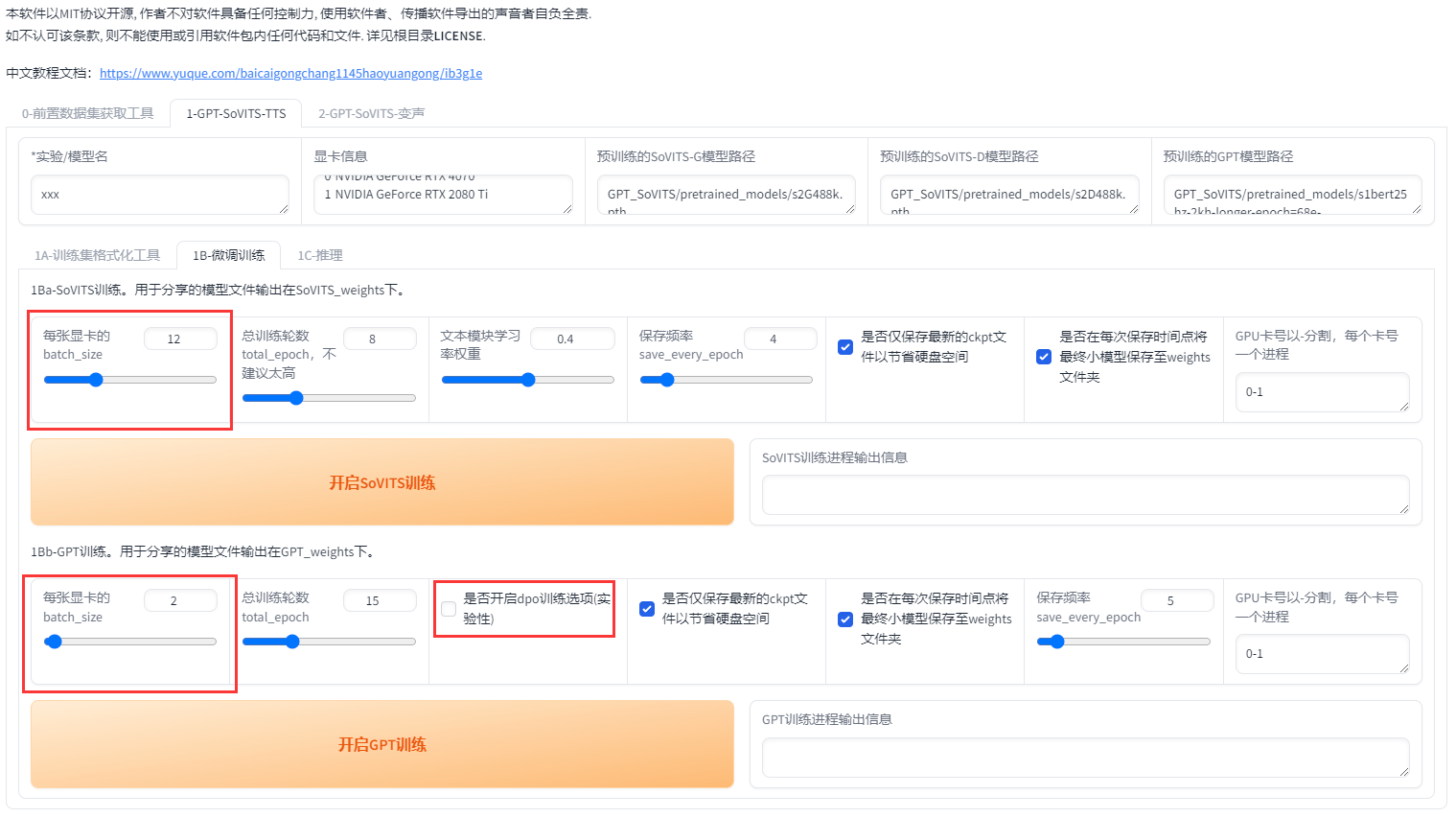
首先设置batch_size,sovits训练建议batch_size设置为显存的一半以下,高了会爆显存。bs并不是越高越快!batch_size也需要根据数据集大小调整,也并不是严格按照显存数一半来设置,比如6g显存需要设置为1。如果爆显存就调低。当显卡3D占用100%的时候就是bs太高了,使用到了共享显存,速度会慢好几倍。
以下是切片长度为10s时实测的不同显存的sovits训练最大batch_size,可以对照这个设置。如果切片更长、数据集更大的话要适当减少。
| 显存 | batch_size | 切片长度 |
|---|---|---|
| 6g | 1 | 10s |
| 8g | 2 | 10s |
| 12g | 5 | 10s |
| 16g | 8 | 10s |
| 22g | 12 | 10s |
| 24g | 14 | 10s |
| 32g | 18 | 10s |
| 40g | 24 | 10s |
| 80g | 48 | 10s |
在0213版本之后添加了dpo训练。dpo大幅提升了模型的效果,几乎不会吞字和复读,能够推理的字数也翻了几倍,但同时训练时显存占用多了2倍多,训练速度慢了4倍,12g以下显卡无法训练。数据集质量要求也高了很多。如果数据集有杂音,有混响,音质差,不校对标注,那么会有负面效果。
