







论文笔记--kNN PROMPTING: BEYOND-CONTEXT LEARNING WITH CALIBRATION-FREE NEAREST NEIGHBOR INFERENCE
WITH CALIBRATION-FREE NEAREST NEIGHBOR INFERENCE)
1. 文章简介
- 标题:kNN PROMPTING: BEYOND-CONTEXT LEARNING WITH CALIBRATION-FREE NEAREST NEIGHBOR INFERENCE
- 作者:Benfeng Xu, Quan Wang, Zhendong Mao, Yajuan Lyu, Qiaoqiao She, Yongdong Zhang
- 日期:2023
- 期刊:ICLR
2. 文章概括
文章提出了一种kNN prompting的方法,解决了传统In-Context Learning(ICL)d中Context长度受限的问题,且可以充分利用大量标注样本进行推理。在文章测试的10个文本分类任务中,kNN prompting相比于ICL和calibration-based方法性能有了显著提升。
3 文章重点技术
3.1 In-Context Learning(ICL)
ICL的概念可参考博客[1]。这里只给出ICL的标准模型:给定标记训练数据集
T
=
{
(
x
i
,
y
i
)
}
\mathcal{T}=\{(x_i, y_i)\}
T={(xi,yi)},其中
y
i
∈
Y
y_i\in\mathcal{Y}
yi∈Y表示样本
x
i
x_i
xi的标签,给定LLM为
θ
\theta
θ,则ICL的任务是给定测试样本
x
t
e
s
t
x_{test}
xtest时,根据训练样本构建其prompt:
P
=
π
(
x
1
,
y
1
)
⊕
π
(
x
2
,
y
2
)
⊕
⋯
⊕
π
(
x
∣
T
∣
,
y
∣
T
∣
)
⊕
π
(
x
t
e
s
t
,
∗
)
P=\pi(x_1, y_1) \oplus \pi(x_2, y_2) \oplus \cdots \oplus \pi (x_{|\mathcal{T}|}, y_{|\mathcal{T}|})\oplus \pi(x_{test}, *)
P=π(x1,y1)⊕π(x2,y2)⊕⋯⊕π(x∣T∣,y∣T∣)⊕π(xtest,∗),其中
π
\pi
π表示verbalization操作,即将
x
,
y
x, y
x,y映射到其对应的标准prompt格式。比如
1
−
>
p
o
s
i
t
i
v
e
,
0
−
>
n
e
g
a
t
i
v
e
1-> positive, 0->negative
1−>positive,0−>negative或者
0
−
>
w
h
i
t
e
,
1
−
>
r
e
d
,
2
−
>
b
l
u
e
.
.
.
.
0->white, 1->red, 2->blue....
0−>white,1−>red,2−>blue....。下表是文章采用的一些prompt的样例:

模型学习到一个
y
∈
Y
y\in\mathcal{Y}
y∈Y:
y
^
t
e
s
t
=
arg max
y
∈
Y
(
v
∣
P
,
θ
)
=
arg max
y
∈
Y
(
π
(
y
)
∣
P
,
θ
)
.
\hat{y}_{test} = \argmax_{y\in\mathcal{Y}} (v|P, \theta) = \argmax_{y\in\mathcal{Y}} (\pi(y)|P, \theta).
y^test=y∈Yargmax(v∣P,θ)=y∈Yargmax(π(y)∣P,θ).
