







Table of Contents
论文名:MobileNets: Efficient Convolutional Neural Networks for MobileVision Applications
下载地址:https://arxiv.org/pdf/1704.04861.pdf
正文
为了解决现有卷积神经网络模型因参数量大、计算量大而无法在移动端、嵌入式端应用的问题,Google提出了一个小且快的模型MobileNet,大幅度减小模型规模的同时保证模型性能下降很小。
1.原理解析
那么如何实现大幅度减小模型参数量的同时保证模型性能下降很小呢?一个很有用的trick就是分组卷积,而Mobilenet将分组卷积方法运用到极致,提出用深度可分离卷积(depthwise separable convolutions)。
深度可分离卷积
为什么说depthwise separable convolutions是分组卷积的极致运用呢?因为它将输入数据分成和通道数相等的组,每个组分别进行卷积处理,输入数据分组处理使得不同通道的特征相互独立(不同通道信息无法交流),所以还得想办法结合啊,这个时候就可以采用神奇1*1卷积来完成.
- depthwise conv:将输入数据的每个通道单独进行卷积处理(一般采用3*3的卷积核)
- pointwise conv:标准的1*1卷积,用于将depthwise conv的输出组合到一起
2.标准卷积和深度可分离卷积的比较
结构比较

上图中除了结构的不同外,还将激活函数由ReLU换成了ReLU6(论文给出的图片没有),据说该函数在float16/int8的嵌入式设备中效果很好,能较好地保持网络的鲁棒性。

参数和计算量比较
1.标准卷积

2.深度可分离卷积
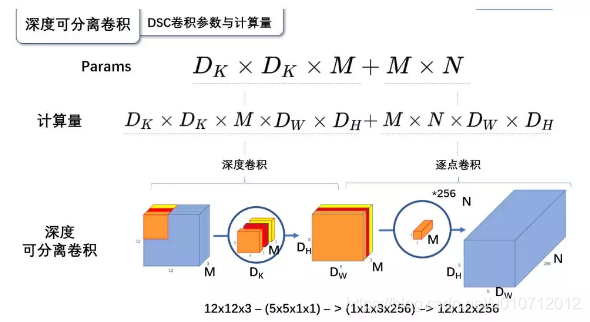
3.比较

参数和计算量的比较是参考这篇博客:https://blog.csdn.net/u010712012/article/details/94888053
3.网络结构
MobileNetV1
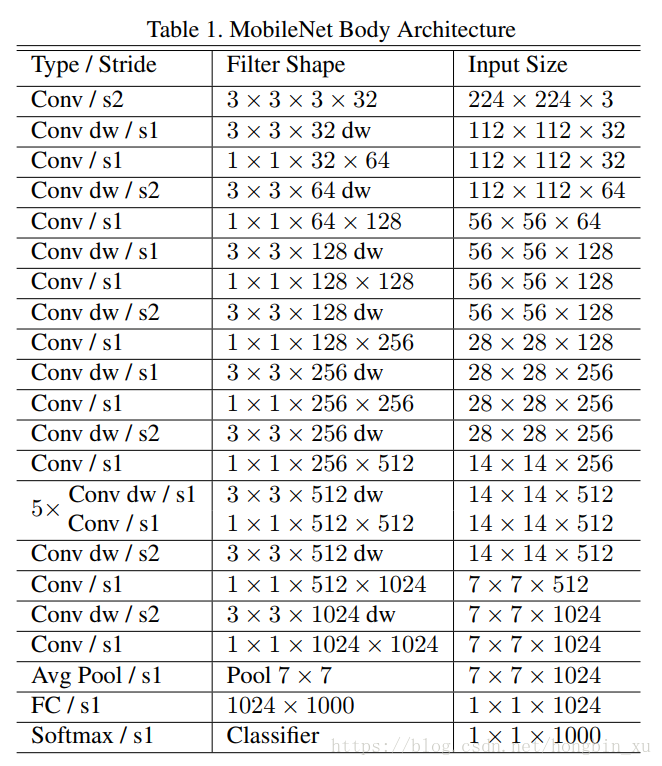
dw代表depthwise conv,且用stride2代替了pool操作。
注意:最后一个深度可分离卷积的stride应该为1,而不是图中的2,这样才能保证尺寸为7*7不变.
控制模型参数量的超参数
论文中为了能根据需求灵活的控制模型的大小,引入了两个超参数:
- Width Multiplier:用于控制特征图的维数即通道数(其实是控制卷积核的个数)
- Resolution Multiplier:用于控制特征图的尺寸即分辨率
3.MobileNetV1实现
mobilenet结构主要由多个深度可分离卷积构成
3.1 深度可分离卷积
# define DepthSeperabelConv2d with depthwise+pointwise
class DepthSeperabelConv2d(nn.Module):
def __init__(self, input_channels, output_channels, stride):
super().__init__()
self.depthwise = nn.Sequential(
nn.Conv2d(input_channels, input_channels, 3, stride, 1, groups=input_channels, bias=False),
nn.BatchNorm2d(input_channels),
nn.ReLU6(inplace=True)
)
self.pointwise = nn.Sequential(
nn.Conv2d(input_channels, output_channels, 1, bias=False),
nn.BatchNorm2d(output_channels),
nn.ReLU6(inplace=True)
)
def forward(self, x):
x = self.depthwise(x)
x = self.pointwise(x)
return x3.2 MobileNetV1整体结构实现
class MobileNet(nn.Module):
"""
Args:
width multipler: The role of the width multiplier α is to thin
a network uniformly at each layer. For a given
layer and width multiplier α, the number of
input channels M becomes αM and the number of
output channels N becomes αN.
"""
def __init__(self, width_multiplier=1, class_num=settings.CLASSES_NUM):
super().__init__()
alpha = width_multiplier
self.conv1 = nn.Sequential(
nn.Conv2d(3, int(alpha*32), 3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(int(alpha*32)),
nn.ReLU6(inplace=True)
)
self.conv2 = nn.Sequential(
DepthSeperabelConv2d(int(alpha * 32), int(alpha * 64), 1),
DepthSeperabelConv2d(int(alpha * 64), int(alpha * 128), 2),
DepthSeperabelConv2d(int(alpha * 128), int(alpha * 128), 1),
DepthSeperabelConv2d(int(alpha * 128), int(alpha * 256), 2),
DepthSeperabelConv2d(int(alpha * 256), int(alpha * 256), 1),
DepthSeperabelConv2d(int(alpha * 256), int(alpha * 512), 2),
DepthSeperabelConv2d(int(alpha * 512), int(alpha * 512), 1),
DepthSeperabelConv2d(int(alpha * 512), int(alpha * 512), 1),
DepthSeperabelConv2d(int(alpha * 512), int(alpha * 512), 1),
DepthSeperabelConv2d(int(alpha * 512), int(alpha * 512), 1),
DepthSeperabelConv2d(int(alpha * 512), int(alpha * 512), 1),
DepthSeperabelConv2d(int(alpha * 512), int(alpha * 1024), 2),
DepthSeperabelConv2d(int(alpha * 1024), int(alpha * 1024), 2)
)
self.avg = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Linear(int(alpha * 1024), class_num)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.avg(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x














 945
945











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









