










-
作者:Yong Zhao, Kai Xu, Zhengqiu Zhu, Yue Hu, Zhiheng Zheng, Yingfeng Chen, Yatai Ji, Chen Gao, Yong Li, Jincai Huang
-
单位:国防科技大学,清华大学
-
标题:CityEQA: A Hierarchical LLM Agent on Embodied Question Answering Benchmark in City Space
-
原文链接:https://arxiv.org/pdf/2502.12532
主要贡献
-
论文构建首个面向城市环境的开放具身问答数据集CityEQA-EC,引入城市地标与空间关系构建任务指令,突破了传统室内场景的局限性,提供了一种室外场景通用任务形式,推动具身问答技术向真实城市环境迁移。
-
提出基于大模型的分层智能体架构PMA(Planner-Manager-Actor),采用层次化动作生成策略,以类人方式解决具有长周期特点的CityEQA任务。设计了基于LLM的Planner模块解析任务指令并生成计划,Manager协调多模态感知模块并维护包含认知地图的记忆模块,监督和推进计划执行,Actor执行提供变尺度动作生成器,以有效应对大范围城市环境带来的行动挑战。
-
PMA在问答准确率上**达到了人类水平的60.73%**。此外相比于室内基线模型,在探索效率上大幅提高。
-
当前模型依赖语言指令且弱化视觉细节理解,并主要针对以物体为中心的问答任务,缺乏对城市中社会活动的考虑。未来需融合更强视觉建模与多模态联合推理,推动具身AI向真实世界实用性迈进。
研究背景
研究问题
现有的具身问答(EQA)任务主要集中在室内环境,而城市环境的复杂性(包括环境、动作和感知方面的复杂性)尚未得到充分探索。
本文主要解决的问题是如何在连续的、大范围的城市环境中进行具身问答。
研究难点
该问题的研究难点包括:
-
环境复杂性:城市环境具有多样化的对象和结构,许多对象在视觉上相似且难以区分。
-
动作复杂性:城市空间的广阔地理尺度要求智能体采用更大的移动幅度以提高探索效率,但可能会忽略场景中的详细信息。
-
感知复杂性:观察结果会因距离、方向和视角的不同而大幅变化,这对答案生成的准确性构成挑战。
相关工作
-
视觉问答:早期的研究集中在VQA任务上,要求智能体仅根据视觉信息(如图像或视频)来回答问题。VQA任务不需要智能体主动导航。
-
具身问答:EQA任务涉及智能体主动导航到环境中以获取视觉输入并增强答案的可靠性。早期的EQA研究主要集中在室内环境中,使用虚拟模拟器进行探索和回答生成。
-
开放域具身问答数据集: 随着多模态大模型(MM-LLMs)的发展,研究人员发布了开放式的EQA数据集,允许更广泛的问题类型和开放式答案。
- 大模型驱动的具身智能体:
-
研究人员尝试利用预训练的LLMs来解决EQA任务,而不需要进行额外的微调。
-
