







虽然导师远在马来西亚,但是每次都是很耐心的回答我的问题,真的是非常感激啦!
我就想记录下来,自己提出的问题,老师给我的解答,算是我研究生生涯的很大一部分生活了吧!
噢~ 还有就是,这些都是微信聊天记录呦!!!
20190919
提问:
https://blog.csdn.net/qq_38412868/article/details/83748553
这里面提到的LSTM实现的方式
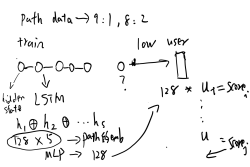
比如一条路劲:U1 -> f1 ->f2 ->f3 -> f4 -> f5
训练时X:U1 f1 f2 f3 f4
Y:f1 f2 f3 f4 f5
会得到5个cell输出: c1、c2、c3、c4、c5
则损失函数:Loss = sum( ( [c1 c2 c3 c4 c5] - [f1 f2 f3 f4 f5] ) **2 )
这样计算损失的方式是否可取,这样好像就不需要负采样了。
我感觉这样的计算方式挺合理的。
但是 是不是进行训练的时候必须有正样本和负样本?
采用负样本的目的是为了把推荐问题看成一个二分类问题吗?
老师回答:
负采样训练不是一般性机器学习模型必备的
但是在我们的问题里,最后评估模型质量的那些measure,是评估模型是否能将positive样本的估分比negative样本的估分高
因此在训练的过程中,我们就要引入negative样本,在训练数据上优化使得正样本比负样本的评分高
这么做是因为这一类型的推荐问题大家公认的评估方式决定的。
如果做推荐评分预测问题,模型评估的时候就只是估计分数的误差,那么训练的时候就不需要用负样本了
20190920
提问:
LSTM的五个状态进行concatenate处理后5*8 的向量转换为8 的向量时:
使用 [40,20,8] 还是直接使用 [40,8]
是不是数据量很大的时候才采用塔形(减半)的方式设置MLP,数据量少的时候一个全连接层就可以了。
老师回答:
使用 [40,20,8] 还是直接使用 [40,8] 这个不好说,都是测试完才知道效果,我会先实验第一种减半的方法
20190923
1、评估阶段:(假设user embedding=8)用LSTM对用户信任路径做处理,将每个hidden state进行concatenate得到path embedding 8*5,通过MLP处理得到 path embedding 8,与user embedding进行向量内积得到链路预测用户得分,这里可能需要对score用sigmoid函数处理。
2、Loss计算:(有一丢丢印象,但还是没有理解这里的计算)还有一个很重要的问题就是,如果这样计算损失的话,评估阶段使用的MLP里面的参数并没有在训练阶段的到训练。
老师回答:
这里可能需要对score用sigmoid函数处理 -》 这个没问题,最后需要得到一个预测分数值的时候,一般都是会通过sigmoid
评估阶段使用的MLP里面的参数并没有在训练阶段的到训练 -》 没理解你的意思,训练和测试用的模型要是一样的架构,同一个模型
因为最后一层是输出一个概率,一般一定会通过一层用sigmoid当激活函数的MLP。只是在这层(d=8)前是否还有别的MLP(如d=20)可以自己试验一下,不好说效果好不好
测试和训练的模型,最后一层都放一个sigmoid的mlp
还有目前训练的时候,对于6个节点的路径,记得先写成 利用1预测2,利用(1, 2) 预测 3, 利用(1,2,3) 预测4 。。。 我前天发给你的两篇论文应该都是这样训练
虽然我觉得这样模型间接的知道了(1,2) 后是 3了,因为有个训练数据是(1,2,3) 。但是大部分这一类论文都还用这种方法
提问:
不知道我理解的对不对?

