







Deterministic Policy Gradient Algorithms
在本文中,我们考虑了具有连续行动的强化学习的确定性策略梯度算法。确定性策略梯度有一个特别吸引人的形式:它是action-value函数的期望梯度。这种简单的形式意味着可以比通常的随机政策梯度更有效地估计确定性政策梯度。为了确保充分的探索,我们引入了一个off-policy actor-critic算法,该算法从探索性行为策略中学习确定性目标策略。我们证明了确定性政策梯度算法在高维行动空间中的表现明显优于随机策略梯度算法。
1. Introduction
策略梯度算法广泛应用于具有连续动作空间的强化学习问题。其基本思想是用参数概率分布 π θ ( a ∣ s ) = P [ a ∣ s ; θ ] πθ(a|s) = \mathbb P [a|s;θ] πθ(a∣s)=P[a∣s;θ]根据参数向量θ随机选取状态s中的动作a。策略梯度算法通常是通过对随机策略进行抽样,并将策略参数调整为累积回报更高的方向。
在本文中,我们转而考虑确定性策略 a = µ θ ( s ) a = µ_θ(s) a=µθ(s)。我们自然会想,是否可以采用与随机策略相同的方法:按照策略梯度的方向调整策略参数。以前人们认为确定性策略梯度不存在,或者只有在使用模型时才能得到(Peters,2010)。然而,我们表明,确定性策略梯度确实存在,而且它有一个简单的model-free形式,即简单地遵循动作-价值函数的梯度。 此外,我们表明,随着策略方差趋于零,确定性的策略梯度是随机策略梯度的极限情况。
从实践的角度来看,随机性策略梯度和确定性策略梯度之间有一个关键的区别。在随机情况下,策略梯度在状态和行动空间上都有积分,而在确定情况下,它只在状态空间上有积分。因此,计算随机策略梯度可能需要更多的样本,特别是在行动空间有很多维度的情况下。
为了探索完整的状态和动作空间,往往需要一个随机的策略。为了确保我们的确定性策略梯度算法能够继续进行令人满意的探索,我们引入了一个off-policy学习算法。其基本思想是根据随机行为策略选择行动(以确保充分的探索),但要学习确定性的目标策略(利用确定性策略梯度的效率)。
我们使用确定的策略梯度来推导出一个off-policy的actor-critic算法,该算法使用一个可微分的函数近似器来估计动作值函数,然后按照近似的动作值梯度方向更新策略参数。我们还为确定性的策略梯度引入了一个兼容函数近似(compatible function approximation)的概念,以确保近似不会对策略梯度产生偏差。
我们将我们的确定性actor-critic算法应用于几个基准问题:一个high-dimensional bandit;几个低维动作空间的标准基准强化学习任务;以及一个控制章鱼臂的高维任务。我们的结果表明,使用确定性策略梯度比随机性策略梯度有明显的性能优势,特别是在高维任务中。此外,我们的算法不需要比以前的方法更多的计算:每次更新的计算成本是行动维度和策略参数数量的线性关系。
2. Background
我们用
p
(
s
→
s
′
,
t
,
π
)
p(s → s', t, π)
p(s→s′,t,π)表示从状态s过渡了t个时间步骤后的状态
s
′
s'
s′的density。我们还用
ρ
π
(
s
′
)
:
=
∫
S
Σ
t
=
1
∞
γ
t
−
1
p
1
(
s
)
p
(
s
→
s
′
,
t
,
π
)
d
s
ρ^π(s') :=\int_S\Sigma^∞_{t=1} γ^{t-1}p_1(s)p(s → s', t, π)ds
ρπ(s′):=∫SΣt=1∞γt−1p1(s)p(s→s′,t,π)ds 来表示the (improper) discounted state distribution。然后,我们可以把目标写成一个期望值
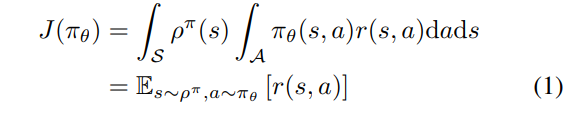
其中
E
s
∼
ρ
[
⋅
]
E_{s∼ρ}[\cdot]
Es∼ρ[⋅]表示相对于discounted state distribution
ρ
(
s
)
ρ(s)
ρ(s)的(improper) expected value。
2.2. Stochastic Policy Gradient Theorem
策略梯度算法可能是最流行的一类连续行动强化学习算法。这些算法的基本思想是按照性能梯度
∇
θ
J
(
π
θ
)
∇_θJ(π_θ)
∇θJ(πθ)的方向来调整策略的参数θ。这些算法的基本结果是策略梯度定理(Sutton等人,1999)
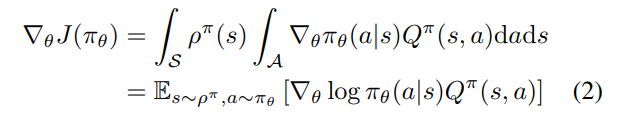
策略梯度出奇地简单。特别是,尽管状态分布
ρ
π
(
s
)
ρ^π(s)
ρπ(s)依赖于策略参数,策略梯度并不依赖于状态分布的梯度。The policy gradient is surprisingly simple. In particular,despite the fact that the state distribution
ρ
π
(
s
)
ρ^π(s)
ρπ(s) depends on the policy parameters, the policy gradient does not depend on the gradient of the state distribution.















 623
623











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