室内EQA的工作通常采用基于前沿的探索策略(FBE)进行室内环境探索。
-
- 城市具身问答挑战:
-
城市环境中的EQA任务面临新的挑战,因为城市空间广阔且开放,智能体需要使用地标和空间关系进行导航以实现长期探索。
-
论文提出的PMA通过分解和规划长期任务来解决这些问题。
-
CityEQA-EC数据集
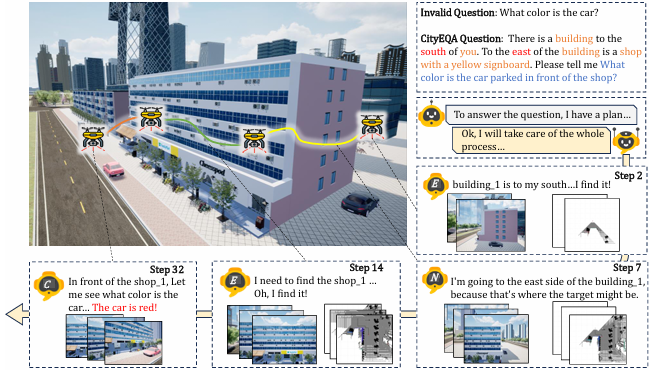
任务定义
-
EQA任务的实例由四元组 定义,其中 是智能体可以交互的模拟或真实3D场景, 是问题, 是正确答案, 是智能体的初始位置(包括3D位置和方向)。
-
目标是让具身智能体(如无人机)通过从场景 中收集所需信息并生成答案 来完成任务。
数据集收集
-
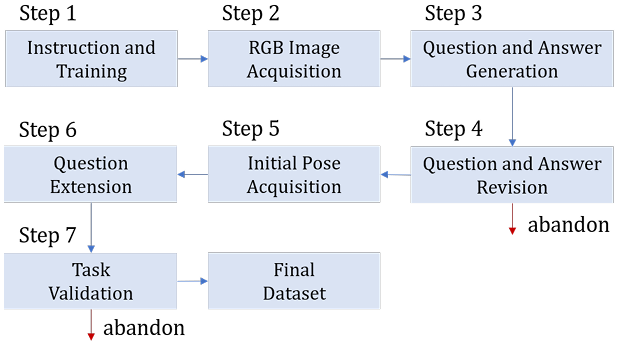
使用高度真实的3D模拟平台EmbodiedCity(基于真实城市的建筑、道路等元素),该平台使用Unreal Engine 4和Microsoft AirSim插件实现。
- 数据集收集过程分为两个步骤,由五个人类标注员完成:
-
原始问答生成:人类标注员自由探索EmbodiedCity环境,基于RGB图像生成问题和答案对。记录每个问题答案对的观察位置和目标对象的姿态。
-
任务补充:确定智能体的初始位置,并根据需要细化问题描述。对于每个原始任务,设置智能体的初始位置在目标对象位置的200米范围内,并通过地标描述丰富问题。
-
数据集验证
-
每个人类标注员创建的任务实例由两个独立的人类评审员严格评估,确保问题是可回答和清晰的,目标对象及其答案是唯一和准确的。
-
任何有问题或不符合标准的数据集实例将被排除。最终数据集包含1,412个任务实例。
数据集统计
-
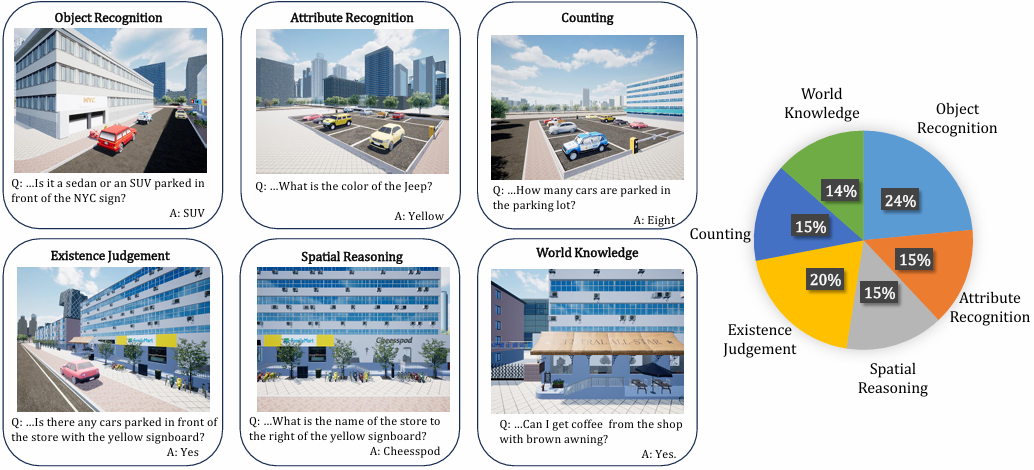
数据集包含目标识别、属性识别、计数、存在性判断、空间推理和世界知识六个任务类型。
-
使用开放词汇问题,涉及城市地标和空间关系来界定预期答案,旨在解决对象歧义问题。
PMA: 基于大模型的分层智能体
概述
-
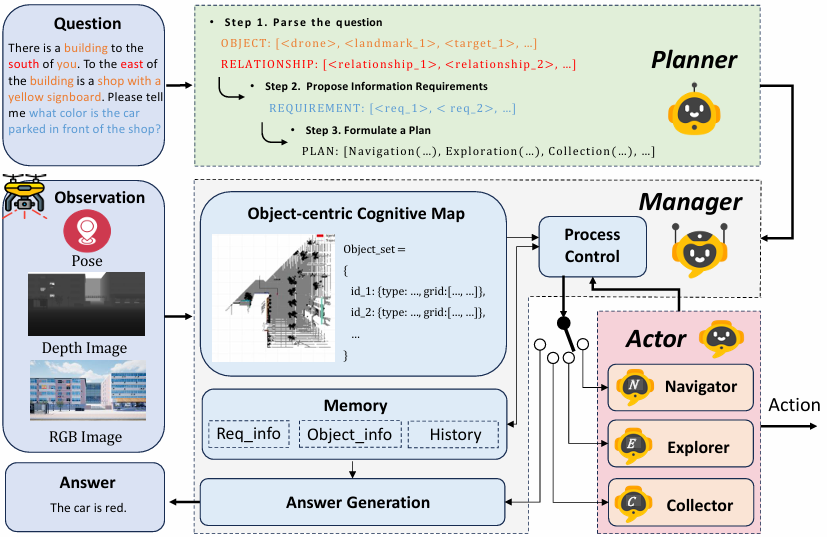
PMA智能体由三个主要模块组成:Planner、Manager和Actor,所有模块都由预训练的大模型驱动。
-
Planner负责解析问题并制定执行计划,Manager维护一个物体为中心的认知地图,并在每个时间步处理观察结果,Actor则根据Manager的指令生成具体动作。
Planner
-
Planner模块使用预训练的LLMs和Chain of Thought(CoT)推理来解析问题并制定计划。
-
问题描述中的对象和空间关系首先被提取,然后识别出回答问题所需的信息。基于这些需求,计划由三种类型的子任务组成:收集、探索和导航。
-
为了确保计划的可行性,开发了多种策略来指导LLMs,详见附件内容。
Manager
-