老师回答:
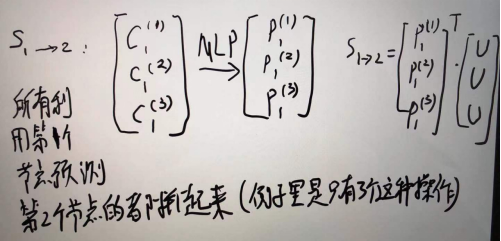
数学上是对的 但是实现的时候这样算会很慢。要像上次说的那样算S_1->2的时候P和U要是矩阵,相当于要是数据里有100个像你写的S_1->2的公式计算,程序里要把这100个拼成一次计算
20191004
汇报:
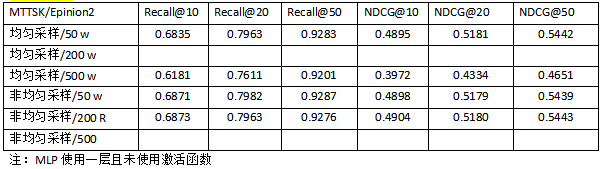
结论:
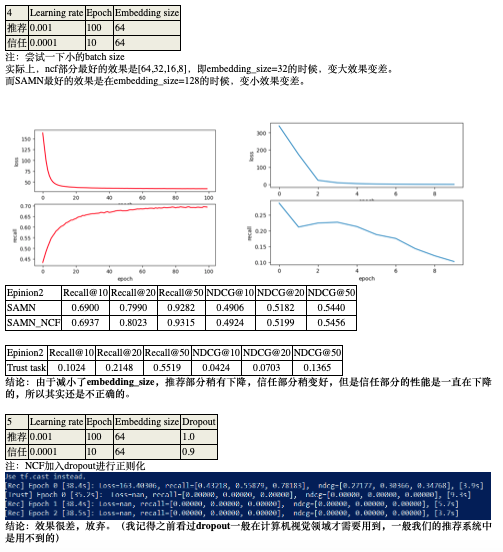
- 从实验结果来看,效果没有提升,反而下降。信任部分出现了问题。
- 非均匀采样的效果要比均匀好一点,采样200比50好一点。采样500时效果出现明显下降。因为用户之间的信任link只有用户数量的4倍,意味着很多用户没有信任的人,很多用户信任的人的数量也不多,所以sample到的很多路径是用max_user值padding得到的,以至于效果不好。(200非均匀应该是最好的设置)
老师回复:
我想在数据里filter掉长度小于6的信任路径。只训练那些长度6的信任路径,如果某个用户一条长度6的信任路径也没有,那么对他的推荐就退化成SAMN。
可以先统计下,这13957个用户里,有多少能又长度6的路径的
就是以某个用户为起点的路径,长度有6的,那这个用户就算有信任路径。统计下,有多少用户有信任路径
cici:
我统计了一下有564个用户有长度为6信任路径,有点少
老师:
那看来效果不好跟这个路径数太少应该有关系。之前你跑实验的时候,一个用户最多几条路径呢?
这564个用户有长度为6信任路径,又一共有几条?
