








-
作者:Meng Chu, Zhedong Zheng, Wei Ji, Tingyu Wang, and Tat-Seng Chua
-
单位:新加坡国立大学,澳门大学,杭州电子科技大学
-
原文链接:Towards Natural Language-Guided Drones: GeoText-1652 Benchmark with Spatial Relation Matching (https://arxiv.org/pdf/2311.12751)
-
项目主页:https://multimodalgeo.github.io/GeoText/
-
代码链接:https://github.com/MultimodalGeo/GeoText-1652
主要贡献
-
论文提出了GeoText-1652,全新的自然语言引导的地理定位数据集基准,涵盖了卫星、无人机和地面摄像机的多平台数据,包含276,045个文本-边界框对和316,335个指令描述。
-
引入了混合空间匹配优化目标,利用细粒度的空间关联进行区域级空间关系匹配。
-
通过相对位置估计,增强了模型对不同区域之间关系的理解,提升了细粒度视觉上下文的解释能力。
-
提出的空间感知模型在使用文本查询时达到了31.2%的Recall@10准确率,超过了现有的ALBEF和X-VLM模型。
研究背景
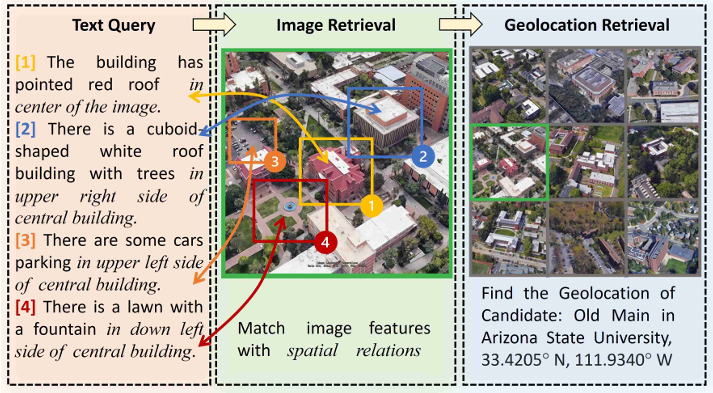
研究问题
论文旨在解决通过自然语言命令导航无人机的挑战,主要由于缺乏可用的多模态数据集以及将视觉和文本数据对齐的严格要求。
研究难点
该问题的研究难点包括:
-
缺乏大规模的公共语言引导数据集,
-
由于无人机视角场景图像的细粒度特性,难以将语言和视觉表示对齐。
相关工作
相关工作包括:
-
跨视图地理定位,
-
多模态对齐,
-
通过大模型进行数据合成。
现有的工作主要集中在图像检索和视觉-语言导航任务上,但缺乏针对自然语言引导无人机导航的具体方法。
GeoText-1652数据集
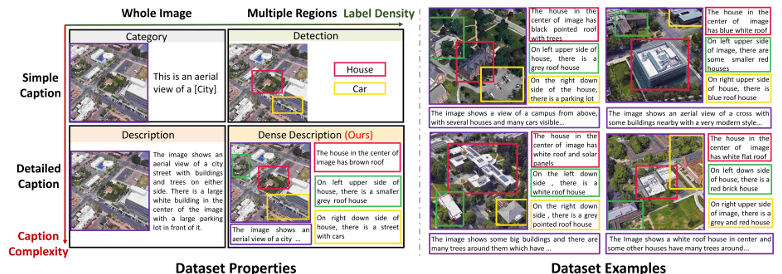
GeoText-1652是一个新的自然语言引导的地理定位基准数据集,旨在解决无人机通过自然语言命令导航的挑战。
该数据集通过交互式人机过程系统构建,结合了大型语言模型(LLM)驱动的标注技术和预训练的视觉模型。