Manager模块负责监督和管理长期计划的逐步实施。
-
以物体为中心的认知地图,使用2D网格离散化周围环境,并记录地标物体的分布。
-
Memory模块记录感知过程中的重要信息,包括Req_info(收集的信息)、Object_info(物体信息)和History(子任务的完成进度和动作的执行结果)。
-
Process Control模块决定下一个要执行的子任务,并在计划完成后调用Answer Generation模块生成最终响应。
Actor
-
为了解决三种不同类型的子任务,引入了三个专门化的低级动作生成器:Navigator、Explorer和Collector。
-
Navigator和Explorer依赖于不同的确定性策略来生成动作,而Collector使用VLA策略,直接从RGB图像中得到动作。
-
Collector模块使用多模态大模型(MM-LLM)来调整观察视角,以提高信息收集的质量。
实验
实验设置
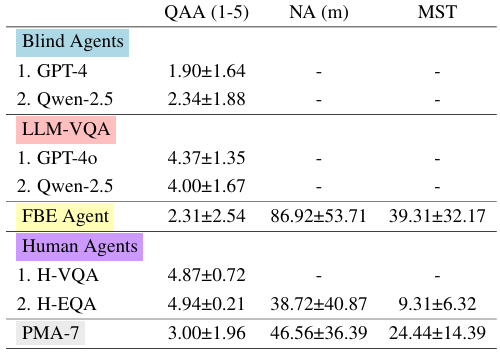
- 评估指标:采用三种广泛使用的指标来评估EQA任务:问题回答准确性(QAA)、导航准确性(NA)和平均时间步(MTS)。
-
QAA通过比较生成的答案与真实答案来评估答案的正确性;
-
NA衡量任务完成后智能体的最终位置与目标对象之间的距离;
-
MTS计算完成所有任务所需的平均时间步数。
-
- 实现细节:
-
使用GPT-4o作为视觉分析的MM-LLM,GPT-4作为文本分析模型。
-
以物体为中心的认知地图以智能体的初始位置为中心,边长为400米,分辨率为1米。
-
实验中限制导航和探索的总时间步数为50步,收集时间步数为10步。
-
从CityEQA-EC中随机选择200个任务进行实验。
-
基线模型
-
Blind智能体:仅基于问题文本生成答案,不使用视觉输入。
-
LLM-VQA:直接提供RGB图像来回答问题,跳过主动探索过程。
-
前沿探索智能体(FBE Agent):常用作室内基线,不利用地标或空间关系。
-
Human智能体:用于建立人类水平的表现指标,分为H-VQA和H-EQA。H-VQA类似于LLM-VQA,直接提供RGB图像;H-EQA从初始位置出发,根据问题描述主动探索环境。
基线比较
-
PMA在问题回答准确性(QAA)上优于Blind智能体和FBE智能体,因为它利用了视觉输入,并通过地标和空间关系进行更有效的感知活动。
-
与Human智能体相比,PMA在QAA上仍有显著差距,仅达到人类水平的60.73%。然而,尽管在平均时间步(MTS)上有较大差距,导航准确性(NA)的差距相对较小,表明PMA的导航和探索策略是有效的。
-
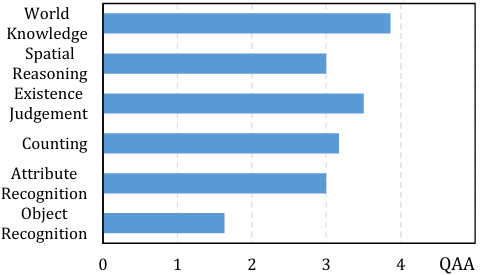
PMA在不同任务类型上的表现各异。它在世界知识任务上表现最佳,可能是因为这些任务部分依赖于LLM的固有知识,需要的视觉输入较少。然而,在对象识别任务上表现最差,因为这些任务需要开放式答案且更依赖于视觉输入。