cici:
为每个用户均匀采样50条路径,其中564个用户存在长度为6的路径,一共50*13957=697850条路径中有29979条路径是长度为6
20191005
汇报:
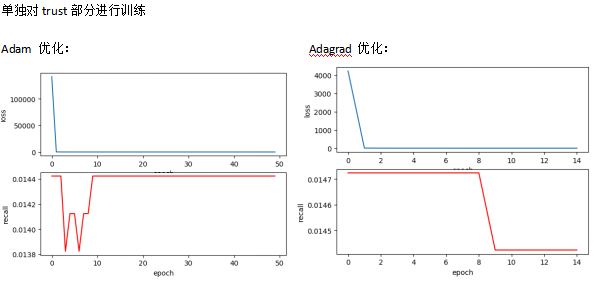
结论:
- loss在减少,recall却没有提升。模型过拟合。
- 推荐部分和信任部分应该以不同的速度或者说频率进行训练,因为他们收敛的速度不同。(推荐部分在epoch100次的整个过程中性能有持续逐步的提升,信任部分epoch10次以上就不行了)(也就是说这两个任务的损失函数不应该加在一起,而是训练10次推荐,再训练1次信任)
老师回复:
这个想法没有问题。先试一下推荐训练1次trust训练1次的效果,再试试推荐训练10次trust训练1次这样。可以把整个训练过程中,trust部分和推荐部分的loss画折线图看一下趋势
提问:
一些我的理解不知道对不对:
MLP的最后一层,如果是一个输出的0-1分类问题,一般使用sigmoid激活函数;
如果是多个输出的分类问题(比如手写数字分类),一般使用softmax激活函数;
而在本实验中,是通过LSTM的每个状态的concat中学习路径的表示,最后一层应该是不需要使用激活函数的。
老师回复:
这里数学理论上是不需要在最后加激活函数了
但是实际实现里要加sigmoid,来保证计算机计算的时候的数值稳定性
https://www.tensorflow.org/api_docs/python/tf/nn/sigmoid_cross_entropy_with_logits 如果是TensorFlow的话,我们做的这种问题需要训练negative sample的,一般会用这个loss
你看他的说明里面模型最后的输出就先传到sigmoid再传入loss
这样在计算每一个sample的时候,能保证输出一定在[0,1]这个range里。如果不加这个限制,在一些异常数据点上,或者出现梯度爆炸问题的时候,可能有一些输出值特别大
比如超过了计算机的数值范围,导致结果是nan。这种情况蛮常见的,不一定是程序写错。有可能就是剃度爆炸了。所以一般最后还是加上sigmoid再传入loss函数了
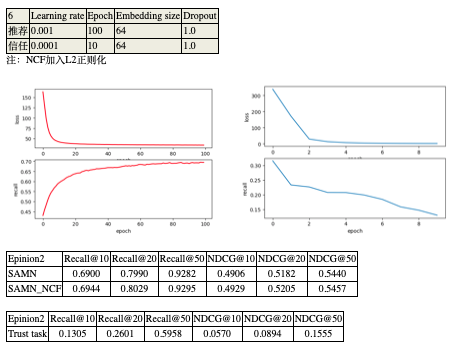
汇报:
Trust部分对MLP改进:
1 * 128、2 * 128、3 * 128使用一层,未使用激活函数未使用dropout。
4 * 128、5 * 128使用两层,中间层激活函数使用Relu,为防止过拟合设置keep_prob=0.75。最后一层未使用激活函数未使用dropout。
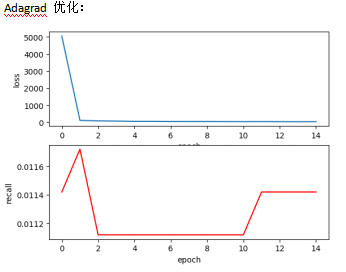
结论:
性能只有了短暂的提升,很奇怪
所以说,现在的问题是信任预测这个任务采用目前的方式得不到很好的效果。对推荐任务没有起到很好的辅助效果。
接下来我也不知道该从那个部分对信任任务进行改进了。。。
老师回复:
最早做的那个版本,是不是NCF,然后信任部分不是用路径而是类似NCF做法?
就是推荐部分和信任部分其实都是NCF?