如果你的显卡大于12g,且数据集质量较好,且愿意等待漫长的训练时间,那么可以开启dpo训练。否则请不要开启。下面是切片长度为10s时实测的不同显存的gpt训练最大batch_size。如果切片更长、数据集更大的话要适当减少。
| 显存 | 未开启dpo batch_size | 开启dpo batch_size | 切片长度 |
|---|---|---|---|
| 6g | 1 | 无法训练 | 10s |
| 8g | 2 | 无法训练 | 10s |
| 12g | 4 | 1 | 10s |
| 16g | 7 | 1 | 10s |
| 22g | 10 | 4 | 10s |
| 24g | 11 | 6 | 10s |
| 32g | 16 | 6 | 10s |
| 40g | 21 | 8 | 10s |
| 80g | 44 | 18 | 10s |
接着设置轮数,相比V1,V2对训练集的还原更好,但也更容易学习到训练集中的负面内容。所以如果你的素材中有底噪、混响、喷麦、响度不统一、电流声、口水音、口齿不清等情况那么请不要调高SoVITS模型轮数,否则会有负面效果。GPT模型轮数一般情况下不高于20,建议设置10。然后先点开启SoVITS训练,训练完后再点开启GPT训练,不可以一起训练(除非你有两张卡)!如果中途中断了,直接再点开始训练就好了,会从最近的保存点开始训练。
