








- **作者**:Liuyi Wang, Zongtao He, Mengjiao Shen, Jingwei Yang, Chengju Liu, Qijun Chen - **单位**:同济大学 - **原文链接**:MAGIC: Meta-Ability Guided Interactive Chain-of-Distillation for Effective-and-Efficient Vision-and-Language Navigation (https://arxiv.org/pdf/2406.17960) - **代码链接**:https://github.com/CrystalSixone/VLN-MAGIC
主要贡献
-
论文提出Meta-Ability Knowledge Distillation (MAKD) 框架,通过解耦和精炼视觉语言导航(VLN)智能体所需的元能力,实现了从大型教师模型到小型学生模型的知识蒸馏。
-
引入Meta-Knowledge Randomization Weighting (MKRW) 和 Meta-Knowledge Transferable Determination (MKTD) 模块,减少学习偏差和错误传播的风险,增强模型的泛化能力和鲁棒性。
-
提出Interactive Chain-of-Distillation (ICoD) 学习策略,允许学生在学习成熟后反馈并补充教师的知识,形成师生共同进化的多步循环。
研究背景
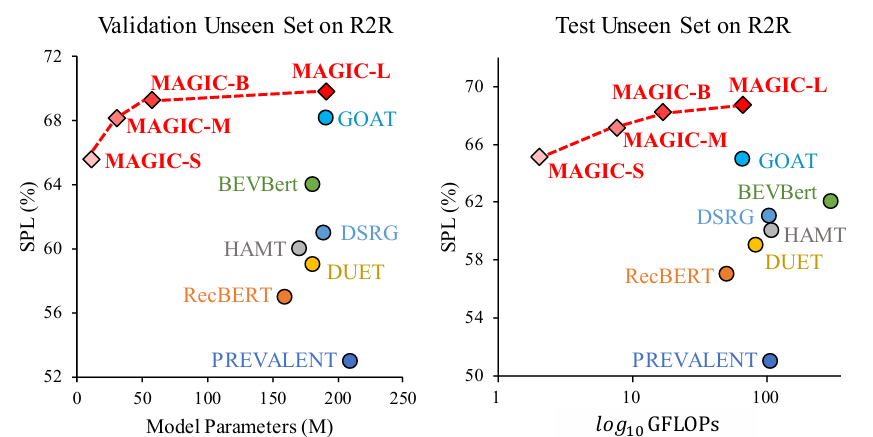
研究问题
论文要解决的问题是如何在视觉语言导航(VLN)任务中实现高效的模型压缩,使得大型模型能够在边缘设备如机器人上高效运行。
研究难点
该问题的研究难点包括:
-
当前VLN方法通常依赖于过大的模型,导致参数冗余和计算复杂度过高,
-
容易过拟合,且难以适应边缘设备。
相关工作
该问题的研究相关工作包括:
-
语义编码增强;
-
历史依赖性增强;
-
训练策略改进。 这些方法在提高模型性能方面取得了一定进展,但在实际应用中仍存在模型复杂度高的问题。
研究方法