cici:
是的,推荐部分和信任部分都是NCF
老师:
刚才你汇报的路径29979条,不好说这个数据量够不够。但是只分布在500多个用户,确实有些问题。
我想现在你试试用SAMN当推荐部分,信任部分用之前写的NCF版的信任边预测。这样的结果看看如何。
以路径建模写代码会比较麻烦,再尝试更复杂的路径方法前。先拿之前的部分代码和现在的合起来看看效果,会比较容易点
cici:
可以的,那我这样试一试。
20191012
汇报:
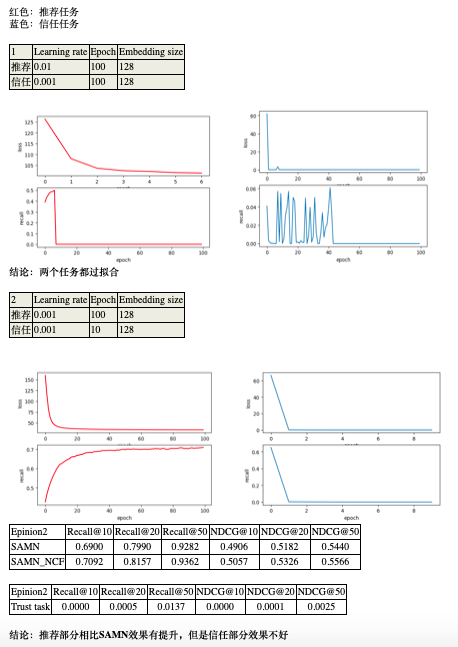
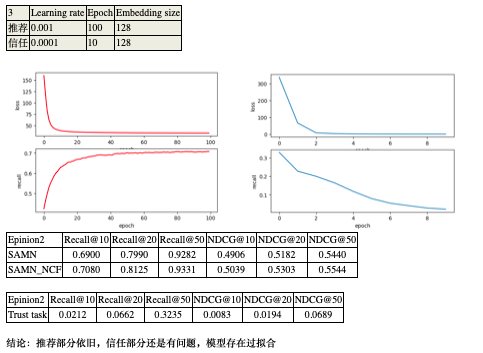
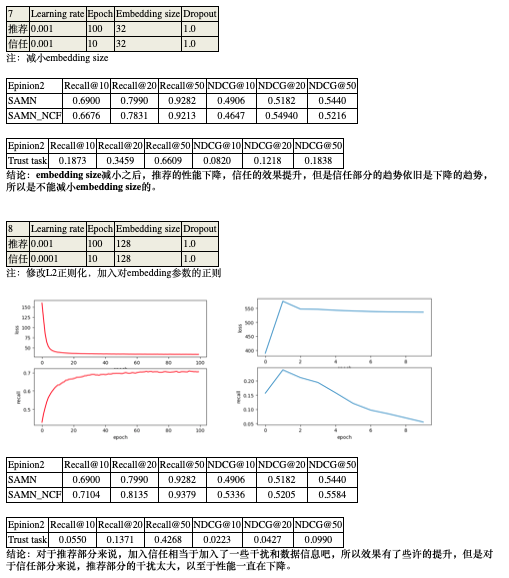
老师:
我看了两个结果。总结来说,两个任务一起学习的话,信任部分是越来越差的。但是如果单独学习信任部分,NCF的架构又是能看到recall逐渐变好
我觉得 两个任务间共享参数的方法 以及multi-task优化的方法。这两块我明天想想一些方法试一下,看看能不能实现trust在多任务学习的时候也有提升
现在这个模型设计,应该只有直接共享最底层item embedding这做了共享。挺粗糙的
cici:
对,只有直接共享user embedding。
https://blog.csdn.net/weixin_37913042/article/details/102498802 我也看了一些文章,然后,然后好像也不是很清楚该怎么改进
老师:
我们其实是这里的硬共享。比较初期,在上面的layer那没有共享学习,所以有问题也还说得过去。我想一下上面层如何共享.
我把下一步的想法,发邮件给你了
修改模型的时候要哪里不清楚,直接问我
以后发实验结果也可以用邮件附件发给我,微信经常查看以前的word文件就失效打不开了
cici:
嗯!好的!