训练的时候请ctrl+shift+esc打开任务管理器看,下拉打开选项,选择cuda。如果cuda占用为0那么就不在训练。专用GPU内存就是显存,其他的内存都是共享的,并不是真正的显存。爆显存了就调低bs。或者存在过长的音频,需要回到2.2步重新制作数据集。
win11没有cuda打开设置–系统–显示–显示卡–默认图形设置
关闭硬件加速GPU计划,并重启电脑

训练完成会显示训练完成,并且控制台显示的轮数停在设置的(总轮数-1)的轮数上。
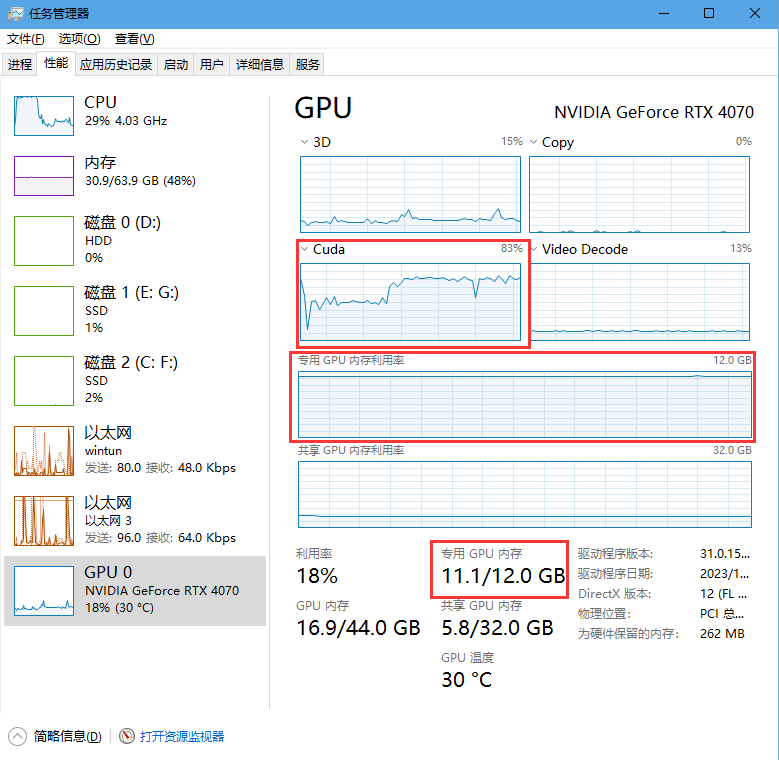
看cuda占用需要下拉选择cuda,如果win11找不到cuda界面需要关闭硬件加速GPU计划并重启
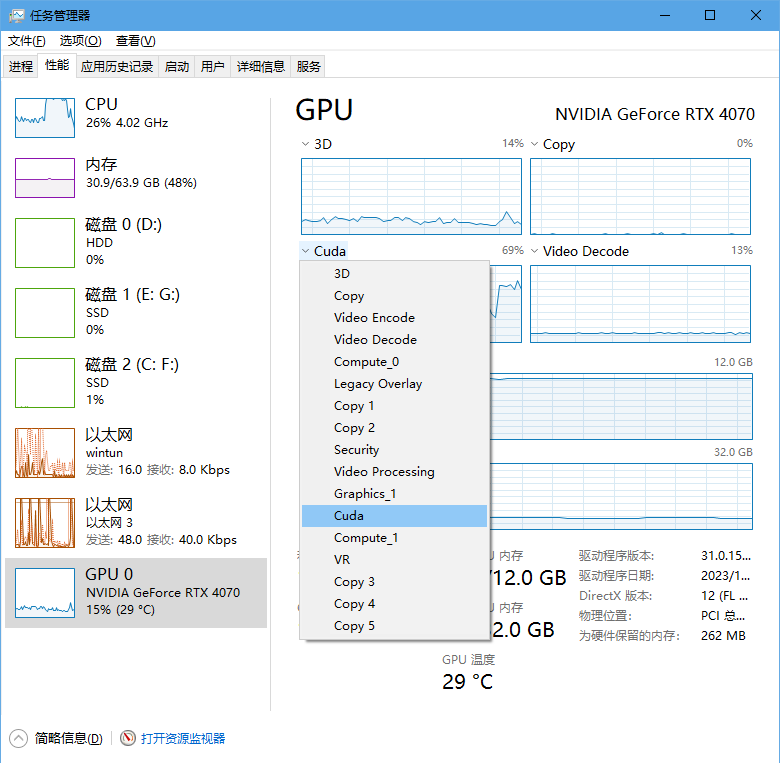
关于学习率权重:
可以调低但不建议调高。直接听对比,自己听效果
关于高训练轮数:
你可能会看见有人会说训练了几百轮,几千轮的(几万轮那就是搞错了轮数和步数)。但高轮数并不就是好。如果要训练高轮数请先保证数据集质量极好,标注全都经过手动校对,时长至少超过1小时才有必要拉高轮数。否则默认的十几轮效果已经很好了。
关于数据集长度:
请先保证质量!音频千万不能有杂音,要口齿清晰,响度统一,没有混响,每句话尽量完整,全部手动校对标注。30分钟内有明显提升,不建议再增加数据集长度(除非你有一堆4090)
模型怎样才算训练好了?
