






目前在深度学习与图像处理领域,常常需要对大量图片进行批量处理。若按照常规的脚本编写方法进行处理,往往会消耗大量时间。这里我教大家一个非常简单的方法实现脚本并行,最大化利用你的多核cpu来n倍加速你的脚本。
我们举例来说明:
首先,我们在这里处理19000多张图片,将他们统一resize到16x16。我们立刻会想到使用for循环来完成,代码如下:
import cv2,glob,datetime
from multiprocessing import Pool
def resize(InputPath):
ImgOri = cv2.imread(InputPath)
ImgResize = cv2.resize(ImgOri,(28,28))
cv2.imwrite(InputPath.replace('',''),ImgResize) #改名储存,可按照自己喜好随意设置
if __name__ == '__main__':
start = datetime.datetime.now()
PicsPath = r'E:\pics\*'#正则表达式匹配该文件夹下的所有文件,也就是图片
Pics = glob.glob(PicsPath)#将该文件夹下的所有文件名储存在列表中
for pic in Pics:
resize(pic)
end = datetime.datetime.now()
print(end-start)这时我们运行,结束时会打印运行时间:
![]()
也就是约83秒
我们看下cpu占用情况:
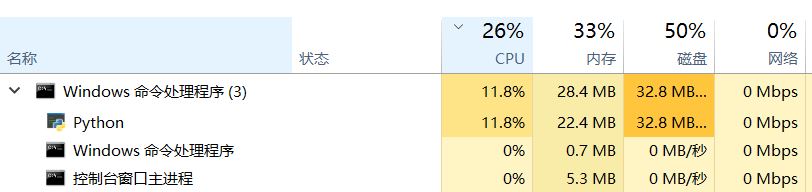
此使CPU占用率为26%,远没有发挥最大性能。
OK,现在我们尝试使用并行来完成。
这里,我们需要用到multiprocessing,python自带的基于进程的并行库,需要看原理的小伙伴可以去官方文档看看,传送门如下,此处不解释~
传送门:https://docs.python.org/zh-cn/3.7/library/multiprocessing.html
直接上代码:
import cv2,glob,datetime
from multiprocessing import Pool
def resize(InputPath):
ImgOri = cv2.imread(InputPath)
ImgResize = cv2.resize(ImgOri,(16,16))
cv2.imwrite(InputPath.replace('',''),ImgResize)
if __name__ == '__main__':
start = datetime.datetime.now()
PicsPath = r'E:\pis\*'
Pics = glob.glob(PicsPath)
pool = Pool()
pool.map(resize,Pics)
pool.close()
pool.join()
end = datetime.datetime.now()
print(end-start)直到获取图片名列表的步骤都与之前一样,这里我们不使用for循环,使用pool中的map方法来批量传入变量进行处理。
pool.map函数有两个形参,第一个形参为待处理函数名,第二个形参为变量列表。
OK,我们来看看处理时间:
![]()
12秒!几乎是前面是7倍!
再来看看CPU占用情况:

可以看到这里有多个脚本进程并行,cpu占用率几乎为100%,最大化处理性能。
总之,多进程并行能够非常有效地提升密集型IO处理的效率,建议大家在脚本运行过慢的情况下尝试此种方法,能非常有效地节约时间!















 2793
2793











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