20191012
cici:
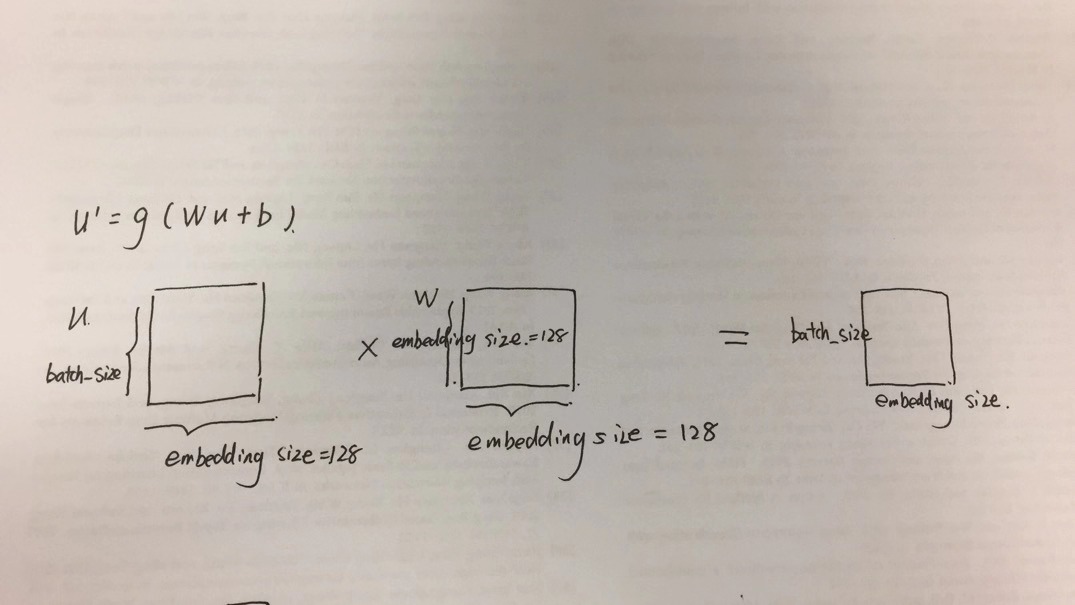
“ 注意这个shared layer的参数是共享的,即它定义的embedding size就是用户的总数 ” 这里“embedding size就是用户的总数”没太理解.
还有一个问题是这个共享操作,只能在向量输入MLP之前做,因为输入到MLP的向量是user和item的concate(推荐)、user1和user2的concate(信任),所以没有你说的第三点,将共享操作分享到第二层、第三层等等。
老师:
embedding size不是指的dimension。那句话的意思就是要是在左边和右边的用户如果是同一个id即同一个用户,那么传到share 层的时候这两个embedding要乘以同一个权重,加上同一个bias
第二个问题,就只做一次共享操作先试试好了
cici:
好的,我清楚了!
20191015
cici:
老师,我把结果发你邮箱啦!
20191016
老师:
我看文档看不出问题。你告诉我代码在服务器上的路径,我今天下课看一下
cici:
/home/lyli/MNCF/MNCF3.py
老师:
明天白天你看看51行这是不是应该是input_dim=num_users?这两部分share的是user吧
现在已经很晚了,不需要急着看
cici:
嗯,对的 应该是user,
老师:
我明早再看看其他部分
cici:
好的,真是麻烦老师了
20191017
cici:
老师,单把那里改正确的话,还是有问题。主要是,X操作采用元素相乘就没问题,池化操作和cancate就有问题,理论上来说不应该这样。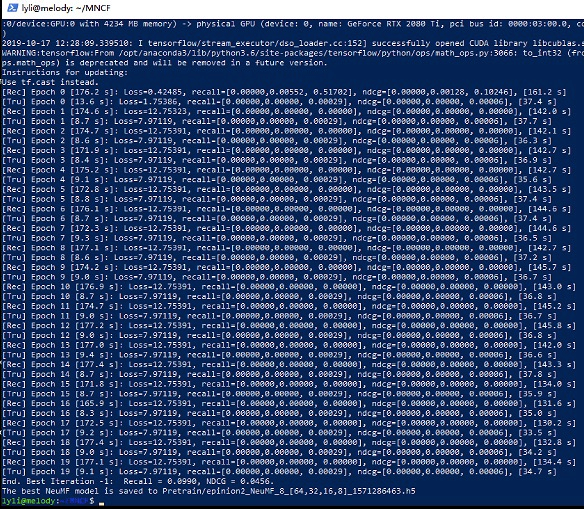