ICL满足大模型的幂律法则,也就是说,当标记数据
∣
T
∣
|\mathcal{T}|
∣T∣增大时,模型的性能也会提升。但ICL的一个劣势是需要将标记数据放在context中输入到LLM,而LLM一般的输入长度限制为1024或2048等,这就造成了我们只能使用一小部分的标记数据作为上下文。
3.2 kNN prompting
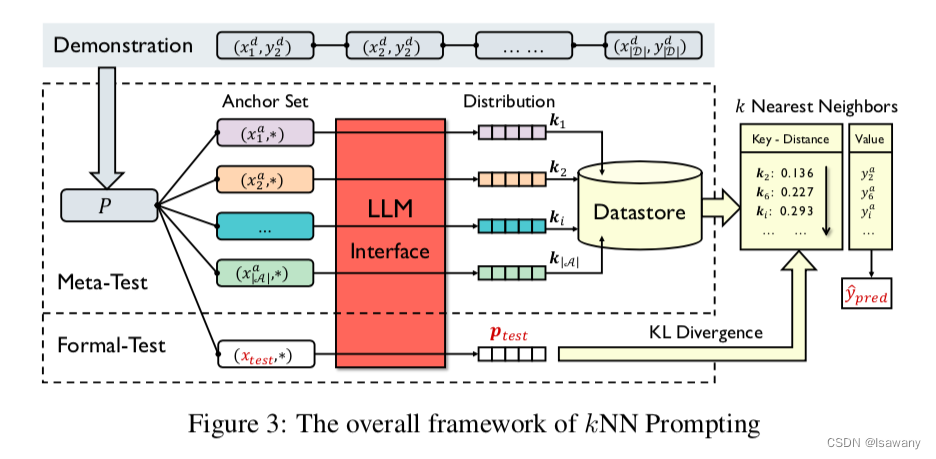
为了解决上述问题,文章提出了kNN prompting方法。给定训练集 T \mathcal{T} T,我们将其分为示范集(demonstration set) D \mathcal{D} D和锚集(anchor set) A \mathcal{A} A,如下图所示,kNN prompting分为两个阶段
- Meta Test:首先我们利用 A \mathcal{A} A中所有标记样本:对任意 ( x i a , y i a ) ∈ A (x_i^a, y_i^a)\in\mathcal{A} (xia,yia)∈A,我们将 x i a x_i^a xia和所有 D \mathcal{D} D中的标记样本组成prompt,得到prompt为 P i = π ( x 1 d , y 1 d ) ⊕ π ( x 2 d , y 2 d ) ⊕ ⋯ ⊕ π ( x ∣ D ∣ d , y ∣ D ∣ d ) ⊕ π ( x i a , ∗ ) P_i=\pi(x_1^d, y_1^d) \oplus \pi(x_2^d, y_2^d) \oplus \cdots \oplus \pi (x_{|\mathcal{D}|^d}, y_{|\mathcal{D}|}^d)\oplus \pi(x_i^a, *) Pi=π(x1d,y1d)⊕π(x2d,y2d)⊕⋯⊕π(x∣D∣d,y∣D∣d)⊕π(xia,∗),再将prompt放入LLM中得到一个分布 p ( v ∣ P i , θ ) p(v|P_i, \theta) p(v∣Pi,θ)。这里我们不将 y y y转化成 v v v,而是直接将 k i = p ( v ∣ P i , θ ) k_i = p(v|P_i, \theta) ki=p(v∣Pi,θ)缓存,记作key representation(KR)。从而我们构建出了一组 { k i , y i a } \{k_i, y_i^a\} {ki,yia}的数据库
- Formal Test:正式推理阶段,对每个测试样本
x
t
e
s
t
x_{test}
xtest,我们类似上面的公式构建prompt:
P
t
e
s
t
=
π
(
x
1
d
,
y
1
d
)
⊕
π
(
x
2
d
,
y
2
d
)
⊕
⋯
⊕
π
(
x
∣
D
∣
d
,
y
∣
D
∣
d
)
⊕
π
(
x
t
e
s
t
,
∗
)
P_{test}=\pi(x_1^d, y_1^d) \oplus \pi(x_2^d, y_2^d) \oplus \cdots \oplus \pi (x_{|\mathcal{D}|^d}, y_{|\mathcal{D}|}^d)\oplus \pi(x_{test}, *)
Ptest=π(x1d,y1d)⊕π(x2d,y2d)⊕⋯⊕π(x∣D∣d,y∣D∣d)⊕π(xtest,∗),并得到
p
t
e
s
t
=
p
(
v
∣
P
t
e
s
t
,
θ
)
p_{test} = p(v|P_{test}, \theta)