这是一个非常无聊且没有意义的问题。就好比上来就问老师我家孩子怎么才能学习好,谁都无法回答。
模型的训练关联于你的数据集质量、时长,轮数,甚至一些超自然的玄学因素;即便你有一个成品模型,最终的转换效果也要取决于你的参考音频以及推理参数。这不是一个线性的的过程,之间的变量实在是太多,所以你非得问“为什么我的模型出来不像啊”、“模型怎样才算训练好了”这样的问题,我只能说 WHO F**KING KNOWS?
但也不是一点办法没有,只能烧香拜佛了。我不否认烧香拜佛当然是一个有效的手段,但你也可以借助一些科学的工具,例如 Tensorboard 等,但还是戴上耳机,让你的耳朵告诉你吧。用耳朵听就是最科学的方式。
如果你的模型一直很差,那你该好好反思反思为什么不好好准备数据集了。
极佳模型分享(使用30小时派蒙数据集,100%正确率标注,开启DPO)
情感分类
如果有超过1小时的数据集的话,可以先用Emotion2Vec或ColorSplitter情感分类后再训练。会获得更稳定更丰富的情感,不过标注一定要手动校对
关于Tensorboard
GPT-SoVITS可以开启tensorboard,但在连30轮都不到的轮数下loss值有什么意义?用耳朵好好听吧。
5:推理
5.1:开启推理界面
先点一下刷新模型,下拉选择模型推理,e代表轮数,s代表步数。不是轮数越高越好。选择好模型点开启TTS推理,自动弹出推理界面。如果没有弹出,复制http://0.0.0.0:9872到浏览器打开。
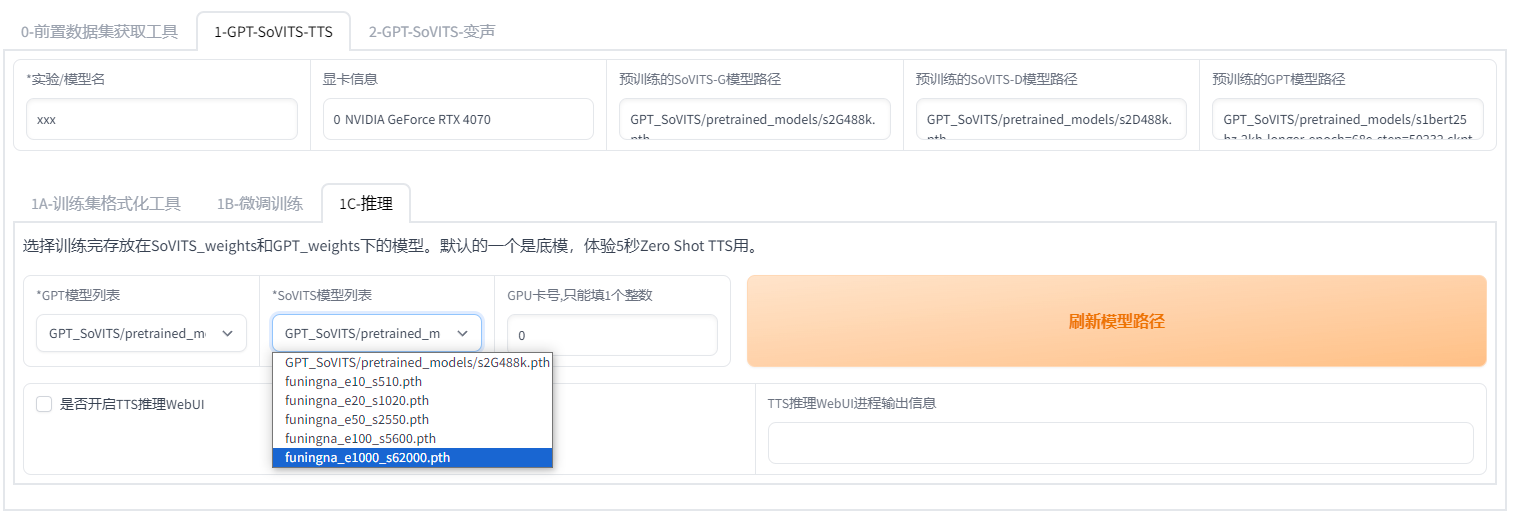
5.2:开始推理
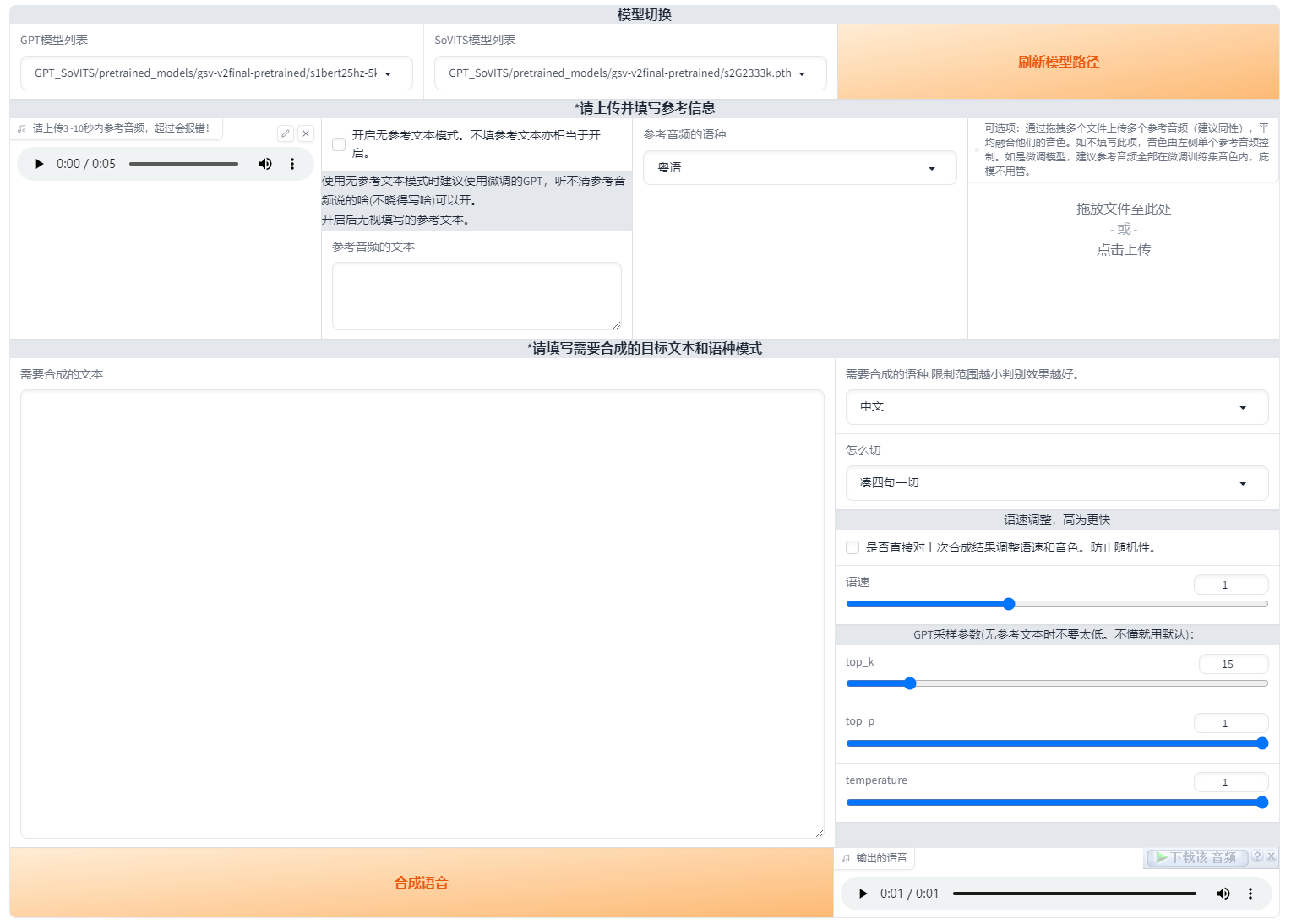
然后上传一段参考音频,建议是数据集中的音频。最好5秒。参考音频很重要!会学习语速和语气,请认真选择。参考音频的文本是参考音频说什么就填什么,语种也要对应。在0217版本之后可以选择无参考文本模式,但非常不建议使用,效果非常拉胯,就几秒钟打个字的事就这么懒吗?而且注意:是无参考文本!不是无参考音频!参考音频无论什么情况都要的!