老师:
我今早写了个版本,急着上课没法给你
这个用concate操作结果救市政策的那种
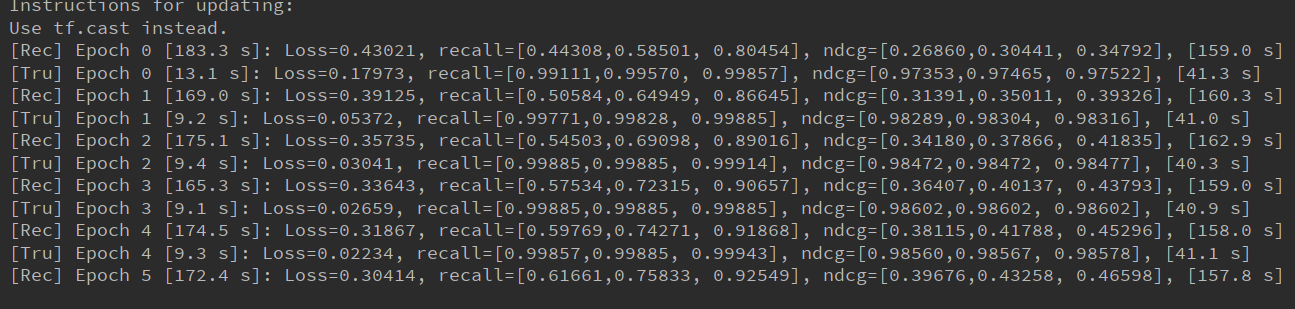
这个用concate操作结果就是正常的那种
但是我为了找出问题,把模型简化掉了。ncf里的矩阵分解部分删掉了
我不经常用keras写代码。我看你的实现,可能的问题是共享层那里用的是Embedding
应该要用Dense才对吧。然后我这个文件里的52行的Dense创建的Shared_User_Layer,在rec和trust部分同时被调用
当然这样把MF删掉了,性能应该变差了。你可以试试再把MF部分加上去会怎么样
cici:
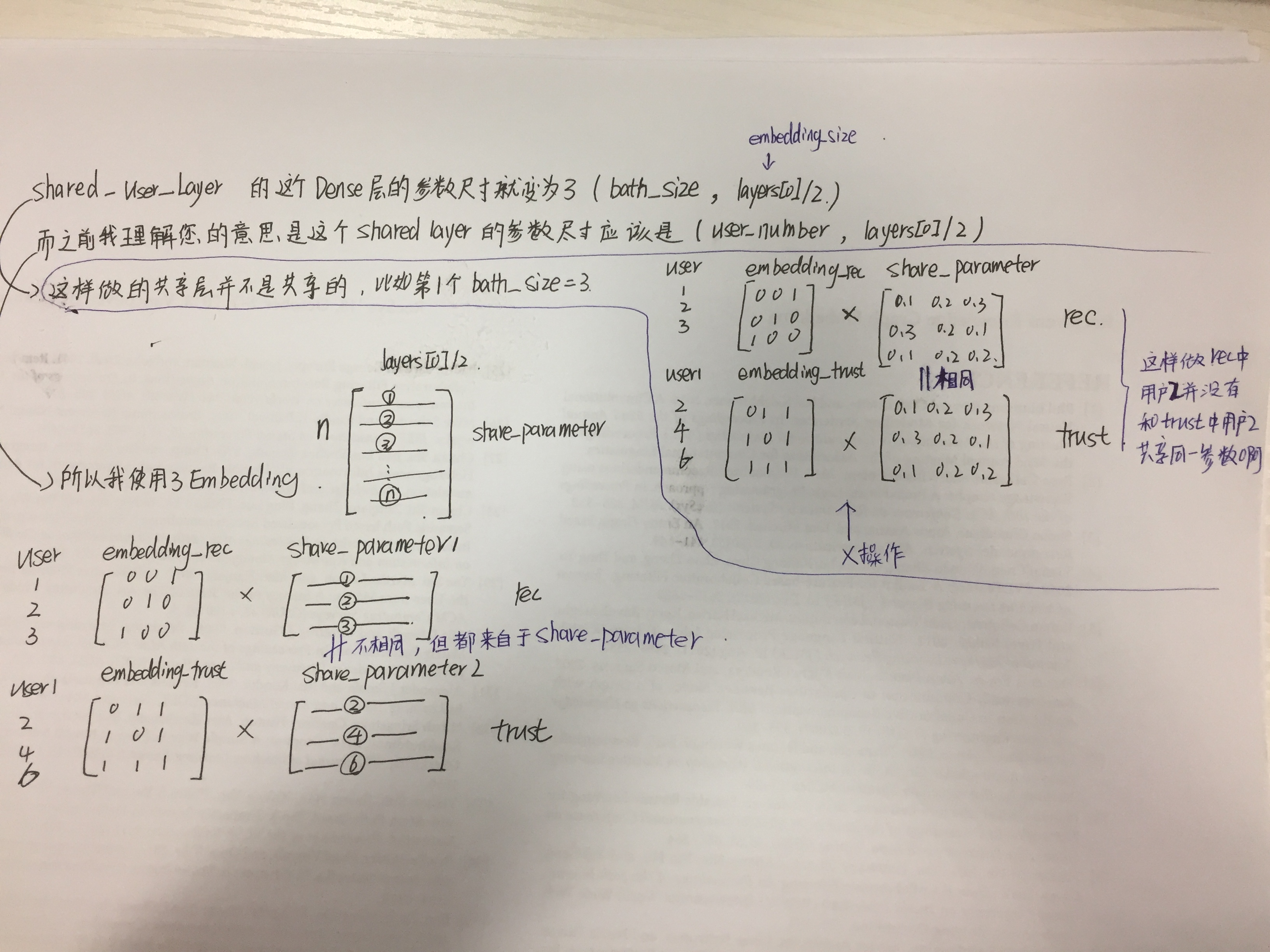
老师:
你说的有道理,我查了keras的dense,不带embedding功能。用keras实现共享功能,得自己定义共享参数为embedding
我再看看其他部分有没问题
cici:
我用keras主要是原作者用了keras,我怕我用tensorflow重写一遍的话,有些地方可能会写错,就直接在上面接着改了!
老师:
没关系,这个基于NCF的版本只是拿来测试下想法,最后的模型应该会摆脱NCF。到时候再考虑要不要用别的写也来得及
cici:
好的
20191105
cici:
我之前遇到
RuntimeError: [enforce fail at CPUAllocator.cpp:64] . DefaultCPUAllocator: can’t allocate memory: you tried to allocate 15851784844900 bytes. Error code 12 (Cannot allocate memory)
这个问题
然后我就百度pytorch如何使用GPU
然后我就在代码里加了CUDA,把模型放到GPU上运算
device = torch.device("cuda:3")
model = model.to(device)然后就出现了这个问题:RuntimeError: CUDA out of memory. Tried to allocate 14763.13 GiB (GPU 3; 10.73 GiB total capacity; 165.28 MiB already allocated; 9.61 GiB free; 10.72 MiB cached)
然后我觉得GPU上内存应该是能满足一般需求了的吧是我的model太大的原因吗???
之前一个可以运行的demo是160,686个link,这个有899,322个link Ls:
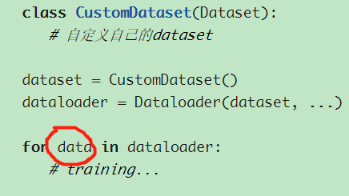
老师:
根据提示是方法写的不对,要加载1TB的数据到GPU:Tried to allocate 14763.13 GiB
你看下数据切割有没问题,一般会把train数据分batch训练,每个batch的数据加载到GPU上
https://zhuanlan.zhihu.com/p/30934236
每次只把这个data.to(device)
cici:
好,我改改方法!
20191109
cici:
老师我将最近的结果发您邮箱啦!















 2099
2099











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









