






 本文讨论深度学习中的标签平滑归一化(LSR)技术。介绍了分类问题中one - hot向量带来的过拟合等问题,阐述了标签平滑技术的原理、数学描述及代码对应。还提及现有研究对其原理及应用场景讨论较少,本文提出新可视化方法,分析其对模型修正和蒸馏的影响。
本文讨论深度学习中的标签平滑归一化(LSR)技术。介绍了分类问题中one - hot向量带来的过拟合等问题,阐述了标签平滑技术的原理、数学描述及代码对应。还提及现有研究对其原理及应用场景讨论较少,本文提出新可视化方法,分析其对模型修正和蒸馏的影响。
前世
今天来进行讨论深度学习中的一种优化方法Label smoothing Regularization(LSR),即“标签平滑归一化”。由名字可以知道,它的优化对象是Label(Train_y)。
对于分类问题,尤其是多类别分类问题中,常常把类别向量做成one-hot vector(独热向量)。

one-hot 带来的问题:
对于损失函数,我们需要用预测概率去拟合真实概率,而拟合one-hot的真实概率函数会带来两个问题:
1)无法保证模型的泛化能力,容易造成过拟合;
2) 全概率和0概率鼓励所属类别和其他类别之间的差距尽可能加大,而由梯度有界可知,这种情况很难adapt。会造成模型过于相信预测的类别。
今生
尽管标签平滑技术已经得到了有效应用,但现有研究对其原理及应用场景的适用性讨论较少。
Hinton 等人的这篇论文就尝试对标签平滑技术对神经网络的影响进行分析,并对相关网络的特性进行了描述。本文贡献如下:
-
基于对网络倒数第二层激活情况的线性映射提出了一个全新的可视化方法;
-
阐释了标签平滑对模型修正的影响,并指出网络预测结果的可信度更多取决于模型的准确率;
-
展示了标签平滑对蒸馏的影响,并指出该影响会导致部分信息丢失
预备知识
这一部分提供了标签平滑的数学描述。假设将神经网络的预测结果表示为倒数第二层的激活函数,公式如下:
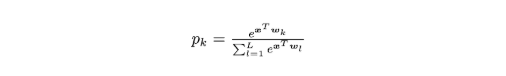
其中 pk 表示模型分类结果为第 k 类的可能性,wk 表示网络最末层的权重和偏置,x 是包括网络倒数第二层激活函数的向量。在使用hard target 对网络进行训练时,我们使用真实的标签 yk 和网络的输出 pk 最小化交叉熵,公式如下:
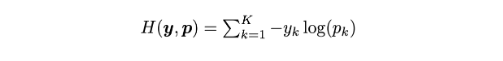
使用下面的 label smoothing 可以缓解one-hot 的问题:
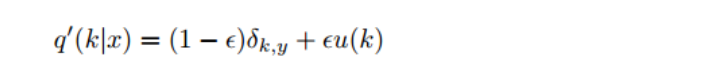
从标签平滑的定义我们可以看出,它鼓励神经网络选择正确的类,并且正确类和其余错误的类的差别是一致的。与之不同的是,如果我们使用硬目标,则会允许不同的错误类之间有很大不同。基于此提出了一个结论:标签平滑鼓励倒数第二层激活函数之后的结果靠近正确的类的模板,并且同样的远离错误类的模板。
原理:对于以Dirac函数分布的真实标签,我们将它变成分为两部分获得(替换)

代码对应:

代码的第一行是取Y的channel数也就是类别数
第二行就是对应公式了。
下面用一个例子理解一下:
假设我做一个蛋白质二级结构分类,是三分类,那么K=3;
假如一个真实标签是[0, 0, 1],取epsilon = 0.1,
新标签就变成了 (1 - 0.1)× [0, 0, 1] + (0.1 / 3) = [0, 0, 0.9] + [0.0333, 0.0333, 0.0333]
= [0.0333, 0.0333, 0.9333]
实际上分了一点概率给其他两类(均匀分),让标签没有那么绝对化,留给学习一点泛化的空间。
从而能够提升整体的效果。
文章[2]表示,对K = 1000,ϵ = 0.1的优化参数,实验结果有0.2%的性能提升。
参考: [1]. When Does Label Smoothing Help?
[2]. Rethinking the Inception Architecture for Computer Vision
[3]. Google Brain最新论文:标签平滑何时才是有用的?

















 436
436

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









