







目录
搬家啦 http://blog.recusant.top/
1.参数量和计算量
参数量(Params):是指模型中权值的数量,决定了模型的大小。
一个
h
×
w
h\times w
h×w的卷积核参数量为:
K
h
×
K
w
×
C
o
u
t
K_h \times K_w \times C_{out}
Kh×Kw×Cout
计算量(FLOPs):一般来说统计计算量时只统计卷积层和全连接层的乘法操作。对于某层卷积,输入为
K
h
×
K
w
×
C
o
u
t
×
H
×
W
×
C
o
u
t
=
P
a
r
a
m
s
×
H
×
W
×
C
o
u
t
K_h \times K_w \times C_{out}\times H\times W\times C_{out}=Params\times H\times W\times C_{out}
Kh×Kw×Cout×H×W×Cout=Params×H×W×Cout
 以输入
28
×
28
×
192
28\times 28 \times 192
28×28×192,卷积核大小
5
×
5
5\times 5
5×5,
p
a
d
d
i
n
g
=
s
a
m
e
padding=same
padding=same为例,参数量为
P
a
r
a
m
s
=
5
×
5
×
192
×
32
=
153600
Params=5\times 5\times192\times 32=153600
Params=5×5×192×32=153600而计算量为
F
L
O
P
s
=
28
×
28
×
32
×
5
×
5
×
192
≈
120
M
FLOPs=28\times 28\times 32\times5\times5\times192\approx120M
FLOPs=28×28×32×5×5×192≈120M
以输入
28
×
28
×
192
28\times 28 \times 192
28×28×192,卷积核大小
5
×
5
5\times 5
5×5,
p
a
d
d
i
n
g
=
s
a
m
e
padding=same
padding=same为例,参数量为
P
a
r
a
m
s
=
5
×
5
×
192
×
32
=
153600
Params=5\times 5\times192\times 32=153600
Params=5×5×192×32=153600而计算量为
F
L
O
P
s
=
28
×
28
×
32
×
5
×
5
×
192
≈
120
M
FLOPs=28\times 28\times 32\times5\times5\times192\approx120M
FLOPs=28×28×32×5×5×192≈120M
2.1×1卷积
1×1的卷积核又叫网中网(Network in Network),即使用大小为1×1的卷积核进行特征提取,这在Inception、ResNet中非常常见。我们可以通过1×1卷积核的个数轻易的对输入通道数进行控制,同时不改变输入的图片尺寸。
继续以上个例子Inception结构中的一部分计算,输入
28
×
28
×
192
28\times 28 \times 192
28×28×192,16个
1
×
1
1\times 1
1×1卷积核,再继续用
5
×
5
5\times 5
5×5卷积提取特征升到同样的维度。

参数量为
192
×
16
+
5
×
5
×
16
×
32
=
15872
192\times 16+5\times5\times16 \times32=15872
192×16+5×5×16×32=15872,计算量为
(
192
×
28
×
28
×
16
)
+
(
28
×
28
×
32
×
5
×
5
×
16
)
≈
12
M
(192\times 28\times 28\times 16)+(28\times 28\times 32\times 5\times5\times16)\approx12M
(192×28×28×16)+(28×28×32×5×5×16)≈12M
| methods | Params | FLOPs |
|---|---|---|
| 5×5 conv | 153600 | 120M |
| use 1×1 conv | 15872 | 12M |
可见通过1×1卷积降维后再使用5×5卷积能大幅度减少参数量及计算量。同时可以通过降维升维的操作增加非线性。GoogLeNet和ResNet都采用了这种方式。


3.MobileNet V1论文

https://arxiv.org/pdf/1704.04861.pdf
3.1摘要
本文利用深度可分离卷积去构建轻量化网络并且提出两张超参数对速度和准确率做出权衡。这两个超参数能让开发人员在资源受限的情况下选择对其应用合适的模型大小。本文还做了广泛的实验对比所耗资源和准确率,实验证明在ImageNet中有较好的表现。
3.2背景
ILSVRC 2012以来CNN模型为了取得更高的准确率都变的越来越深、越来越复杂,然而这对模型的大小和速度并没有好处,并不能真正落地。现实中的应用都受限于平台的算力。
3.3相关工作
轻量化模型引发了人们的兴趣,大致的方法可以概括为压缩预训练模型或直接训练较小的模型。许多轻量化模型仅仅关注模型的大小,本文同时关注于模型的大小和速度。
MoblieNet利用了深度可分离卷积,深度可分离卷积最早在L. Sifre. Rigid-motion scattering for image classification.PhD thesis, Ph. D. thesis, 2014. 1, 3中提出,随后在Inception v2中(https://arxiv.org/abs/1502.03167)用于减少计算量。另外Squeezenet用了bottleneck来设计轻量化模型。
其他缩小的方法还有压缩训练好的模型,模型压缩包括量化、剪枝、向量化、哈夫曼编码等方法。除此之外低秩分解、知识蒸馏也用于压缩和加速神经网络。
3.4网络结构
3.4.1深度可分离卷积
上文中的例子为标准卷积,标准卷积是将每个通道与卷积核对应通道做卷积操作后进行各个通道的特征融合。输入F为
D
F
×
D
F
×
M
D_F\times D_F\times M
DF×DF×M,卷积核K为
D
K
×
D
K
×
M
×
N
D_K\times D_K\times M \times N
DK×DK×M×N,输出G为
D
F
×
D
F
×
N
D_F\times D_F\times N
DF×DF×N,可计算为:
G
k
,
l
,
n
=
∑
i
,
j
,
m
K
i
,
j
,
m
,
n
⋅
F
k
+
i
−
1
,
l
+
j
−
1
,
m
G_{k,l,n}= \sum_{ i,j,m }K_{i,j,m,n}· F_{k+i−1,l+j−1,m}
Gk,l,n=i,j,m∑Ki,j,m,n⋅Fk+i−1,l+j−1,m

