







项目场景:
在使用python 图像遍历时 使用 numba 的 jit 模块 加速处理,
问题描述:
例如下面这段代码,主要是遍历像素,但是由于图像 为 1920 * 1080 , 对于python 这种解释性语言来说,如果是图像序列,速度简直无法忍受,甚至达到 10s 一帧图像。 for i in range(1080):
for j in range(1920):
if img_m[i][j][0] == 128 and img_m[i][j][1] == 0 and img_m[i][j][2] == 192 or img_m[i][j][0] == 0 and \
img_m[i][j][1] == 192 and img_m[i][j][2] == 128 or img_m[i][j][0] == 0 and img_m[i][j][1] == 192 and \
img_m[i][j][2] == 0:
img_m[i][j][0] = 128
img_m[i][j][1] = 128
img_m[i][j][2] = 64
解决方案:
为了,解决这个问题,一 修改算法,当然有时候比较难想到,二 、不用python 了 C++ 多香,C++,使用指针和迭代器确实也会比较快。
但是使用 python 也有相应的解决方案。
使用 numba 库
numba库
- 加速 Python 函数
- 专为科学计算而打造
- 并行化您的算法
- 便携式编译
光看官网介绍的这几个功能就很牛逼,我这里只是简单解决上面的问题。
import cv2
import time
from numba import jit #使用jit 模块 pip install numba or conda install numba
path = "..."
path1 = "..."
#使用装饰器,jit 加速
@jit # 就是这么一个简单的改变
def processImg_jit(img_m):
for i in range(1080):
for j in range(1920):
if img_m[i][j][0] == 128 and img_m[i][j][1] == 0 and img_m[i][j][2] == 192 or img_m[i][j][0] == 0 and \
img_m[i][j][1] == 192 and img_m[i][j][2] == 128 or img_m[i][j][0] == 0 and img_m[i][j][1] == 192 and \
img_m[i][j][2] == 0:
img_m[i][j][0] = 128
img_m[i][j][1] = 128
img_m[i][j][2] = 64
return img_m
# 原始的
def processImg(img_m):
for i in range(1080):
for j in range(1920):
if img_m[i][j][0] == 128 and img_m[i][j][1] == 0 and img_m[i][j][2] == 192 or img_m[i][j][0] == 0 and \
img_m[i][j][1] == 192 and img_m[i][j][2] == 128 or img_m[i][j][0] == 0 and img_m[i][j][1] == 192 and \
img_m[i][j][2] == 0:
img_m[i][j][0] = 128
img_m[i][j][1] = 128
img_m[i][j][2] = 64
return img_m
img = cv2.imread(path + "0000" + str(2621) + ".jpg")
t0 = time.time()
img = processImg(img)
t1 = time.time()
print("原始: ",t1 - t0)
t0 = time.time()
img = processImg_jit(img)
t1 = time.time()
print("加速:",t1 - t0)
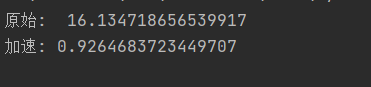
速度差了20倍…


















 610
610

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