论文提出了元能力引导的交互式蒸馏(Meta-Ability Guided Interactive Chain-of-distillation,MAGIC)方法,用于解决VLN任务中的模型压缩问题。
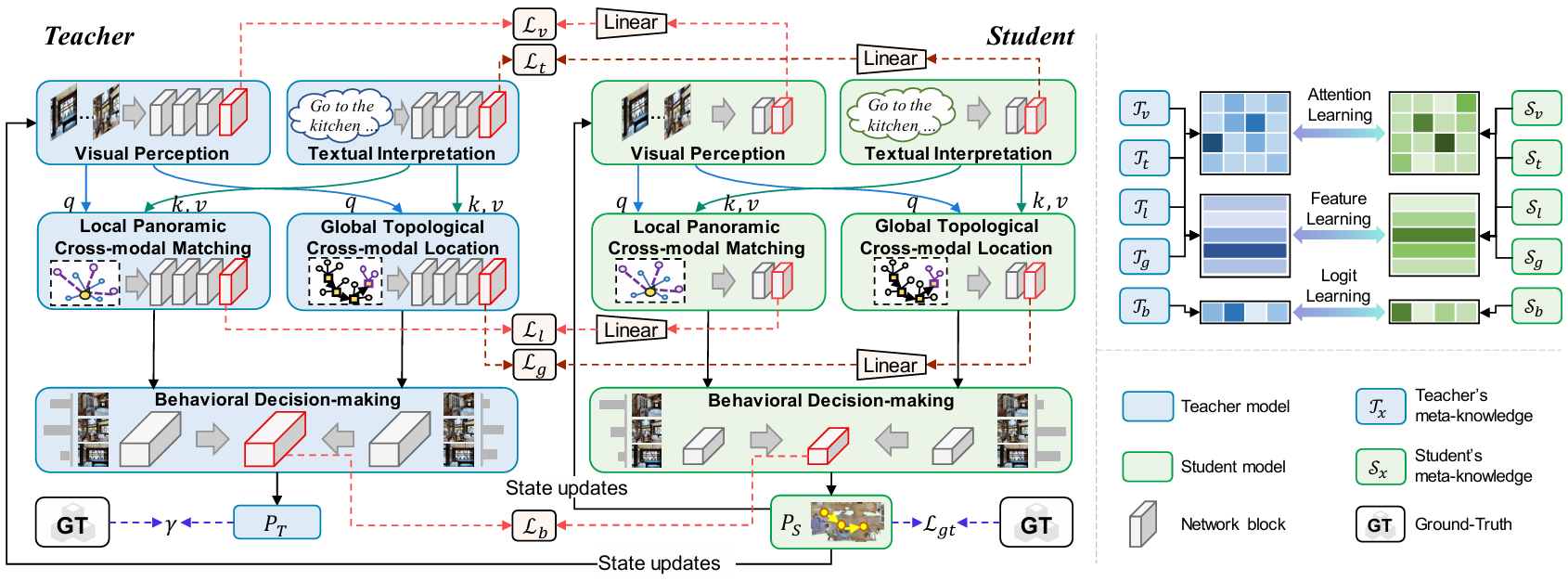
MAKD框架
提出了一个MAKD框架,用于解耦和精炼VLN智能体所需的元能力。
该框架将复杂的VLN任务分解为五个核心元能力:视觉感知、文本解释、局部全景跨模态匹配、全局拓扑跨模态定位和行为决策。
MKRW
为了优化不同元知识转移损失的潜在不平衡问题,提出了MKRW方法。
该方法通过在迭代过程中随机分配采样权重给不同的元知识损失,有效缓解学习偏差,增强模型的泛化能力和鲁棒性。
MKTD
考虑到教师模型并非完美无误,特别是在VLN领域,论文提出了MKTD方法。
该方法利用教师模型的不确定性来调整样本级别的KD损失,减少错误传播,提高元知识转移的可靠性。
ICoD学习策略
提出了一个ICoD学习策略,引入了一个中间大小的模型作为桥梁,连接大型教师模型和小型学生模型。
该策略不仅允许学生向教师反馈,还形成了师生共同进化的多步良性循环。
实验设计
数据集

实验在两个流行的VLN数据集上进行评估,Room-to-Room(R2R)和Room-across-Room(RxR)。
-
R2R数据集包含90栋建筑物的真实环境,7,189条路径和21,576条指令。
-
RxR数据集是对R2R的扩展,解决了最短路径偏见问题。
-
此外,从实际生活环境中收集并标注了一个新的数据集VLN@TJ,包含5个场景,共136条路径和408条指令。
评估指标
-
对于R2R数据集,使用导航误差(NE)、成功率(SR)、Oracle成功率(OSR)和成功率加权逆路径长度(SPL)四个指标。
-
对于RxR数据集,使用归一化动态时间弯曲(nDTW)和成功率加权动态时间弯曲(sDTW)两个指标。
实现细节
采用GOAT作为基准教师模型,CLIP ViT-B/16用于图像特征提取。
MAKD框架的损失平衡参数设为0.5,MKRW的缩放因子K和温度分别设为5和4,MKTD的衰减系数设为0.7。
预训练在两个Tesla V100 GPU上进行,使用AdamW优化器和的学习率。