![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Yan6eeX4-1580445504259)(https://miro.medium.com/max/2436/1*fgYepSWdgywsqorf3bdksg.png)]](https://img-blog.csdnimg.cn/20200131124233936.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl8zODA0NzI3NQ==,size_16,color_FFFFFF,t_70#pic_cente=400x300)
而深度可分离卷积是将标准卷积分解为深度卷积和1×1卷积(点卷积),深度卷积则对每个通道单独使用一个二维卷积核,提起特征后并不做通道间的特征融合,得到的通道数与输入通道相同。打破了输出通道数量和卷积核数量之间的关系。


(图来源https://youtu.be/D_VJoaSew7Q)
深度卷积并没有融合输出的各通道形成新的特征,所以只好还需进行点卷积融合通道产生新的特征,即使用1×1卷积将维度升到与使用标准卷积输出相同的维度。
总的计算量为
D
K
×
D
K
×
M
×
D
F
×
D
F
+
D
F
×
D
F
×
M
×
N
D_K \times D_K \times M\times D_F\times D_F+D_F\times D_F\times M\times N
DK×DK×M×DF×DF+DF×DF×M×N
与使用标准卷积相比
D
K
×
D
K
×
M
×
D
F
×
D
F
+
D
F
×
D
F
×
M
×
N
D
K
×
D
K
×
M
×
N
×
D
F
×
D
F
=
1
N
+
1
D
K
2
\frac{D_K \times D_K \times M\times D_F\times D_F+D_F\times D_F\times M\times N }{D_K\times D_K\times M\times N\times D_F \times D_F}=\frac{1}{N}+\frac{1}{D_K^2}
DK×DK×M×N×DF×DFDK×DK×M×DF×DF+DF×DF×M×N=N1+DK21
卷积核大小为3×3时,使用深度可分离卷积能减少8~9倍的计算量。

3.4.2模型结构和训练
第一层使用标准卷积其余层使用深度可分离卷积,除了全连接层每层之后都经过BN和ReLU,最后全局池化后用softmax做分类,除去pooling和softmax共有28层。作者也给出了计算量和参数量的分布情况,并给了1×1卷积的的更快底层实现原因。