-
Human智能体在H-VQA和H-EQA任务中表现优异。值得注意的是,H-EQA的QAA略高于H-VQA,表明主动调整观察视角有助于解决遮挡和反射等挑战。
-
FBE智能体表现较差,其QAA甚至低于Blind智能体Qwen2.5,这突显了在城市环境中利用地标和空间关系的重要性。
-
LLM-VQA能够正确回答大多数问题,但其QAA低于人类,这验证了数据集的有效性。此外,Qwen-2.5和GPT-4o之间的性能差距表明,MM-LLMs在视觉理解和推理能力上的固有差异也是影响智能体性能的重要因素。
-
Blind智能体达到了一定的准确度,尽管显著低于人类和GPT-4o,这揭示了现实世界中可以用来回答问题的规律性。
Collector模块分析
论文在前面的实验中验证了PMA中导航和探索策略的有效性。本节进一步探讨了在观察中进行细粒度调整对性能的影响。
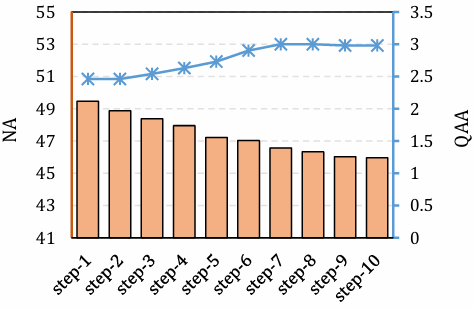
- 实验方法:
-
记录Collector模块在每一步(最多10步)的位置以及生成的响应,并计算了相关的性能指标。
-
通过增加Collector的步数,研究其对导航准确性(NA)和问题回答准确性(QAA)的影响。
-
- 结果分析:
-
结果表明,随着Collector步数的增加,导航准确性(NA)降低而问题回答准确性(QAA)提高。这表明Collector模块帮助智能体更接近目标对象,并获得更准确的答案。
-
然而,QAA的提升存在一个明显的极限;在第10步时,QAA略低于第9步。这可能是由于Collector在判断动作幅度时的不足,导致“过度调整”观察,从而降低了视觉输入的质量。
-
- 动作分析:
-
分析了Collector采取的动作,发现最常见的动作是KeepStill,这反映了有效的导航和探索子任务帮助智能体成功接近目标对象。
-
其他常见的动作包括MoveForward、TurnLeft和TurnRight。当目标对象进入智能体的视野时,智能体倾向于停止,这可能导致对象距离太远或只能部分可见。在这种情况下,智能体可能需要MoveForward以减少距离,或使用TurnLeft和TurnRight来调整方向以获得更好的观察和信息收集。
-
总结
-
论文首次探索了城市环境中的EQA任务,提出了CityEQA-EC数据集和Planner-Manager-Actor(PMA)智能体。
-
实验结果表明,PMA在处理城市环境中的具身问答任务时表现出色,但仍存在与人类性能的差距。
-
未来的研究可以集中在增强PMA的自我反思和错误纠正机制上,以减轻长期任务中的误差累积。
-
同时,未来还应扩展CityEQA的范围,包括涉及社会互动和动态事件的任务,进一步扩展PMA并使其能够处理更广泛的城市空间智能挑战。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