微调阶段,R2R的批量大小为16,RxR的批量大小为12,学习率为,最多迭代100K次。
结果与分析
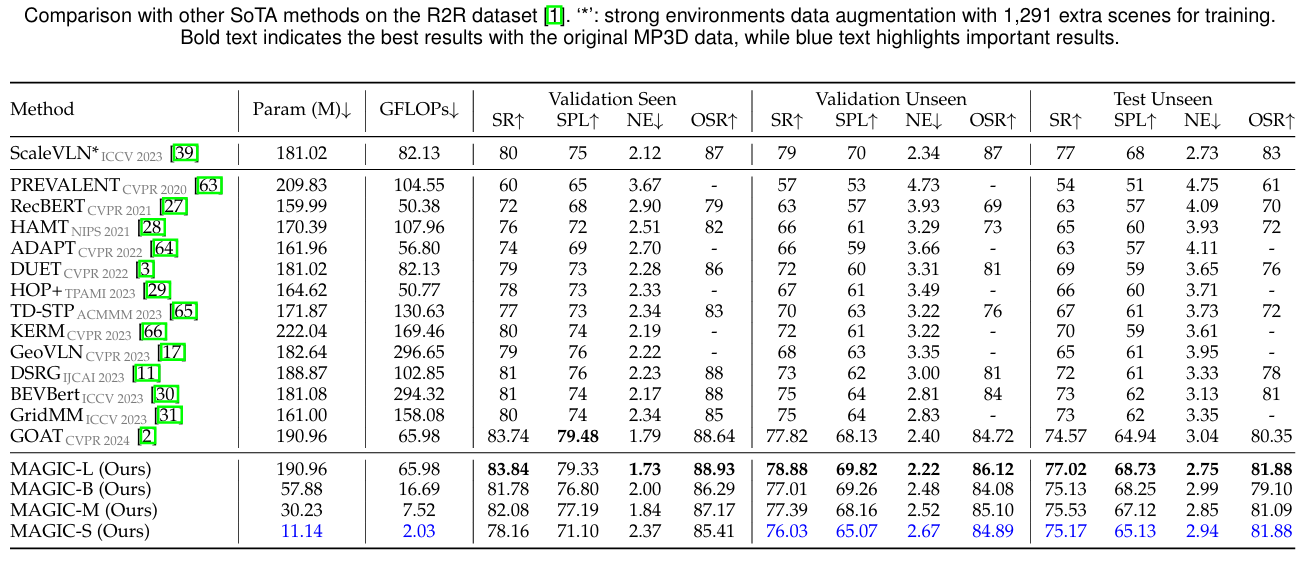
R2R数据集上的结果
在R2R数据集上,
-
MAGIC-S模型(参数仅为教师模型的5%)在valid-unseen上相对提高了GridMM模型的SR和SPL,分别提高了1.4%和1.7%;在test-unseen上,MAGIC-S模型的表现优于所有之前的现有方法,包括完整的GOAT模型;
-
MAGIC-L模型在valid-unseen上相对提高了ScaleVLN模型的SR和SPL,分别提高了4.8%和5.8%。
RxR数据集上的结果
在RxR数据集上,MAGIC-L模型在valid-unseen上相对提高了GOAT模型的SR、SPL、nDTW和sDTW,分别提高了5.3%、6.0%、1.5%和3.9%。
定量分析
通过消融实验分析了MAKD、不同元能力的贡献、不同特征的影响、MKRW和MKTD的效果以及ICoD策略的影响。结果表明:
-
MAKD显著提高了小模型的学习泛化能力;
-
MKRW通过动态调整权重,提高了模型的性能;
-
MKTD通过调整样本级别的权重,减少了错误传播;
-
ICoD策略通过师生互动,进一步提高了模型的性能。
SIM-TO-REAL
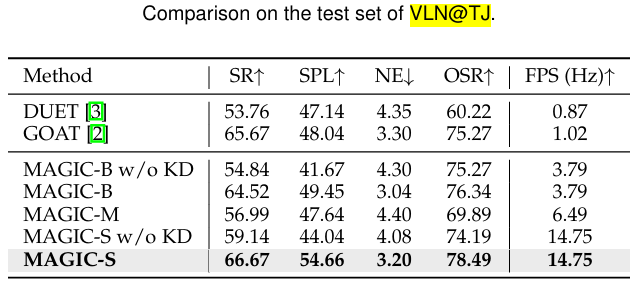
MAGIC-S模型在真实世界数据集VLN@TJ上表现最佳,尽管参数最少且运行速度最快,但其泛化性能超越了GOAT模型,SPL提升了13.8%。
总结
论文提出MAGIC方法,通过解耦和精炼元能力,实现了高效的模型压缩。
实验结果表明,MAGIC方法在VLN任务中表现出色,能够在保持高性能的同时显著减少模型复杂度。
特别地,MAGIC-S模型在相同训练数据下优于所有之前的现有方法,而MAGIC-L模型则在多个指标上显著提高了现有方法的性能。
该方法展示了在实现高性能的同时保持低模型复杂度的巨大潜力。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