优化方法采用了RMSprop,作者认为训练小模型很难出现过拟合的情况所以很少使用正则化和数据增强。
3.4.3 压缩模型
以上是MobilNet的baseline,根据实际应用还需进一步进行压缩,作者提出了两种超参数,第一种 α \alpha α叫做宽度参数,用于减少通道数量,使原先输入通道数M变为 α M \alpha M αM,输出通道也变成 α N \alpha N αN。 α ∈ ( 0 , 1 ] \alpha \in(0,1] α∈(0,1], α \alpha α可设置为1、0.75、0.5、0.25,计算量可表达为 D K × D K × α M × D F × D F + D F × D F × α M × α N D_K \times D_K \times \alpha M\times D_F\times D_F+D_F\times D_F\times \alpha M\times \alpha N DK×DK×αM×DF×DF+DF×DF×αM×αN,实质上 α \alpha α是减少了参数量,是对模型大小、模型速度和准确率的权衡。
第二种是输入分辨率参数 ρ ∈ ( 0 , 1 ] \rho \in(0,1] ρ∈(0,1],常用设置为把输入分辨率缩小为224,192,160,128。
3.5实验
作者随后做了实验权衡模型大小,速度和准确率。
首先比较了同样的结构使用和不使用深度可分离卷积。减少了许多倍的代价精度却仅仅只有一个点的损失。
为比较到底层数减少还是通道减少更好,作者把baselin中
14
×
14
×
512
14\times 14\times 512
14×14×512的五层移除并与
α
=
0.5
\alpha=0.5
α=0.5的模型进行比较,两者参数量和计算量相近 。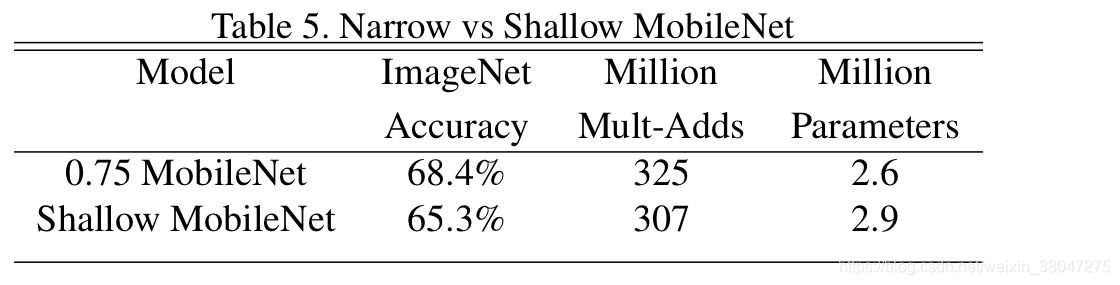
随后比较了两个超参数的影响。发现模型对输入分辨率不是十分敏感。
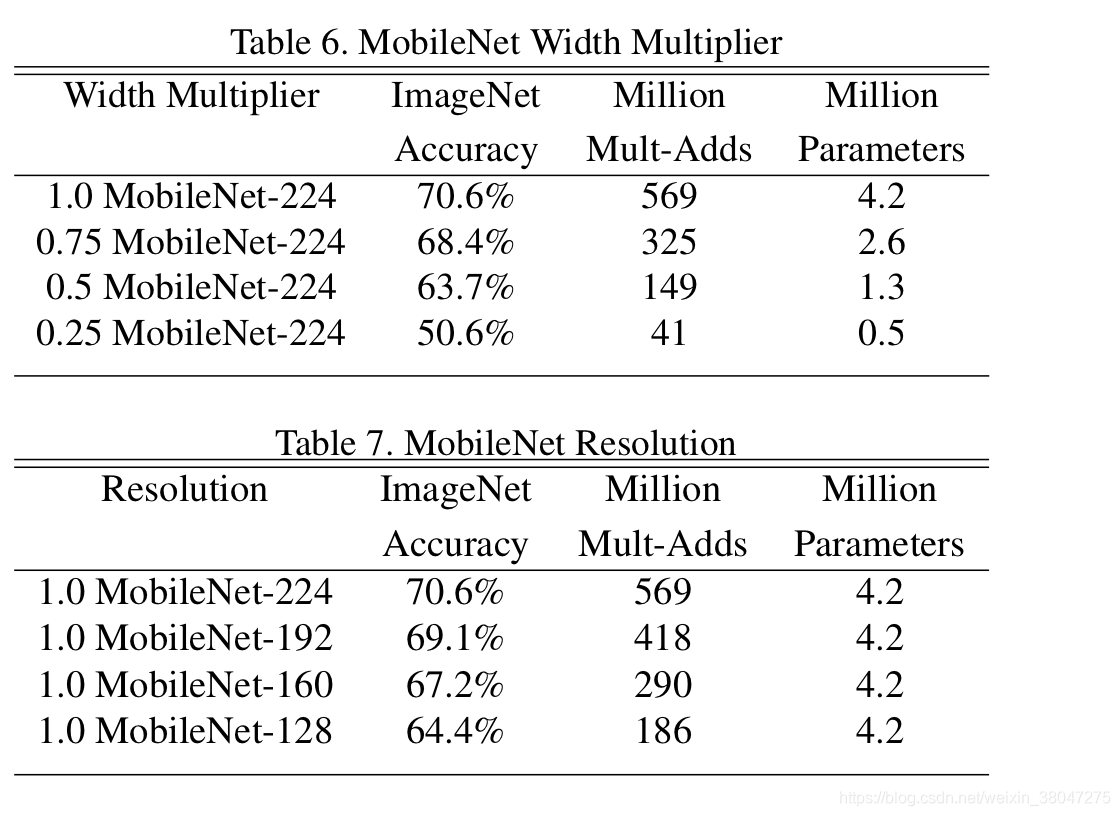