ptest=p(v∣Ptest,θ)。然后我们将此分布与数据库中所有分布进行KL散度比较:
D
K
L
(
p
t
e
s
t
∣
∣
k
i
)
=
∑
v
p
(
v
∣
P
t
e
s
t
,
θ
)
log
p
(
v
∣
P
t
e
s
t
,
θ
)
p
(
v
∣
P
i
,
θ
)
D_{KL}(p_{test}||k_i) = \sum_v p(v|P_{test},\theta)\log \frac {p(v|P_{test},\theta)}{p(v|P_i,\theta)}
DKL(ptest∣∣ki)=v∑p(v∣Ptest,θ)logp(v∣Pi,θ)p(v∣Ptest,θ)。然后得到
x
t
e
s
t
x_{test}
xtest对应的预测输出为
y
^
p
r
e
d
=
arg max
y
∈
Y
∑
t
∈
N
N
k
(
p
t
e
s
t
,
K
)
1
(
y
i
1
=
y
)
\hat{y}_{pred} = \argmax_{y\in\mathcal{Y}} \sum_{t\in NN^k(p_{test}, \mathcal{K})} \mathrm{1}(y_i^1=y)
y^pred=y∈Yargmaxt∈NNk(ptest,K)∑1(yi1=y),其中
N
N
k
(
∗
,
K
)
NN^k(*, \mathcal{K})
NNk(∗,K)表示测试分布的
k
k
k个近邻。翻译下上式,简单来说先计算当前分布和历史所有分布的KL散度,找到最近的
k
k
k个分布,这
k
k
k个分布对应的类别最多的即为预测值。
4. 数值实验
文章将kNN prompting和ICL、Calibration-based方法进行了比较,发现kNN prompting显著提高了baselines。可能原因为
- kNN prompting信息使用更充分:使用了全部的标记样本
- 多个标签的单词之间彼此竞争可能会影响传统ICL判断。
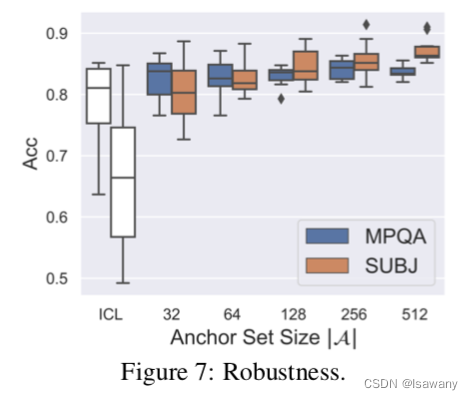
此外,数值实验表明,kNN prompting显著提高了prompt方法的鲁棒性:
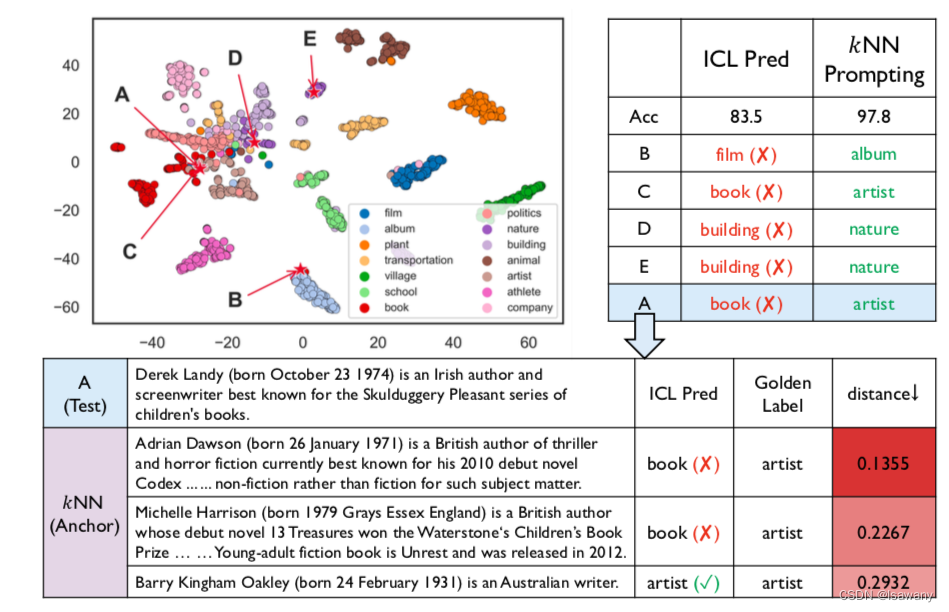
最后,文章通过t-SNE将得到的数据进行可视化。如下图所示,LLM学习到的分布并不总是按照标签聚类的,这使得ICL有一定的概率预测错误。如下表中的样本A,真实标签为artist,但ICL预测其为book。但通过kNN prompting得到它的三个近邻标签均为artist,从而可NN prompting给出了artist的正确标签。
4. 文章亮点
文章提出了kNN prompting,将标记样本的LLM分布缓存,在推理阶段获得与测试样本分布的KL散度最接近的k个近邻,将近邻中最多的分类作为预测结果。kNN prompting解决了ICL受context长度限制的问题,充分利用了标记数据,且提升了ICL的鲁棒性。
5. 原文传送门
kNN PROMPTING: BEYOND-CONTEXT LEARNING WITH CALIBRATION-FREE NEAREST NEIGHBOR INFERENCE
6. References
[1] 论文笔记–Learning To Retrieve Prompts for In-Context Learning















 2090
2090

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