右上角有个融合音色的可选项,先将要融合的音频放在一个文件夹然后一起拖进去(没啥实用性的功能)
接着就是输入要合成的文本了,注意语种要对应。目前可以中英混合,日英混合和中日英混合。切分建议无脑选凑四句一切,低于四句的不会切。如果凑四句一切报错的话就是显存太小了可以按句号切。如果不切,显存越大能合成的越多,实测4090大约1000字,但已经胡言乱语了,所以哪怕你是4090也建议切分生成。合成的过长很容易胡言乱语。
0213版本加入了top_p,top_k和temperature,保持默认就行了。这些控制的都是随机性,拉大数值,随机性也会变大,所以建议默认就好
关于top_p,top_k和temperature
这三个值都是用来控制采样的。在推理的时候要挑出一个最好的token,但机器并不知道哪个是最好的。于是先按照top_k挑出前几个token,top_p在top_k的基础上筛选token。最后temperature控制随机性输出。
比如总共有100个token,top_k设置5,top_p设置0.6,temperature设置为0.5。那么就会从100个token中先挑出5个概率最大的token,这五个token的概率分别是(0.3,0.3,0.2,0.2,0.1),那么再挑出累加概率不超过0.6的token(0.3和0.3),再从这两个token中随机挑出一个token输出,其中前一个token被挑选到的几率更大。以此类推
还听不懂?拉满当赌狗,拉低当复读机
关于重复惩罚
= 1不惩罚重复,> 1时开始惩罚重复,< 1时鼓励重复。一般都设置为 > 1,因为本身复读就挺严重的。
如果出现吞字,重复,参考音频混入的情况,这是正常现象。改善的方法有使用较低轮数的GPT模型、合成文本再短点、换参考音频。官方也在努力修复这个问题。
如果一直复读那估计是标注不准确的问题,手动校对后重炼就行。
筛选参考音频工具
项目地址:https://github.com/Alexw1111/RefAudioEmoTagger(有能力的可以给项目点个star)
作者:Alexw1111
整合包下载:https://www.123pan.com/s/BYgpjv-xVmJv.html
输入文件夹是之前输出logs这步时的训练集音频文件目录,音频重命名方式选list,.list文件路径就是输出logs那步的list路径,模型选择emotion2vec+更好,然后点击一键推理就好
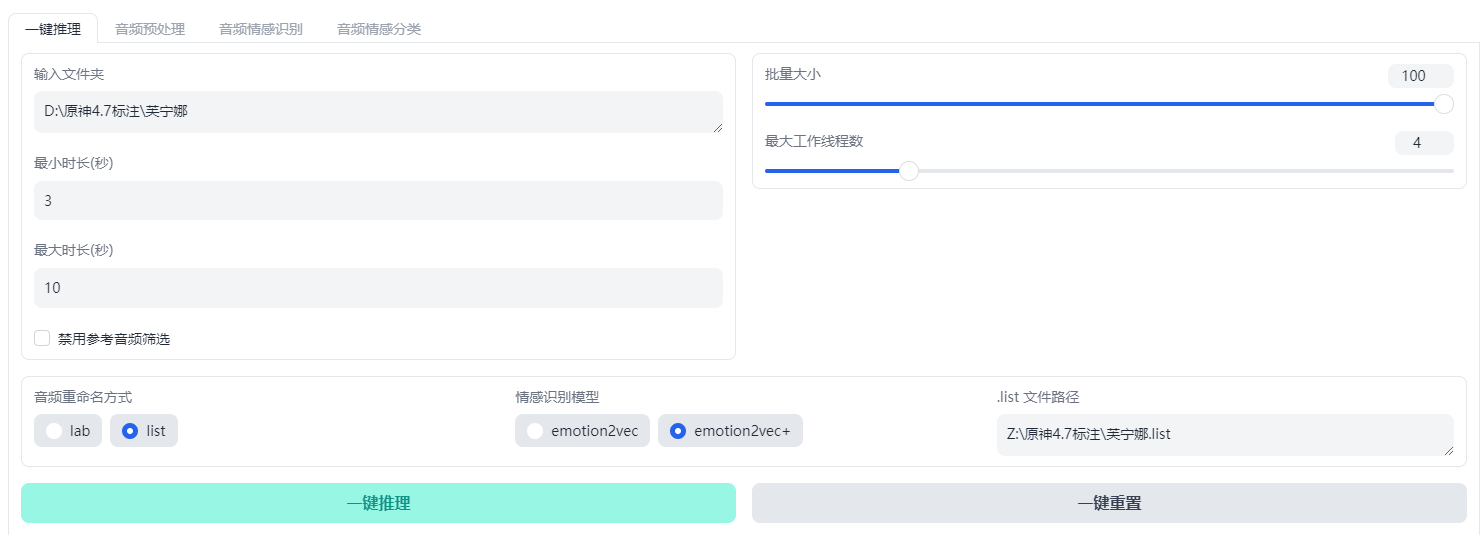
完成后输出目录在根目录的output文件夹