作者还与GoogLeNet,VGG16做了对比,MobileNet比GoogLeNet高一个点比VGG低一个点,但是计算量分别比他们少了32倍和27倍。又与其他的小模型对比,
α
=
0.5
\alpha=0.5
α=0.5的MobileNet就取得了精度和计算量的优势,SqueezeNet虽然参数量更少,但并未减少计算量。
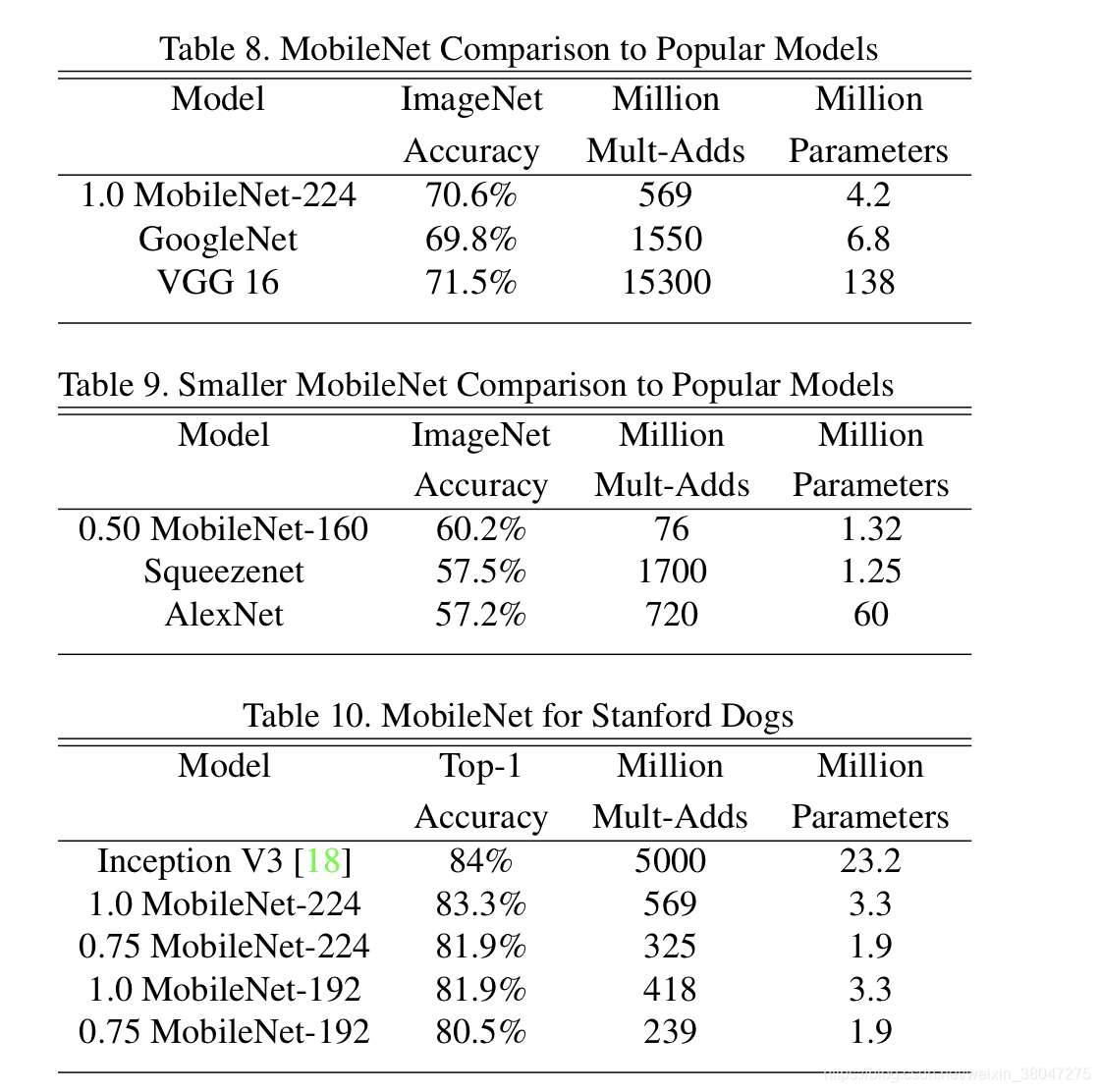
最后作者做了人脸,检测等方向的应用对比,详见原论文。
4.总结
MobileNet采用了深度可分离卷积的方法大幅度减少计算量和参数量,同时提供了两种超参数——宽度和分辨率来进一步减小模型。相比其他模型,MobileNet同时注重了模型大小和实际计算量,有保证准确率。
附
pytorch深度可分离卷积的实现非常简单。
class _conv_dw(nn.Module):
def __init__(self, inp, out, stride):
super(_conv_dw, self).__init__()
self.conv = nn.Sequential(
# depthwise
nn.Conv2d(inp, inp, 3, stride, 1, groups=inp, bias=False),
nn.BatchNorm2d(in),
nn.ReLU(inplace=True),
# pointwise
nn.Conv2d(inp, out, 1, 1, 0, bias=False),
nn.BatchNorm2d(out),
nn.ReLU(inplace=True),
)
self.depth = out
def forward(self, x):
return self.conv(x)














 5303
5303











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









