







论文笔记--InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning
1. 文章简介
- 标题:InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning
- 作者:Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi
- 日期:NeurIPS
- 期刊:2023
2. 文章概括
文章提出了一种基于指令微调的多模态语言模型InstructBLIP,模型提出了一种可将指令信息编码的Query Transformer,并在13个指令微调数据集上进行模型训练。模型在多个测试集上得到了SOTA表现,且实验表明基于InstructBLIP进行SFT的模型在多个下游任务上取得更好的表现。
3 文章重点技术
3.1 数据集构建
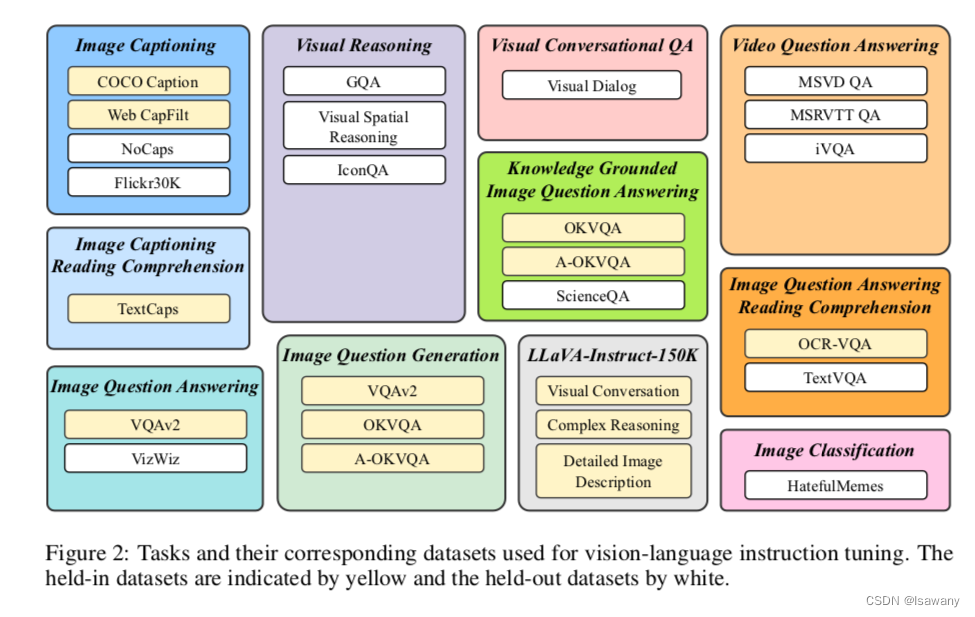
如下图所示,文章收集了来自11个任务的26个数据集,将其中13个数据集作为held-in datasets(图中黄色部分),将held-in datasets的training sets用于指令微调训练,将held-in datasets的dev/test sets用于held-in 评估;将另外13个数据集作为held-out datasets(图中白色部分),该部分数据又可进一步划分为1) 模型训练(held-in)未见过的数据&模型训练见过的任务类型 2)模型训练(held-in)未见过的数据&模型训练未见过的任务类型 ,后者的难度更大。
3.2 特征提取
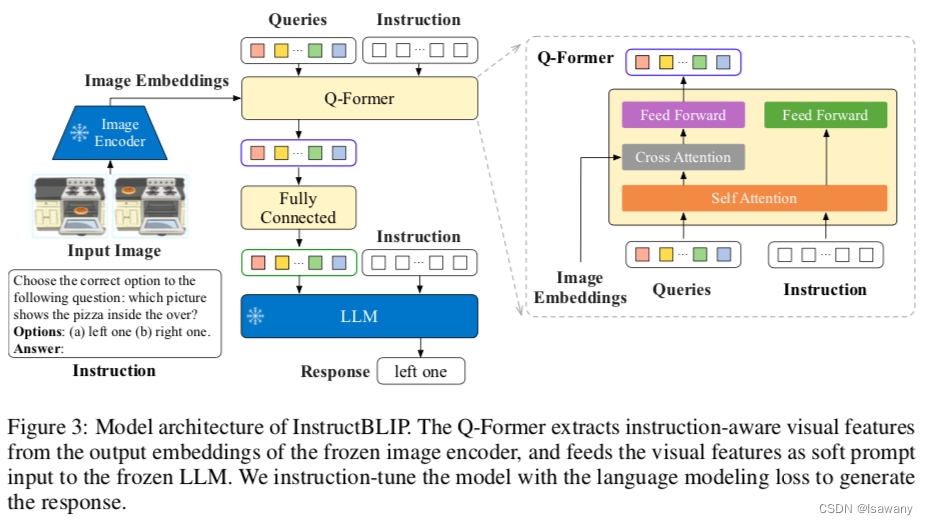
文章的整体算法框架基于BLIP-2模型。如下图左所示,BLIP-2使用了一个Query-Transformer模块:Q-Former 将(frozen) Image Encoder编码生成的视觉特征作为输入,将通过cross-attention模块得到编码后的视觉特征向量作为输出,Q-Former的输出再经过一个全连接层之后传入到一个(Frozen) LLM。
不同于BLIP-2,文章提出一种Instruction-aware 的特征提取方法,如下图右所示,Q-Former会同时将Instruction和Queries通过self-attention层交互得到指令相关的特征向量,再和图像编码进行cross attention。
3.3 数据平衡
为了使不同来源的数据尽可能平衡且不至于对小样本的数据集过拟合,文章提出下述采样方法:给定 D D D个数据集,每个大小分别为 { S 1 , … , S D } \{S_1, \dots, S_D\}
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