音频会按情感分为最多五类,也有可能只有两类甚至一类,看数据的丰富程度

同时每一个音频文件被标注重命名了,可以直接使用了

6:分享模型
分享需要的模型都在SoVITS_weights_v2和GPT_weights_v2这两个文件夹,选择合适轮数的模型,记得带上参考音频一起打包成压缩文件,就可以分享了。别人只要将GPT模型(ckpt后缀)放入GPT_weights文件夹,SoVITS模型(pth后缀)放入SoVITS_weights文件夹就可以推理了
7:使用别人分享的模型
将GPT模型(ckpt后缀)放入GPT_weights文件夹,SoVITS模型(pth后缀)放入SoVITS_weights文件夹,刷新下模型就能选择模型推理了。
8:如何训练第二个模型
记得把之前切片文件夹里的音频和asr文件夹里的标注文件移走,否则会一起加入训练集。训练的时候记得更换模型名!记得更换模型名!记得更换模型名!其他步骤都一样。模型还在GPT_weights_v2文件夹和SoVITS_weights_v2文件夹。
关于变声部分
目前还没做完,每个人打开都是【施工中,请静候佳音】。不是缺文件了,就是还没做好。敬请期待吧
软件以M协议开源,作者不对软件具备任何控制力,使用软件者,传播软件导出的声音者自负全责.
如不认可该条款,则不能使用或用软件包内任何代码和文件.详见根目录ICENSE.
0-前置数据集获取工具1-GPTSOVITS-TTS2-GPT-SOVITS-型
施工中,请静候佳音

夹,SoVITS模型(pth后缀)放入SoVITS_weights文件夹,刷新下模型就能选择模型推理了。
8:如何训练第二个模型
记得把之前切片文件夹里的音频和asr文件夹里的标注文件移走,否则会一起加入训练集。训练的时候记得更换模型名!记得更换模型名!记得更换模型名!其他步骤都一样。模型还在GPT_weights_v2文件夹和SoVITS_weights_v2文件夹。
关于变声部分
目前还没做完,每个人打开都是【施工中,请静候佳音】。不是缺文件了,就是还没做好。敬请期待吧
软件以M协议开源,作者不对软件具备任何控制力,使用软件者,传播软件导出的声音者自负全责.
如不认可该条款,则不能使用或用软件包内任何代码和文件.详见根目录ICENSE.
0-前置数据集获取工具1-GPTSOVITS-TTS2-GPT-SOVITS-型
施工中,请静候佳音
博客原文;专业人工智能技术社区

















 1629
1629

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