GeoText-1652扩展了现有的University-1652图像数据集,增加了空间感知的文本标注,从而在图像、文本和边界框元素之间建立了对应关系。
数据集特点
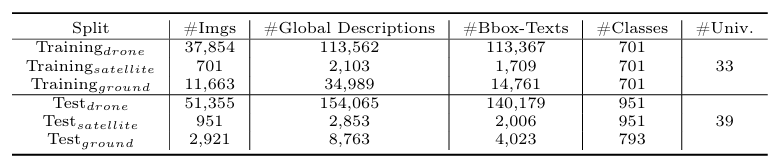
-
多平台数据:GeoText-1652包含来自卫星、无人机和地面摄像机的图像。
-
细粒度标注:每个图像都有3个全局描述和平均2.62个边界框,每个全局描述平均包含70.23个单词,区域级描述平均包含21.6个单词。
-
自然语言引导的任务:支持两种新任务:通过文本进行无人机导航和无人机视图目标定位。
-
空间关系匹配:引入了一种新的优化目标,称为混合空间匹配,用于区域级别的空间关系匹配。
构建过程
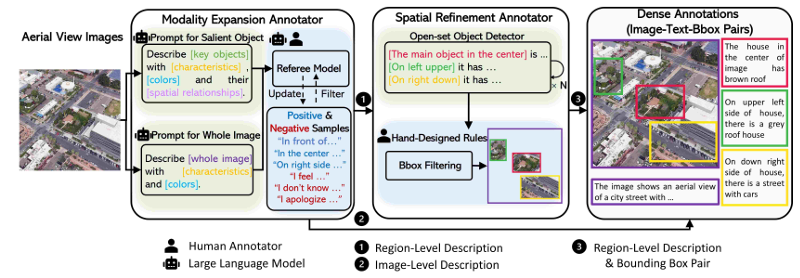
-
模态扩展阶段:使用LLM生成图像级和区域级的描述,并通过人类验证确保质量。
-
空间细化阶段:利用文本驱动的视觉定位模型识别对应的边界框,并通过多轮迭代和人类评估确保高质量标注。
研究方法
论文提出跨模态地理定位框架,用于进行细粒度的空间分析。该框架主要包括图像编码器、文本编码器和跨模态编码器。
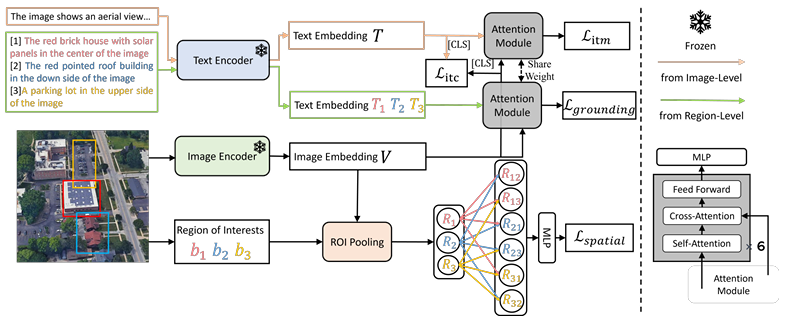
图像-文本语义匹配
-
图像-文本对比学习:给定图像-文本对,提取图像视觉特征V和图像级文本特征T,计算余弦相似度。通过对比学习,将小批量内的其他样本视为负例,计算视觉到文本和文本到视觉的相似度。
-
损失函数:定义了对比学习的损失函数,鼓励身份图像-文本对的相似度最大。
-
图像-文本匹配:模型预测视觉概念和文本是否匹配。采样难负样本,应用跨模态编码器的输出嵌入预测匹配概率,并使用二元分类损失。
混合空间匹配
-
地面预测:模型根据文本描述预测图像中的边界框,采用交叉注意力模型和多层感知器(MLP)。损失函数包括回归损失和交并比(IoU)损失。
-
空间关系匹配:考虑多个区域的相对位置,预测它们之间的空间关系。采用多层感知器(MLP)预测9类空间关系,损失函数为交叉熵损失。
-
优化目标:总损失定义为图像-文本匹配损失、地面预测损失和空间关系匹配损失的加权和。
实验设置
-
实验中采用了XVLM作为基础模型,预训练在1600万张图像上。
-
文本编码器使用BERT,图像编码器使用Swin。优化器为AdamW,权重衰减为0.01,学习率设置为。
