







论文笔记--
1. 文章简介
- 标题:Gemini: A Family of Highly Capable Multimodal Models
- 作者:Gemini Team, Google
- 日期:2023
2. 文章概括
近日google发行的Gemini系列多模模型引发了业内的争相转发,该系列模型包含Ultra, Pro和Nano三种尺寸,分别适用于不同的预算和预期。该多模态模型在文本、图片、音频、视频等多个领域表现突出,特别地,Gemini Ultra是第一个在MMLU测评集上性能达成人类专家水平的模型。
3 文章重点技术
3.1 模型架构
Gemini模型基于Transformer解码器架构,支撑32K的上下文长度。Gemini家族包含Ultra/Pro/Nano三种尺寸的模型,其中Ultra表现最好,且在多个任务上达到了SOTA;Pro模型在多个任务上表现也很好,可在成本有限的情况下作为Ultra的替代品;Nano-1(1.8B)和Nano-2(3.25B)可支撑不同内存的on-device部署。具体如下表所示

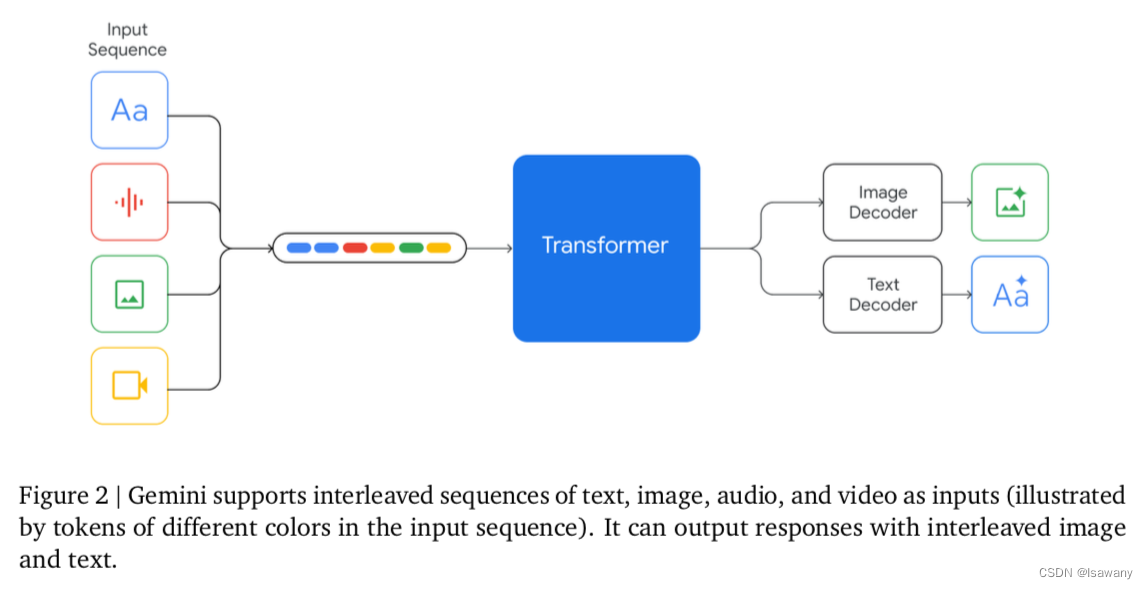
Gemini系列模型支持文本、图像和音视频交错的输入,支持输出文本和图像。如下图所示。其中图像部分的编码类似Google之前的Flamingo,CoCa和PaLI模型;Video的编码是通过将Video处理为祯的序列,然后采样序列进行编码得到输出。
3.2 训练数据
Gemini的训练数据来源包含网页、书籍、代码,数据类型包含图像、音频、视频等。文章首先利用启发式规则和基于模型的分类起对所有的数据集进行质量过滤,再通过安全过滤移除有害内容。文章通过在小尺寸模型上的数值实验得到最终的数据配比,再用相同的数据配比去训练大的模型。
3.3 模型评估
Gemini是一种多模态模型,故文章从文本 、图像、视频几个方面对模型进行了性能评估。
3.3.1 文本
文章对比了Gemini Pro/Ultra和一系列现存的表现较好的LLMs,评估结果见下表。可以看到,Gemini Pro的表现超过了GPT-3.5等大部分模型,Gemini Ultra的表现超过了所有的模型。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 734
734

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









