







文章目录
前言
大家好,我是空空star,本篇给大家分享一下
《通过Python的pdfplumber库提取pdf中表格数据》。
一、pdfplumber库是什么?
pdfplumber是一个用于从PDF文档中提取文本和表格数据的Python库。它可以帮助用户轻松地从PDF文件中提取有用的信息,例如表格、文本、元数据等。pdfplumber库的特点包括:简单易用、速度快、支持多种PDF文件格式、支持从多个页面中提取数据等。pdfplumber库还提供了一些方便的方法来处理提取的数据,例如排序、过滤和格式化等。它是一个非常有用的工具,特别是在需要从大量PDF文件中提取数据时。
二、安装pdfplumber库
pip install pdfplumber
三、查看pdfplumber库版本
pip show pdfplumber
Name: pdfplumber
Version: 0.9.0
Summary: Plumb a PDF for detailed information about each char, rectangle, and line.
Home-page: https://github.com/jsvine/pdfplumber
Author: Jeremy Singer-Vine
Author-email: jsvine@gmail.com
License:
Requires: pdfminer.six, Pillow, Wand
Required-by:
四、提取pdf中表格数据
1.引入库
import pdfplumber
2.定义pdf文件路径
local = '/Users/kkstar/Downloads/'
3.打开pdf文件
with pdfplumber.open(local+"demo_table.pdf") as pdf:
4.获取pdf文件中的页数
num_pages = len(pdf.pages)
5.遍历每一页
for page_num in range(num_pages):
6.获取当前页内容
page = pdf.pages[page_num]
7.提取表格数据
table = page.extract_table(table_settings={
"vertical_strategy": "lines",
"horizontal_strategy": "lines",
"intersection_x_tolerance": 15,
"intersection_y_tolerance": 15
})
8.输出表格数据
for row in table:
print(row)
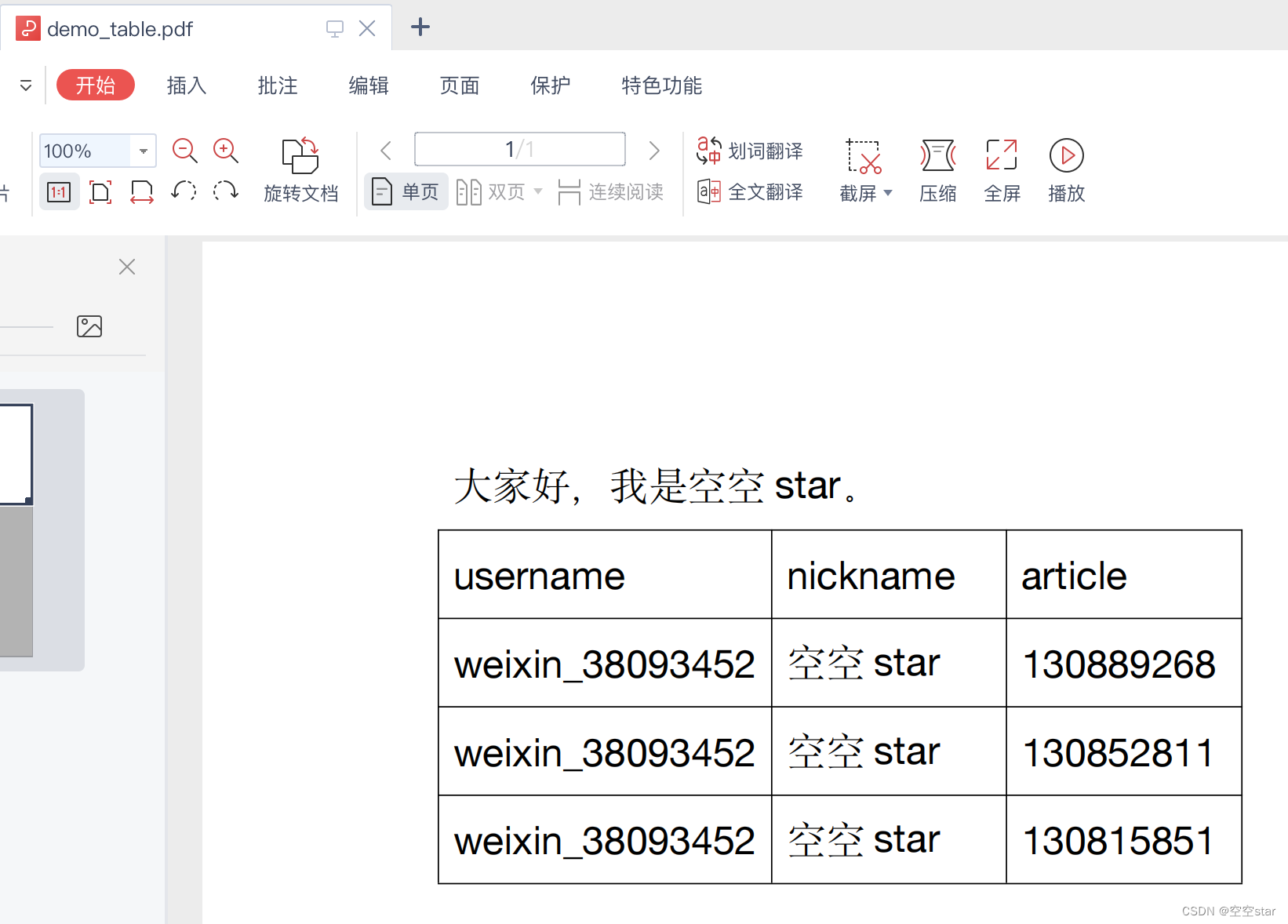
9.效果
[‘username’, ‘nickname’, ‘article’]
[‘weixin_38093452’, ‘空空 star’, ‘130889268’]
[‘weixin_38093452’, ‘空空 star’, ‘130852811’]
[‘weixin_38093452’, ‘空空 star’, ‘130815851’]
Process finished with exit code 0
















 4532
4532











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