-
所有图像在训练过程中调整为384384像素,图像块大小设为32。
-
进行了简单的数据增强,如亮度调整和恒等操作,未使用随机旋转或水平翻转以避免丢失空间信息。
-
在全局描述作为文本查询时,移除停用词以保持查询简洁。
结果分析
定位表现
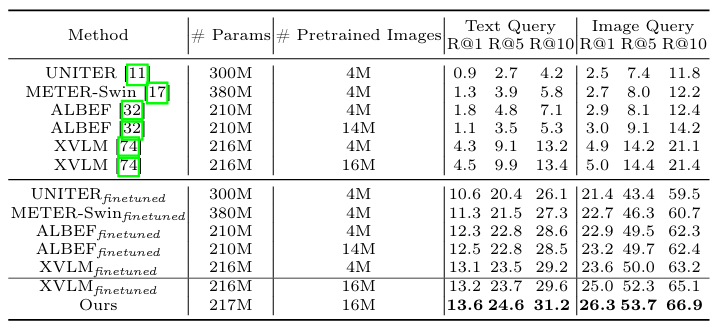
GeoText-1652数据集对跨模态检索的进步做出了贡献,提出的方法在性能上超过了其他模型。特别是当微调该数据集时,可以看到性能的显著提升。
与基线XVLM微调相比,提出的方法在文本到图像检索的Recall@10指标上提高了+1.6%,在图像到文本检索设置中也有所增加。
消融研究与讨论
-
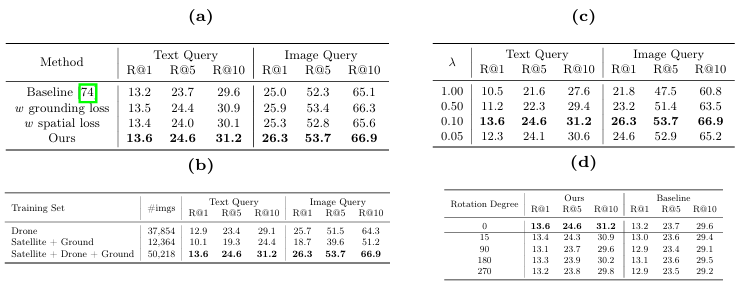
损失目标的影响:逐步添加损失项进行训练,结果显示仅使用空间或地面损失时模型性能有所提升,但结合两种损失时性能最佳。
-
不同训练集的影响:使用“卫星+无人机+地面”训练集的性能优于仅使用“无人机”或“卫星+地面”的训练集,表明多样化的数据有助于模型训练。
-
超参数研究:平衡空间匹配损失和跨模态匹配损失的权重,发现当时,模型达到最佳召回率。
-
旋转角度研究:测试图像在不同旋转角度下的表现,结果表明该方法对小角度旋转具有鲁棒性,但在大角度旋转下性能下降。
空间文本定位
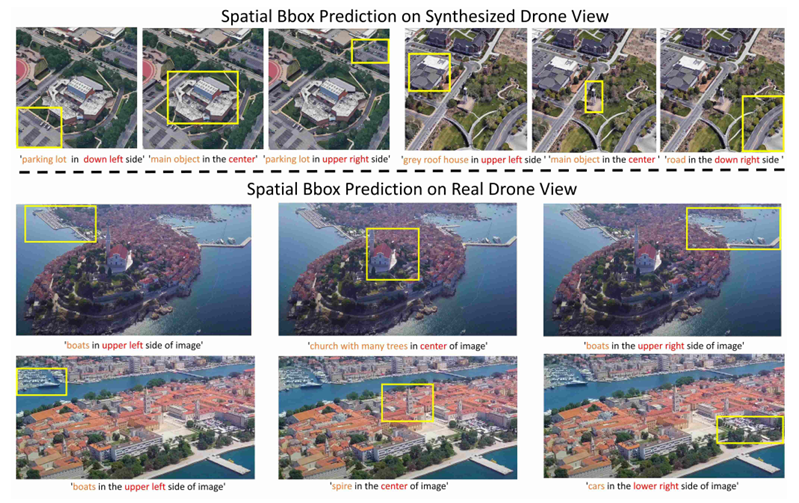
在合成和真实无人机视图图像上评估空间边界框预测,结果显示模型不仅在熟悉图像上表现出色,还能在新场景中准确捕捉对象。
模型能够基于文本指令区分同一图像中的多个实例,强调了空间语言理解的重要性。
文本查询检索
定性文本到图像检索结果显示,该方法在空间感知能力上优于基线模型。空间描述符使模型能够基于对象标签和空间关系准确识别图像,关键词如“中心”、“左侧”和“左上角”被模型有效捕捉,帮助找到感兴趣的对象。
总结
本文介绍了GeoText-1652,一个新的视觉-语言数据集,用于增强自然语言引导的无人机地理定位。
该数据集支持文本到图像和图像到文本检索任务,提出了混合空间匹配方法,利用区域级别的空间关系匹配提高定位精度。
实验结果表明,本文方法在召回率和实际应用中具有良好的泛化能力。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









