








-
作者:Amir Bar, Gaoyue Zhou, Danny Tran, Trevor Darrell, Yann LeCun
-
单位:Meta FAIR,纽约大学,布里克利AI研究
-
原文链接:Navigation World Models (https://arxiv.org/abs/2412.03572)
-
视频演示:https://www.amirbar.net/nwm/
主要贡献
-
论文提出了一种新的导航世界模型(NWM),能够根据过去的观测和导航动作预测未来的视觉观测。NWM能够在规划过程中动态地结合约束条件,而不仅仅是固定的行为模式。
-
引入了条件扩散Transformer(CDiT),能够在多种环境和实体上训练,并且具有显著降低的计算复杂度。CDiT模型能够扩展到1亿参数,并且在计算资源消耗上比标准的DiT减少了4倍。
-
NWM在多种机器人和人类代理的视频数据上进行训练,使其能够适应多个环境。通过在Ego4D的无标签视频数据上进行训练,展示了在未见环境中改进的视频预测和生成性能。
研究背景

研究问题
论文主要解决的问题是如何设计一个导航世界模型(Navigation World Model, NWM),该模型能够根据过去的观测和导航动作预测未来的视觉观测,从而辅助智能体进行导航。
研究难点
该问题的研究难点包括:
-
如何捕捉复杂环境动态、
-
如何在未知环境中进行轨迹规划、
-
以及如何在不增加计算资源的情况下动态调整约束条件。
相关工作
该问题的研究相关工作包括现有的监督导航策略、扩散模型在视频生成中的应用以及目标条件视觉导航方法。
研究方法
论文提出了导航世界模型(NWM)用于解决导航问题。
导航世界模型(NWM)
NWM是一个可控的视频生成模型,它根据过去的观测和导航动作预测未来的视觉观测。NWM的目标是学习一个世界模型,该模型是一个随机映射,从先前的潜在观测和动作到未来的潜在状态表示:
其中,是通过预训练的VAE编码的过去个视觉观测。
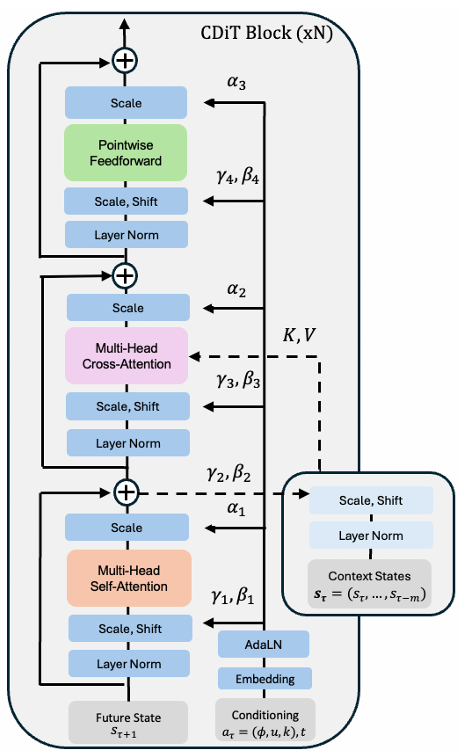
条件扩散Transformer(CDiT)
为了实现NWM,论文提出了条件扩散Transformer(CDiT),该模型能够在给定过去图像状态和动作的情况下预测下一个图像状态。
CDiT的计算复杂度与上下文帧数线性相关,并且在大规模参数训练时具有较好的扩展性。CDiT块的结构如下所示。
导航规划
在已知环境中,NWM通过模拟潜在的导航计划并验证其是否达到目标来规划新的导航轨迹。在未知环境中,NWM可以利用其学到的视觉先验从单个输入图像中想象轨迹。
规划过程中使用了模型预测控制(MPC)框架,优化使NWM达到目标的动作序列。
实验设计
数据集
实验使用了多个机器人导航数据集,包括SCAND、TartanDrive、RECON和HuRoN。
此外,还使用了未标记的Ego4D视频数据。
评估指标
评估预测导航轨迹的准确性使用
-
绝对轨迹误差(ATE),
-
相对位姿误差(RPE)。
为了检查世界模型预测与真实图像的语义相似性,
-
使用了LPIPS和DreamSim来衡量感知相似性,
-
使用PSNR来衡量像素级质量。
对于图像和视频合成质量,使用了FID和FVD。
基线方法
实验比较了NWM与DIAMOND、GNM和NoMaD等基线方法的性能。
实现细节
在默认实验设置中,使用了一个包含1亿参数的CDiT-XL模型,上下文帧数为4帧,总批量大小为1024,使用Stable Diffusion VAE分词器,AdamW优化器,学习率为8e-5。
结果与分析
视频预测和合成
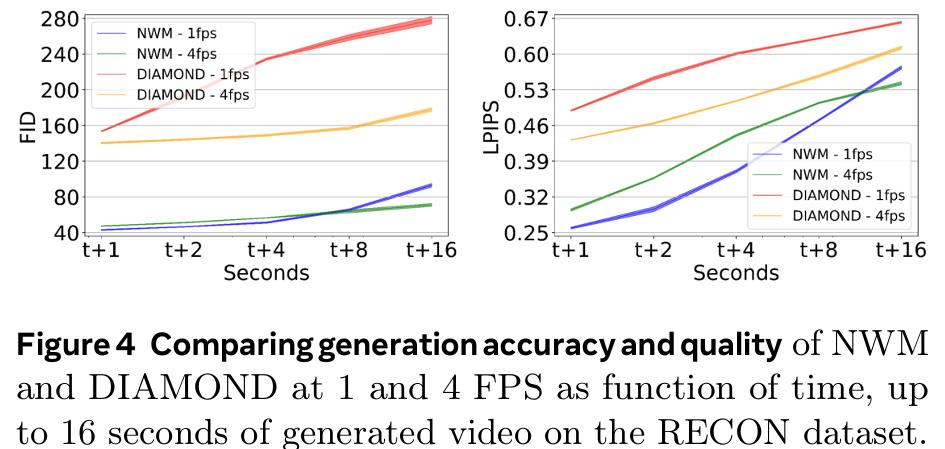
在RECON数据集上,NWM在1、2、4、8和16秒的预测中表现优于DIAMOND。NWM生成的视频质量也更高,FVD评分更低。
导航规划
在已知环境中,NWM独立规划的轨迹在ATE和RPE指标上均优于NoMaD和GNM。在未知环境中,使用NWM对NoMaD采样轨迹进行排名,结果显示NWM能够选择更接近真实轨迹的路径。
约束规划
在规划过程中加入约束条件(如向前移动、左右转等),NWM仍能有效规划轨迹,且性能损失较小。
未标记数据增强
在未知环境中,使用未标记的Ego4D数据进行训练后,NWM在视频预测和生成质量上均有显著提升。
总结
本文提出的导航世界模型(NWM)通过条件扩散Transformer(CDiT)实现了在大规模数据上的高效训练,并在导航任务中表现出色。
NWM不仅能够独立规划导航轨迹,还能通过与现有导航策略结合来提升性能。此外,通过在未标记数据上进行训练,NWM在未知环境中的表现也得到了显著改善。


















 1417
1417

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









